
From Dev to Prod: a ML Pipeline Reference Post
This post provides an overview (10 mins) & reference for how to build a full end to end machine learning (ML) Pipeline – feature engineering, training, and inference – with Hamilton, from dev to prod.



Introduction
This post is broadly about using Hamilton to deal with all the challenges of building a ML Pipeline. We hope you’ll learn something from this post independent of whether you adopt Hamilton or not (Part I requires no knowledge of Hamilton).
What is Hamilton? Hamilton is a lightweight library that helps you standardize how code is written and can be used to express many different use cases, e.g. data processing, feature engineering, machine learning (ML), large language model (LLM) workflows, web-service request processing, etc. Therefore there are multiple reference architectures/patterns; this post is the first in a series. Specifically, in this post we’ll focus on end-to-end machine learning pipelines and what some reference architecture/patterns might look like using Hamilton, with some comparisons to alternatives.
Value Assumption. You should care about/want at least one of the following:
iterating on pipelines quickly.
getting from development to production quickly.
being able to repeat (b) quickly with something already in production and without production outages.
applying software engineering best practices to data & machine learning work easily.
developing a modular and maintainable “ML platform”.
Post structure. We’ll split this post into two parts. The first will be a high-level overview, something that you can read to get a sense of the moving parts as well as the benefits of using Hamilton for ML pipelines. This is what you can read in one sitting. The second part will be longer and more technically in depth, and is more of a reference on when to use certain constructs — we don’t expect you to read that part in a single sitting.
Vocabulary. We use the term “pipeline” as a synonym for extract transform load (ETL), workflow, flowchart, dataflow, and directed acyclic graph (DAG).
Familiarity with Hamilton. We assume basic familiarity with Hamilton for the more technical parts of this post. If you are not familiar, we suggest you to take 15 minutes and do a few of the exercises found at https://www.tryhamilton.dev/. It’s an in-browser interactive way (that works on mobile) to grok the basics of how Hamilton works and how you approach writing code. However for Part I you should be able to get by without it.
Familiarity with Machine Learning. We also assume that you’re familiar with machine learning, and will not take time to explain the what & why of it.
The Software Engineering Challenge with ML Pipelines
Before we begin, it’s useful to mention the challenges that one encounters with ML Pipelines. Google famously released a paper that highlighted the fact that you engineer a lot more than just the machine learning code itself to get a ML pipeline up and running, if you’re serious about it being core to your business. That’s because machine learning pipelines require inputs that change over time (data, features, models), and produce a lot of outputs (telemetry, predictions, models) that need to integrate with various systems and enable inspection to determine health.

That means when building and maintaining ML pipelines, you need to contend with a variety of decisions:
How do I monitor data (inputs, intermediate values, outputs)?
How do I integrate a monitoring system? Which one do I choose?
Where do I store my models? What about my data? What formats?
What system do I use to execute my code?
Where do I emit lineage information?
How do I reuse components or prior pipelines? (e.g. features, models)
What should my pipelines consist of? (e.g. data ingestion, featurization, model fitting, etc?)
These decisions and more impact how one writes code. Usually these questions are tackled one at a time, one after the other as the need arises. Unless you have a lot of experience and know how to design for these concerns from the beginning, the code base for a pipeline starts to resemble esoteric spaghetti code unique to the author who wrote it – don’t believe me? Ask yourself, do you like inheriting someone else’s pipelines? For 90+% of people the answer is no – and it’s precisely for the aforementioned reason.

This is where Hamilton comes in, its goal is to standardize how your pipelines are expressed so that all of these decisions and questions are much faster and simpler to implement and maintain, without the software engineering background typically required (if you do have the software engineering background, we think you will appreciate more what we’re doing!). A successful byproduct of this is that more people can call themselves Machine Learning Engineers 😉!
Part I: High-level Overview of Hamilton for ML Pipelines
There is nothing complex about building an ML pipeline in python. You just write python functions. The function names and their input arguments define how the pipeline is stitched together (i.e. executed in the right order) by Hamilton. In this section we’ll go over using Hamilton at a high level without diving into the full functionality offered by Hamilton; part II will go deeper.
To start, let’s do something very simple. Here is a linear chain of three steps expressing a hello world ML Pipeline (pull data, fit a model, and use it to predict) that runs anywhere you run python:
# --------- simple_model_pipeline.py
from sklearn import datasets
from sklearn import svm
import pandas as pd
def digits_df() -> pd.DataFrame:
digits = datasets.load_digits()
_digits_df = pd.DataFrame(digits.data)
_digits_df["target"] = digits.target
return _digits_df
def digits_model(digits_df: pd.DataFrame) -> object:
clf = svm.SVC(gamma=0.001, C=100.)
_digits_model = clf.fit(digits_df.drop('target', axis=1), digits_df.target)
return _digits_model
def predicted_digits(
digits_model: object,
input_digits: pd.DataFrame) -> pd.Series:
return pd.Series(digits_model.predict(input_digits))
# And the driver code to run it:
# ---------- run.py
from hamilton import driver
import simple_model_pipeline
dr = driver.Builder().with_modules(model_pipeline).build()
input_digits = pd.DataFrame(...) # pull some data from somewhere
result = dr.execute(["predicted_digit"],
inputs={"input_digits": input_digits})
# do something with the result!Explanation:
We request
predicted_digitas an output. Hamilton will then figure out the correct sequence of functions to call to compute it. Hamilton only computes what’s required to produce a result.The driver calls
digits_df().Then passes the result into
digits_model()Then passes the fit model, along with the input_digits to
predicted_digits().
Note: for `input_digits` here we load it outside the “pipeline definition”, i.e in `run.py`, and pass it in via `inputs=`. Alternatively, we could have written a function with the name `input_digits` that loaded that data and removed the need to provide it as input to execute. This highlights one of the general design decisions you’ll make - you can pass values in, or write functions, (or have the option to do both if you use `overrides=`).

dr.display_all_functions().Note, the code here can be executed in any python context. Jupyter notebooks, python web-services, PySpark, or within systems like Airflow, Dagster, etc. We can do this because Hamilton is very lightweight and just needs a python process to run in.
In these next few sections we’ll compare Hamilton to other tools, show how one would describe a larger ML Pipeline in Hamilton than the one above, and close out Part I discussing the benefits of using Hamilton.
Hamilton versus other tools
Hamilton is likely very different from other tools you’ve encountered, unless you’re familiar with DBT (Hamilton can be viewed as “DBT for Python”). Hamilton’s focus is on standardizing code so that testing, documentation, and lineage are first class concepts. Because of this standardization, you have a much simpler time connecting and composing what you wrote in Hamilton with everything else. For a more in depth technical write up (that is slightly dated) we direct you to our two VLDB workshop papers [Workshop on Composable Data Management Systems, Workshop on Data Ecosystems].
To help explain the difference in how a pipeline is described, let’s contrast the above code and what it would look like with heavy-weight systems such as Airflow, Dagster, Prefect, etc.:

As you can see, with these other tools you:
need to explicitly annotate functions to describe what they are.
still need to manually describe what the pipeline actually is.
importantly wouldn’t use them during development; you can’t run the code in a jupyter notebook for example. They aren’t just libraries.
would not be able to reuse the code here in other contexts because it is not portable. For example, you would not be able to place them within a spark job, or FastAPI web service, or simply use the code you wrote to build a library for reuse elsewhere.
At a high level this is how Hamilton compares to other pipeline tools:

One point to emphasize is that Hamilton does not replace tools like Airflow, Dagster, etc. It is not an entire system like those pipeline frameworks are. In fact, Hamilton is very complimentary with them, and is commonly used to standardize the code within them (see Airflow blog, Prefect blog).
Using Hamilton to describe and run a ML Pipeline
To describe a ML Pipeline in Hamilton, you write python functions that describe what happens and how things connect. Thus, the design choices required to describe a ML pipeline boil down to:
The name of the python function – this declares what you can get out of a pipeline. Python functions commonly have `verbs` for names, in Hamilton they become `nouns`. E.g. “
data_set”.What the python function input arguments are. These declare what dependencies the function needs. E.g. to create a model we need a data set.
What goes on in the body of the python function is completely up to your discretion. Whether you do a lot of things in one function, or only one thing, is up to you. E.g. do we perform model fitting and prediction in the same function, or do we split them out? Hamilton isn’t opinionated here.
Therefore, to describe a ML Pipeline in Hamilton, we just need to have a picture of the steps that we want in our pipeline. From there we curate those steps into functions and into modules. Then when we want to execute the “pipeline” we pass the right modules to the Driver (which orchestrates execution), and specify what we want to execute from the “pipeline”. This leads to code and a pipeline that is “standard” in the sense of how it is constructed and connected together. No matter the author, the construction approach will be the same. This standardization itself well to code inheritance, because one can always make heads-or-tails of the code in front of them, as well as collaboration and integration with other systems because all “pipelines” are exercised in the same manner.
Let’s discuss some common steps and how you’d express them in Hamilton. We’ll show the most basic way to describe them, and point readers to Part II for more details. Note we make no assumption on whether you develop code in a notebook or an IDE; you can develop Hamilton however you write python code.
Data Ingestion.
In the simplest terms, you declare a function with a name that describes the data you ingest. This function could declare as input a location, or it could be a JDBC driver for database connections, or nothing at all! What you then do in the body is up to you. You could load a CSV file, make an HTTP request, or perform a DB query, etc.
# data_loading.py
def raw_data_set(location: str) -> pd.DataFrame:
"""Loads our data set from a CSV file."""
return pd.read_csv(location)Data Processing/Normalization.
After data ingestion you might need to perform transforms such as joining, sorting, filtering, or normalizing data. To do this, again you’d just declare a function, and this time ensure that one of the function input arguments (the data to normalize) matches the name of the function from data ingestion to connect the two.
# data_loading.py
def normalized_data_set(raw_data_set: pd.DataFrame, ...) -> pd.DataFrame:
"""Processes raw data set"""
_df = ... # your logic here
return _dfFeature Engineering.
In Hamilton, the inputs and outputs of functions can be whatever data type you want. This means that for feature engineering you can choose to operate over “columns” of a data frame, or the whole data frame itself. Which one you choose depends on what type of reusability and introspection you’d like. Here we present two approaches.
Approach (1) using Data Frames:
# features.py
def featurized_data_set(
normalized_data_set: pd.DataFrame, ...) -> pd.DataFrame:
"""Creates featurized data set with feature transforms contained in the function."""
_df = normalized_data_set.assign(
derived_feature=lambda x: x.a_raw_feature * ...)
# more feature transforms
return _dfApproach (2) thinking in “columns”:
# features.py
@extract_columns("a_raw_feature", "another_column", ...)
def input_data_set(normalized_data_set: pd.DataFrame) -> pd.DataFrame:
"""This function helps us expose the columns we want for individual feature transform fuctions"""
return normalized_data_set
def derived_feature(a_raw_feature: pd.Series, ...) -> pd.Series:
"""derived_feature feature definition"""
return a_raw_feature * ...
# more transforms would be defined
def featurized_data_set(normalized_data_set: pd.DataFrame, derived_feature: pd.Series, ...) -> pd.DataFrame:
"""This function defines what goes into our featurized data set"""
return pd.concat(
[normalized_data_set, derived_feature, ...], axis=1)
The reason to choose the latter approach is to ensure testing, modularity, reusability, and visibility – which gains importance as your feature set starts to grow. While the former is probably good enough to get started, the transition from the former to the latter is straightforward and can be done at a later date.
Model Training.
Much like the functions above, there is nothing special here. You write a function and declare what it needs. In the body you employ whatever modeling frameworks you like to train a model.
# model_pipeline.py
def trained_model(featurized_data_set: pd.DataFrame, target: pd.Series, ...) -> "model":
"""Trains a model based on the featurized data set."""
_model = some_framework.fit(featurized_data_set, target: pd.Series)
# any other logic
return _modelIf you wanted to split the data into multiple sets or perform hyper parameter tuning, etc. you can do so in this function, or split the process out into multiple discrete functions. Hamilton doesn’t dictate what you can do here, it just helps you keep things well organized and curated into functions.
Model Prediction & Evaluation.
After training a model it is common to evaluate it. Here’s a simple function expressing that. Recall that functions can produce whatever data types we want — in this case we return a dictionary to encapsulate multiple metrics.
# model_pipeline.py
def predictions_and_evaluation(trained_model: "model", some_data_set: pd.DataFrame, some_labels: pd.Series) -> dict:
"""Exercises the model on the given data set and evaluates it"""
_predictions = trained_model.predict(some_data_set)
_eval = some_evaluation(_predictions, some_labels)
return {"predictions": _predictions, "eval": _eval}If you log to places like MLFlow, ModelDB, or Weights and Biases, you can do so in the code here as well.
Running the pipeline.
The above code would be curated into one or more python modules (i.e. files). Let’s say we organized the functions into thematic modules (in the earlier example we just had it all in one module), and then constructed a pipeline from them. To do so we’d just run something like the following code:
from hamilton import driver
# import the modules
import data_loading, features, model_pipeline
dr = (
# declare the driver and what the pipeline is to be built from
driver.Builder()
.with_modules(data_loading, featurization, model_pipeline)
.build()
)
# specify what outputs we want from the pipeline
outputs = ["trained_model", "predictions_and_evaluation"]
result = dr.execute(
outputs,
inputs={"location": ..., "target": ..., ...}
)This code instructs Hamilton to create a pipeline, or in a more technical term a directed acyclic graph (DAG), from the functions defined in the three modules passed into it. From the pipeline we defined, we then tell Hamilton what outputs we want from it, and Hamilton will then determine the path of execution to get those outputs.

Note: Hamilton will only run the parts of the pipeline required to satisfy the outputs. For example, if we just wanted to produce the featurized data set, we could ask for just that and it would not compute the model fitting or evaluation functions, e.g. result = dr.execute([“featurized_data_set”], inputs={..}).
From Development to Production.
How and where you run the Hamilton pipeline is up to you. You need to provide the python process and instantiated driver to kick off execution. In development this might be a notebook cell, in production an Airflow python operator, within Dagster a function, or even an endpoint within a python web-service. It is precisely this portability that lends itself to enabling a quick transition between code written in development to production (more on this in Part II).
To qualify the code/pipeline for production – with Hamilton:
you can always unit-test your code (it’s just functions!)
you can easily integration test certain paths of the pipeline, without having to deal with mock gymnastics.
you have a great documentation story, as function naming and function documentation strings provide a standardized place for people to add extra detail.
you get provenance/lineage via code, and when paired with a version control system, you have the ability to easily version, rollback, compare, and debug changes to the pipeline that happen over time.
Artifact Tracking & Monitoring.
For tracking artifacts, Hamilton provides no native facility, other than provenance/lineage as defined through code. Hamilton does, however, provide you the ability to integrate with your favorite tools directly within the body of functions. For a more platform approach, one can inject “materializers” and “adapters”, into a pipeline, helping keep it modular and nimble. These patterns delineate the logic of a pipeline itself from “platform concerns” such as whether to use MLFlow, Neptune, or an in-house framework. For monitoring, Hamilton has functionality such as runtime data quality checks (using a simple python function annotation @check_output) out of the box, as well as common integrations (datadog, open telemetry, and open lineage are in the works), as well as hooks to enable you to extend components for your own monitoring needs. More on all of this in Part II. If you want an off-the-shelf solution that provides lineage, catalog, observability, and monitoring functionality you can use a paid solution like DAGWorks Platform that just requires a one-line change to integrate!
The Next Pipeline Iteration.
It is common to forget that code needs to be changed and updated, or that new pipelines created are variants of existing ones. Most pipeline authoring tools assume you only write things once, which is almost never the case (cynic: why does their documentation not talk about this aspect?). Hamilton provides a straightforward path to change/reuse and modify prior work. For example, if we were to build a new model pipeline, we can reuse the existing code where it makes sense, and surgically change the parts that don’t, thereby speeding up development velocity.
For example, you’re migrating between Azure and GCP and need to change how data is loaded, but want to keep both ways around and separate python dependencies where it makes sense. Easy — create a new data_loading module implementing the same/similar functions as before and then plug it into your pipeline. You can then switch between what’s run by importing the correct module. The downstream components shouldn’t need to change.
import gcp_data_loading # or import azure_data_loading
import featurization, model_pipeline
dr = (
driver.Builder()
# plug in the right module for the right context
.with_modules(gcp_data_loading, featurization, model_pipeline)
.build()
)
result = dr.execute(...)Or, you may want to add a new feature and build a separate model to A/B test against your existing one. Easy — add the new feature logic, then add configuration driven logic to switch out the right feature set. To achieve this, we could pass in a value to the featurized_data_set function directly and have `if else statements` but that pattern, while quick, leads to messy and coupled code (code only ever grows more complex overtime). Instead, with Hamilton, we have a very clear separation of logic via the `@config.when` decorator, so we could do something like:
@config.when(model_feature_version="v1")
def featurized_data_set__v1(normalized_data_set: pd.DataFrame, ...) -> pd.DataFrame:
"""Features for V1 model"""
_df = normalized_data_set.assign(
derived_feature=lambda x: x.a_raw_feature * ...)
# more feature transforms
return _df
@config.when(model_feature_version="v2")
def featurized_data_set__v2(normalized_data_set: pd.DataFrame, some_other_dependency: ...) -> pd.DataFrame:
"""Features for V2 model -- this can have different dependencies than V1!"""
# add different feature transforms from V1
_df = normalized_data_set.assign(
derived_feature=lambda x: 2 * x.a_raw_feature * ...)
_df = _df.assign(new_feature=lambda x: x.derived_feature * ...)
return _dfIn the new pipeline, we create the driver and pass in configuration:
import data_loading, featurization, model_pipeline
dr = (
# declare the driver and what the pipeline is to be built from
driver.Builder()
.with_modules(data_loading, featurization, model_pipeline)
.with_config({"model_feature_version": "v2"}) # add config value
.build()
)Boom — a brand new model pipeline! We’ve reused most of the prior logic, and because it looks very similar to before, the mechanism to get this to production doesn’t need much updating. For follow-on iterations and subsequent code deletions, Hamilton makes it much clearer to review code changes (it’s just changes to functions) and understand impacts to the pipeline (did you add, remove, or change a dependency?), no matter the author.
Benefits of Using Hamilton in ML Pipelines
Hopefully a picture is now beginning to form for you on how Hamilton standardizes how code is written and thus how pipelines are structured. It is precisely from this standardization that Hamilton’s benefits arise.
Technical Benefits - a great software engineering story
Part of the problem with the software engineering of machine learning pipelines is that you can make the same choice in very different ways. This is what leads to code and pipeline nightmares (the “data maze” as illustrated above). Hamilton, on the other hand, helps constrain some of this state space by design and is what you trade-off to achieve standardization. You could come up with your own standards, but then you’re stuck maintaining them – wouldn’t it be better to depend on something open source to amortize maintenance and de-risk your standardization efforts? In viewing Hamilton’s technical benefits, you have to ask yourself, what would you rather? Would you rather have bespoke solutions to maintain, or standardize on an open source approach? Would you rather a wild west anything goes approach, or a clear prescribed way to change and iterate on code & pipelines? Would you rather have separate development versus production code paths and patterns, or a tool you can use for development and production? I’m sure that for most readers, you’d choose the latter options in a business setting.
Specifically, Hamilton enables a great software engineering story for your machine learning pipelines because:
You can port, plug and extend your code and the framework.
Hamilton runs anywhere that python runs. You can reuse the same code, and then easily extend the framework – we’ll substantiate this more in the next section.
You can version, debug & understand faster with lineage as code.
With the code that one writes also expressing how the pipeline works, then using `git` allows a simple mechanism to version a pipeline. Then when things change, the ability to (a) visually display the code path, and (b) methodically debug functions leads to a much faster time to resolution of problems that occur.
You have naturally modular and reusable code, without much thought.
There are no object oriented constructs to understand or extend. All that’s required is to write functions and group them into modules. Then to reuse, swap, or extend the code/pipeline, you just need to to satisfy the declared function dependencies. All this comes without extra engineering work on your part, and is straightforward enough that non-software engineers can understand.
You never need to complain again about testing & documentation.
Code is always unit testable with Hamilton – that is by design. Integration testing is similarly straightforward because it’s easy to inject data, change functions, and test specific code paths. Functions also always have readable names and documentation strings that help one understand what the code does. With the in-built visualization, one always has up-to-date documentation to help get personnel up to speed quickly.
It works for any data size.
Hamilton works for small or big data, and has integrations with popular frameworks that scale computation and process large data sets, like pyspark, ray, and dask. More on this in the next section.
It’s not all or nothing.
Other frameworks require an all or nothing implementation to be useful. However because Hamilton runs anywhere that python runs, you can incrementally adopt Hamilton for bits and pieces of existing pipelines and receive benefits for just those pieces that Hamilton is implemented in. So there really isn’t an excuse not to give Hamilton a try because the work would be well encapsulated and scoped; a common starting point is feature engineering.
Business/Operational Benefits - get more ML done

Delivering machine learning in a business involves cycles, or loops. It's not a straight piece of a race track that you drive exactly once. The world isn’t static, neither is your business. You want to be able to complete the loops or cycles as fast as possible given the resources available to you. Here, loops and cycles are a proxy for improving (or keeping) model performance, which are proxies for improving (or continuing) business outcomes. To mechanically get around a loop or cycle, software engineering needs to occur. Because Hamilton standardizes the software engineering aspects, it stands to reason that you can get your loops/cycles done not only more quickly and consistently over time, but also without the heavy software engineering skill set requirement. The consistently over time part is important, since if we’re leaning into our car racing analogy, that’s what wins the race (which is a proxy for your business outcompeting another), and not who could drive the fastest lap. Reducing the need for a heavy software engineering skill set enables teams to be leaner and skew to better modelers which is easier to staff for (in our experience).
Therefore with Hamilton more specifically, we’re enabling individuals and teams to complete these loops/cycles more quickly and consistently without a heavy software engineering skill set requirement. From a business perspective this translates to an increased return on investment (ROI) for ML initiatives. Upon adopting Hamilton, one team at Stitch Fix became 400% more productive at a time-consuming monthly model update task, as Hamilton standardized what needed to be done, giving them a methodical and repeatable way to be confident in getting a change out to production. More generally, junior personnel can get more done themselves, without the technical debt they’d usually incur. Hand-off and inheritance is faster because code follows a standard structure. Production issues can be found and diagnosed sooner leaving more time for differentiating work. Platform Teams can be more efficient and leverage Hamilton’s integrations and structures without having to build it all themselves.
Part I Summary
In this first part, the point was to show how a ML Pipeline would look in Hamilton, compare Hamilton to other approaches, and present the value you gain from using it. In the next section, we’ll dive into more of the software engineering constructs that Hamilton has to build ML Pipelines that work for the size and complexity of your needs and particular context.
Part II: A Deeper Dive into Hamilton for ML Pipelines
This section will not be an exhaustive deep dive into all that Hamilton has to offer, but the point will be to highlight a few Hamilton patterns that make building and maintaining a ML pipeline simpler and faster, so bookmark this page for reference. We will try to point out what is useful and when, so that you can choose the simplest route based on your needs. We know ML Pipelines are not a one size fits all. This is a long section — so skim to the parts desired.
This section is especially relevant for individuals that want a deeper understanding of some of Hamilton’s capabilities, such as architects, team decision makers, and ML Platform/MLOps folks, We’ll be going into more detail on how to use and customize Hamilton for your particular efforts. For a more dated, but still largely relevant writeup on the core of Hamilton, one can read our VLDB workshop papers [Workshop on Composable Data Management Systems, Workshop on Data Ecosystems].
Mental note (1): it’s all a Directed Acyclic Graph
Before we start, one major point to grok is that if you can visualize your pipeline as a flow chart, i.e. a directed acyclic graph (DAG), you can map it to Hamilton code. Think about that for a second. If you can draw it out, that’s how the structure of the code will look. Building off of that, the constructs that we’ll show can thus be thought of as augmentations to a DAG, be it removing, injecting, or replacing nodes or subsections of the DAG, or even reusing and parameterizing parts of the DAG.
Mental note (2): Hamilton is functional programming lite
Most software engineering approaches to ML pipelines involve creating classes and objects to which you attach methods to, which you then exercise. Something like the following:
def MyClass(SomeInterface):
def __init__(self, data_loader: SomeLoader, query: str, ...):
self.data_loader = data_loader
self.query = query
self.model = LRModel()
def preprocess(self, ...):
# preprocess data
self.data = self.data_loader(self.query)
self.data = self.some_internal_transform(data)
def featurize(self, ...):
# featurizes data
self.data = ...
...
# and then
m = MyClass(...)
m.preprocess(...)What a class represents is state, and methods functions that operate over that state. This gets messy once you add inheritance and delegation to the mix as determining what is going on (to understand/debug/add a new method/remove old ones) often becomes a nested Russian doll traversal through a code base. You do this because you want to reuse/share/centralize various parts of your code base… Instead, with Hamilton, it’s kind of the inverse. You first write functions that take in objects and output a new or mutated object. Then to extend what’s going on, you add more functions that take in objects and output a new object(s). The net result is that objects are only really concerned with state - they’re simpler. While the functions concern themselves only with computational logic that is straightforward to find and trace, over the objects (state) that is passed round. I call Hamilton functional programming lite, since the core logic one writes can be written to mirror most functional programming principles but not all of them.
Mental note (3): What Hamilton doesn’t care about
It is worth noting explicitly that Hamilton:
Does not really care about data types.
It uses them to statically validate dependencies in the graph, and then ensure inputs to the graph match declared types. That’s about it. So you’re free to integrate and use Hamilton with whatever types (custom or third party) you want.
Does not care about data size.
You’re still in control of the data that you operate over, Hamilton isn’t opinionated here. You can use Hamilton for small data sets to large ones that run on Spark for example. Hamilton works just the same. That also means Hamilton does not care about data types. We use Pandas in our examples here because it’s the most common dataframe library used.
Does not care about Python dependencies.
It’s still up to you to control python dependencies in the environment that you execute Hamilton within. Hamilton is not opinionated about how you do that, we actually observe it helps a team settle on common dependencies faster because they all collaborate more on the same codebase. But, if different parts of your pipeline need different versions of, say, Tensorflow, you need to execute those parts separately, and ensure that when the code runs you have the right dependencies for executing the right part of the pipeline.
Building an ML pipeline with Hamilton: A deeper guide
We’ll walk through similar sections to those we had in Part I, but show a few more patterns and constructs that could be appropriate for that particular section and suggest the appropriate times to use them. We’ll start from the simplest implementations and work to explain why you might use a more advanced construct. We will show code snippets where appropriate. If a construct is applicable to multiple sections we show it once, and reference it later.
Data ingestion & data preparation:
Simple case. Let’s build off of our example from earlier that loads and normalizes data.
# ------ data_loading.py
def raw_data_set(location: str) -> pd.DataFrame:
"""Loads our data set from a CSV file."""
return pd.read_csv(location)
def normalized_data_set(
raw_data_set: pd.DataFrame, ...) -> pd.DataFrame:
"""Processes raw data set"""
_df = ... # your logic here
return _dfPro-tip:
Do as much joining, filtering, normalizing, sorting, and creating a common index (if using something like pandas) in this part of the code. The reason to do this here is that, should data schemas change, you can limit required code changes to just this part of the code base. Typically this is also where data engineering and data science meet to collaborate, and Hamilton helps provide a clear structure and contract to make that collaboration crisp and clear.
Dealing with differing data sources (e.g. dev vs prod).
It’s not uncommon to have different data sources in different environments/contexts. How do we deal with them here? `if else` statements are one option – keeping it all in one function, but that pattern falls apart when the paths start to take on different dependencies and needs. If one comes from an object oriented (OO) paradigm, you’d subclass or pass in different object that meets some interface. With Hamilton we offer both approaches as flavors — see if you can spot which is which.
Option 1: Write two different functions and decorate them with @config.when.
When functions are decorated with @config.when, they will only appear in the pipeline if the appropriate configuration is passed in. This is akin to our `if else` statement. See how we have two functions – one for development, and the other to load from a database in production. Note the `__` to help keep the function names unique in the module. Hamilton will strip this so that only one `raw_data_set()` will be in the pipeline.
# ------ data_loading.py
from hamilton.function_modifiers import config
@config.when(env="dev")
def raw_data_set__dev(location: str) -> pd.DataFrame:
"""Loads our data set from a CSV file."""
return pd.read_csv(location)
@config.when(env="prod")
def raw_data_set__prod(db_client: object) -> pd.DataFrame:
"""Loads our data set from a production DB. Note the different argument."""
return pd.read_sql("SELECT * FROM db.table", con=db_client)
def normalized_data_set(raw_data_set: pd.DataFrame, ...) -> pd.DataFrame:
"""Processes raw data set -- doesn't care where it came from."""
_df = ... # your logic here
return _df
# ----- run.py things would then look like this:
dr = (
# declare the driver and what the pipeline is to be built from
driver.Builder()
.with_config({"env":"prod"}) # choose the right one.
.with_modules(data_loading, featurization, model_pipeline)
.build()
)
result = dr.execute([...], inputs={"db_client": MySQLClient(...)})We would pass in the right configuration to the driver, which can change the inputs required for execution. In the code above, we’d need to pass in a db_client if using prod as the value. If using dev, we’d need to pass in a location string value.
Option 2: Write two different python modules and swap them at driver construction time.
This choice makes sense if the python dependencies are wildly different, or there are a lot of @config.when functions that make a single module unwieldy. Our example above would look as follows:
#-------- data_loading_dev.py
def raw_data_set(location: str) -> pd.DataFrame:
"""Loads our data set from a CSV file."""
return pd.read_csv(location)
#-------- data_loading_prod.py
def raw_data_set(db_client: object) -> pd.DataFrame:
"""Loads our data set from a production DB. Note the different argument."""
return pd.read_sql("SELECT * FROM db.table", con=db_client)
#-------- run.py
import importlib
...
if env == "prod":
import data_loading_dev as data_loading
else:
import data_loading_prod as data_loading
# or programmatically import it:
# data_loading = importlib.import(f"data_loading_{env}")
dr = (
# declare the driver and what the pipeline is to be built from
driver.Builder()
.with_modules(data_loading, ...)
.build()
)In `run.py`, (as shown above), we would have some logic to pick the right module to provide to the Hamilton Driver, or perhaps two different run.py scripts, one for each context. Note: we can import modules with `importlib`, versus having to have a direct import, so we can programmatically script which modules are utilized.
How do I centralize loading logic/hide platform concerns?
What if you have special security or credential requirements? Or perhaps you don’t want the logic that loads the data to have “platform” dependencies in it, so you can more easily update things without touching a lot of code? Or you want to hide data format details so that Data Scientists don’t need to worry about them? For example, perhaps you’re on Snowflake now, and might move to Databricks later on. When you migrate, you’d ideally want to minimize code changes you make. To help, Hamilton has a facility for you called `data adapters`, which can be extended and augmented for your needs. Hamilton comes with a variety of them out of the box for loading data to and from various formats. They leverage a public API that you can extend. So, let’s change the database example above to operate in the hypothetical case where one needs to do some custom validation/credential checking. We will annotate `raw_data_set()` with `@load_from.prod_db(query=source("query"))` that will inject a Dataframe from the result of the query we wired into it. The magic for how this happens is in the DataLoader class registered under `prod_db`.
#-------- data_loading.py
from hamilton.function_modifiers import load_from, source
def query() -> str:
return "SELECT * FROM db.table"
@load_from.prod_db(query=source("query"))
def raw_data_set(raw_data: pd.DataFrame) -> pd.DataFrame:
"""raw_data comes is now the result of the load_from annotation"""
return raw_data
#-------- loaders.py
from hamilton.io.data_adapters import DataLoader
@dataclasses.dataclass
class ProdDBDataLoader(DataLoader):
"""Our custom data loader that can centralize various bits of logic"""
query: str
@classmethod
def applicable_types(cls) -> Collection[Type]:
return [pd.DataFrame]
def load_data(self, type_: Type) -> Tuple[dict, Dict[str, Any]]:
username = os.environ["username"]
# do some check with our credentials/auth system here
auth_check(username, query)
return pd.read_sql(self.query, con=DBClient(...))
@classmethod
def name(cls) -> str:
return "prod_db" # this is what goes after the @load_from
#-------- run.py
import loaders, data_loading
from hamilton.registry import register_adapter
register_adapter(loaders.ProdDBDataLoader) # register the adapter
dr = (
# declare the driver and what the pipeline is to be built from
driver.Builder()
.with_modules(data_loading, ...)
.build()
)So in the above example we just centralized how data is loaded in `ProdDBDataLoader`. This class has a few methods to implement, two class methods and one instance method. The class methods help (a) ensure that Hamilton type checks that it can operate on the graph: `applicable_types()` specifies what function parameter types it can load into to, (b) `name()` is what we will use to register this adapter and in the code call it (@load_fron.VALUE_OF_NAME). While the instance method `load_data()` contains our logic for our specific needs. You could change a lot of the details of that method, and the only change people would need to make is to pull in the latest code for it to work. So for a hypothetical move from Snowflake to Databricks, if you centralized the loading logic, the change could be more seamless/much less burdensome than if people directly integrated the data loading into their code. This works because we’ve contained all the implementation in an adapter class. The only key point to note is that the adapter class needs to be registered before use so that Hamilton knows about it.
How do I catch bad schemas/data early?
A lot of ML Pipeline issues stem from data changes that invalidate assumptions the code/model was made with. Hamilton has a runtime data quality check capability via `@check_output` that can simplify your pipeline by displacing the need for systems like Great Expectations. It is always best to catch errors as early as possible in a pipeline, so in our above example we could set expectations on the data loaded using a Pandera schema:
#-------- data_loading.py
import pandera as pa
from hamilton.function_modifiers import check_output
schema = pa.DataFrameSchema({
"name": pa.Column(pa.Str),
"height": pa.Column(pa.Int),
...
})
@check_output(schema=schema, importance="fail")
def raw_data_set(location: str) -> pd.DataFrame:
"""Loads our data set from a CSV file."""
return pd.read_csv(location)Without having to modify the Driver code, we now have added a runtime data quality check to our pipeline. The definition lives with our code, enables us to enforce and check values, custom attributes, etc, without a separate system to update or maintain. This check is efficient because the data is already loaded, so there is no need to re-pull! This is notably different from other data quality systems that run after the fact and have to reload data and are therefore more expensive to run and maintain. If you’ve heard the term “shift left”, you’re looking at it right here, since we can add this check in development and naturally take it to production.
But I already have an existing data quality system.
Don’t worry, we’ve got you covered. Hamilton also has facilities to extend `@check_output` and the ability for you to write your own custom implementation with `@check_output_custom` – so if you are already using a data monitoring system you can build an integration that calls out to that system (i.e. vendor) instead. We’re still writing more documentation here so reach out if this is of interest.
I have data governance/compliance requirements.
When you tell governance folks that a ML pipeline built with Hamilton inherently provides full provenance and lineage of how data is transformed – which is usually black box to them – their ears perk up. To help facilitate this you can attach metadata to your functions, and then query for it/ask questions! For example, if we wanted to mark some data set as containing PII we could do the following with the @tag decorator (see tutorial):
from hamilton.function_modifiers import tag
@tag(PII="name,height")
@load_from.prod_db(query=source("query"))
def raw_data_set(raw_data: pd.DataFrame) -> pd.DataFrame:
"""raw_data comes is now the result of the load_from annotation"""
return raw_dataAll that we’ve done is add extra metadata to the graph. What you do with it is up to you. For example, one common pattern is to access it via an instantiated driver – we could ask whether we have any PII in our pipeline, and if so, what models are downstream of the PII data:
dr = driver.Driver(
{}, data_loading, feature_engineering, model_pipeline)
pii_nodes = [var.name for var in dr.list_available_variables()
if var.tags.get("PII") is not None]
print(pii_nodes)
downstream_models = set([m for m in dr.what_is_downstream_of(n.name)
if "model" in m.name for n in pii_nodes])
print(downstream_models)One could conceivably push this information to their data governance/compliance solution in a CI system, or when Hamilton is executed in the appropriate environment.
Some other blogs relevant to data loading/preparation:
Separate data I/O from transformation -- your future self will thank you.
Expressing PySpark Transformations Declaratively with Hamilton
Feature Engineering
It’s not always true that your feature pipeline will be the same as your model training pipeline. Hamilton works for both cases. You usually start with everything in one pipeline, and then as iterations, team size, and data grows, you split the two out so they can run and be iterated on separately. With Hamilton you can keep one logical pipeline, and can later choose to only run one part of it at a time!
Simple-ish case.
Let’s assume we’ve outgrown doing feature engineering in one function and instead write our feature transforms, where it makes sense, out as individual functions.
# ---------- features.py
from hamilton.function_modifiers import extract_columns
@extract_columns("a_raw_feature", "another_column", ...)
def input_data_set(normalized_data_set: pd.DataFrame) -> pd.DataFrame:
"""This function helps us expose the columns we want for individual feature transform fuctions"""
return normalized_data_set
def derived_feature(a_raw_feature: pd.Series, ...) -> pd.Series:
"""derived_feature feature definition"""
return a_raw_feature * ...
# more transforms would be defined
def featurized_data_set(normalized_data_set: pd.Series, derived_feature: pd.Series, ...) -> pd.DataFrame:
"""This function defines what goes into our featurized data set"""
return pd.concat(
[normalized_data_set, derived_feature, ...], axis=1)Let’s walk through some constructs that we can add as our needs evolve. Note - @extract_columns is syntactic sugar here to make it easy to expose columns in dataframe, rather than writing a function to expose them each individually.
I have feature transforms that differ only slightly.
It’s common to have features that differ by some input value, for example in time-series forecasting. In Hamilton we have the ability to write a parameterized function that then produces more functions to keep your code DRY-er, by utilizing the `@parameterize` decorator (see tutorial). For example, if we wanted to multiply some_column by several values we could write the following:
# ---------- features.py
from hamilton.function_modifiers import parameterize, value
@parameterize(
feature_1={"value_to_parameterize": value(1)},
feature_10={"value_to_parameterize": value(10)},
...
)
def base_multiply(some_column: pd.Series, value_to_parameterize: int, ...) -> pd.Series:
"""Multiplies some_column by {value_to_parameterize}."""
return some_column * value_to_parameterizeNot only can we parameterize by scalar values (see value()), but we also can parameterize over the output of other functions (see source()), or both:
# ----------- features.py
from hamilton.function_modifiers import parameterize, source, value
@parameterize(
feature_1_1={"col_param": source("feature_1"),
"value_to_parameterize": value(1)},
feature_2_10={"col_param": source("feature_2"),
"value_to_parameterize": value(10)},
...
)
def base_multiply(col_param: pd.Series, value_to_parameterize: int, ...) -> pd.Series:
"""Multiplies {col_param} by {value_to_parameterize}."""
return col_param * value_to_parameterizeIf you’re starting to use @parameterize, your next thought might be is what I’m passing into it configuration or code? We’ve seen people over optimize and try to make something “configuration”, when in fact they treat it the same as code, i.e. it requires a PR to merge changes and a new build to be pushed out. So our advice here, is put most things into code, until you have a good case to make it truly “configuration”. If you end up needing what you pass into parameterize to be “configuration”, i.e. passed in at driver construction time, take a look at using `@resolve` (we show an example using it below).
Python Tip: you don’t need to construct the values within the `@parameterize` decorator itself. Instead you can place that outside and pass in values by **.
I want to reuse features in my online/streamed setting.
Different data in training versus production can be a real problem for delivering ML in a business. One reason is that it can be hard to reuse the same code paths in training and inference time because for training you’re doing things in batch, while at inference time you perform your transformations in a web service or streaming context. Hamilton has a prescribed path here. Because you curate your feature transform logic into a python module, it is easy to version, package, and ship it. Using using Hamilton constructs, you can take just the parts of the feature pipeline that make sense and reuse them in another context.
You can utilize decorators like `@config.when` (see prior section, or this tutorial) to pass in/query precomputed aggregates, rather than computing them on the fly. You can plug in a different data loading module (see dealing with different data sources above) that loads from a feature store and reuses the same feature transform logic.
In lieu of showing code examples (as we’ve covered these constructs already), I direct you to our write once, run anywhere post should you want to dive deeper.
I want more dynamism in choosing my feature set for model fitting.
Hamilton’s general approach is to have as much as possible explicitly expressed in code. This is good if you want a prescribed change management process driven by writing code and pushing it out (e.g. GitOps). In certain situations, however, you want to be able to construct a data set dynamically without having to write code and push it. For this case we have some powerful decorators to combine together. Say we want to dynamically choose the features that should be input into our dataset for model training. We can achieve that by combining `@resolve` with `@inject`. `@resolve` allows you to change the value of a decorator based on configuration input to construct the pipeline. `@inject` allows you to group N inputs into a single function parameter value. So featurized_data_set() could now look like:
# -------- features.py
from hamilton.function_modifiers import resolve, ResolveAt, inject, group, source
@resolve(
when=ResolveAt.CONFIG_AVAILABLE,
decorate_with=lambda features: inject(
features=group(
**{feature_name: source(feature_name)
for feature_name in features}
)
),
)
def featurized_data_set(
features: dict[str, pd.Series]) -> pd.DataFrame:
_df = pd.concat(features.values(), axis=1)
_df.columns = list(features.keys())
return _df
# ------- run.py
from hamilton import driver
import data_loading, features, model_pipeline
dr = (
driver.Builder()
.with_config({"features": ["a_raw_feature", "derived_feature", ...]}) # features here
.with_modules(data_loading, featurization, model_pipeline)
.build()
)To execute this pipeline we now need to specify as configuration the features we want in our feature set for model fitting. How it works is that @resolve will use the configuration passed in, and run the lambda. To exercise the lambda, Hamilton will pass the value for the dictionary key “features” to it — so the name of the lambda variable matters here. The lambda will then create an @inject decorator with the appropriate feature values (using source() & group()). This might look intimidating, but you can hide this in your own python decorator (we can provide examples if you need help).
Some other blogs relevant to feature engineering:
Model Training & Model Inference & Model Evaluation
I’m grouping these sections together because they both produce a bunch of artifacts, e.g. metrics, the model itself, plots, etc. and thus will share similar constructs.
In terms of the code that you write, Hamilton is not opinionated about what modeling or evaluation frameworks you use at all. Nor is it opinionated about how you capture and store data such as model evaluation metrics, serialized models themselves, etc. It does, however, make it much simpler to avoid coupling these types of “non-differentiating” concerns from the logic itself. They’re non-differentiating because they’re auxiliary to running a model pipeline.
Let’s walk through the a simple approach, and discuss common things you’d integrate with, how they might evolve, and what Hamilton offers to help with that evolution. For example, I’ll show how you can reuse a section of a model pipeline that is agnostic to the data passed through it to fit multiple models.
Our simple starting point.
Here’s a very simple model fitting and eval pipeline – two functions:
# ----------- model_pipeline.py
def trained_model(featurized_data_set: pd.DataFrame,
target: pd.Series, ...) -> "model":
"""Trains a model based on the featurized data set."""
_model = some_framework.fit(featurized_data_set, target: pd.Series)
# any other logic
return _model
def predictions_and_evaluation(trained_model: "model",
some_data_set: pd.DataFrame,
some_labels: pd.Series) -> dict:
"""Exercises the model on the given data set and evaluates it"""
_predictions = trained_model.predict(some_data_set)
_eval = some_evaluation(_predictions, some_labels)
return {"predictions": _predictions, "eval": _eval}This is straightforward. As your needs grow (e.g. adding more models, integrating other tools like MLFlow, etc.), these two functions might not cut it. Here are some patterns that illustrate what you could change and how.
How do I add something like MLFlow to track?
It’s common to want to store things about model fitting: loss per epoch, the model itself, & training evaluation metrics being a few basic things.
Option 1: Directly integrate within the function
# ---------- model_pipeline.py
def trained_model(featurized_data_set: pd.DataFrame,
target: pd.Series, ...) -> "model":
"""Trains a model based on the featurized data set."""
with mlflow.start_run(run_name=”name”) as run:
_model = some_framework.fit(
featurized_data_set, target: pd.Series)
mlflow.framework.log_model(_model, …)
mlflow.log_metrics(...)
# any other logic
return _modelThis works, but now you’re tightly coupled with MLFlow. Making a change/migration is harder to do systematically, and your pipeline is now dependent on MLFlow to run at all. If this is the extent of your code, however, then this is probably fine, or at least a good place to start.
Option 2: Use Materializers (aka DataSavers)
Hamilton provides the ability to append “leaf” nodes to the pipeline at execution time. This means you can inject a concern, like saving to MLFlow at runtime, and only inject it (and the right parameters) in a context in which it makes sense to use MLFlow. If someone doesn’t need MLFlow, they should be able to run without it. So what do we need from our code to leverage a Materializer? (1) our trained_model function should return the outputs that we want to track. We use `@extract_fields` as syntactic sugar to expose what’s in the dictionary returned. (2) We create an MLFlow materializer (DataSaver), and (3) we change from using .execute() in our driver to .materialize().
# -------- model_pipeline.py
from hamilton.function_modifiers import extract_fields
#(1)
@extract_fields(
{"trained_model": object, "metrics": dict, ..., "params": ...})
def trained_model_and_metrics(featurized_data_set: pd.DataFrame,
target: pd.Series, ...) -> dict:
"""Trains a model based on the featurized data set."""
_model = some_framework.fit(featurized_data_set, target: pd.Series)
# any other logic , e.g. compute metrics
_metrics = {"mae": mae, "mse": mse, "rmse": rmse, "r2": r2}
return {"trained_model": _model,
"metrics": _metrics, ..., "params": ...}
# --------- adapters.py
from hamilton.io.data_adapters import DataSaver
@dataclasses.dataclass
class MLFLowSaver(DataSaver):
"""Our MLFlow Materializer"""
experiment_name: str
run_name: str
artifact_path: str
model_type: str = "sklearn"
@classmethod
def applicable_types(cls) -> Collection[Type]:
return [dict]
@classmethod
def name(cls) -> str:
return "mlflow"
def save_data(self, data: Any) -> Dict[str, Any]:
# Initiate the MLflow run context
with mlflow.start_run(run_name=self.run_name) as run:
# Log the parameters used for the model fit
mlflow.log_params(data["params"])
# Log the error metrics that were calculated
mlflow.log_metrics(data["metrics"])
# Log an instance of the trained model for later use
ml_logger = getattr(mlflow, self.model_type)
model_info = ml_logger.log_model(
sk_model=data["trained_model"],
input_example=data["input_example"],
artifact_path=self.artifact_path
)
return model_info # return some metadata
# ---------- run.py
import adapters
from hamilton.registry import register_adapter
register_adapter(adapters.MLFLowSaver) # register the adapter
...
dr = (
# declare the driver and what the pipeline is to be built from
driver.Builder()
.with_modules(data_loading, featurization, model_pipeline)
.build()
)
#(2)
# create the MLFlow materializer --
# it depends on "trained_model_and_metrics"
mlflow_materializer = to.sklearn_mlflow(
id="mlflow_sink",
dependencies=["trained_model_and_metrics"],
experiment_name="exp_name",
run_name="run_foo",
artifact_path="save/to/path"
)
# specify the additional outputs we want from the pipeline
outputs = ["trained_model", "predictions_and_evaluation"]
#(3)
materializer_results, results = dr.materialize(
mlflow_materializer,
additional_vars=outputs,
inputs={"location": ..., "target": ..., ...}
)We have (a) centralized how people save to MLFLow; (b) made it so that anyone who creates a model and wants to log it to MLFlow follows the same pattern; (c) enabled bypassing MLFlow logging simply by changing run.py (and not touching the model code itself) (d) made it possible to log the model to multiple places, (e.g. if we’re migrating systems), by just add a second materializer and keeping the rest of the code the same, so that Hamilton will exercise both of them! 🤯 right?
General patterns for saving “artifacts” to your systems of choice.
In general, the patterns are:
Couple it within a Hamilton function. This could also be a separate downstream function. See first part of the example above.
Use a Materializer with
.materialize()on the driver. See second part of the example above.Use the @save_to annotation – which is isomorphic to (2) – on a function, and then request it as output via `.execute()`. We skip describing it here in this post.
Which one you choose depends on your context. We suggest starting simple and then moving to materializers once you need to centralize some logic.
Note: Materializers also support a “combine” argument. This allows them to depend on the output of multiple functions, and the role of the combiner is to make a single object for the materializer to consume. See documentation here for more information. Otherwise here's our relevant blog on the topic of I/O.
You can find a list of materializers that are available to use/extend here.
How do I just exercise prediction with an already fit model?
You might have a whole prediction and evaluation pipeline, and want to use a prefit/previously trained model for inference evaluation. What are some approaches with Hamilton?
Option 1: Use overrides=.
At execution time, you can pass in a prior value and have it override and short circuit anything upstream of it. Thus you could do the following:
# run 1 -- save result/have it in memory
result = dr.execute(
["trained_model", ...],
inputs={"location": ..., "target": ..., ...}
)
# change something -- re-run, and override `trained_model`
result2 = dr.execute(
["predictions_and_evaluation"],
inputs={...},
overrides={"trained_model": result["trained_model"]}
)Option 2: use @config.when to load the model.
Another way would be to encode a path in the pipeline that doesn’t train a model, but instead loads one. You can achieve this via @config.when, and then specifying the right configuration and input to the driver. Note that @config.when enables you to change the inputs of a node — in the case below we only require featurized_data_set if use_existing is set to False.
# -------------- model_pipeline.py
@config.when(use_existing="False")
def trained_model__new(featurized_data_set: pd.DataFrame,
target: pd.Series, ...) -> "model":
"""Trains a model based on the featurized data set."""
_model = some_framework.fit(featurized_data_set, target: pd.Series)
# any other logic
return _model
@config.when(use_existing="True")
def trained_model__existing(model_path: str) -> "model":
"""Loads a model -- this could load from MLFlow too. Or have an @load_from decorator on top."""
with open(model_path, "rb") as f:
_model = pickle.load(f)
# any other logic
return _model
# --------------- run.py
...
dr = (
driver.Builder()
.with_config({"use_existing": "True"})
.with_modules(data_loading, featurization, model_pipeline)
.build()
)
outputs = ["predictions_and_evaluation"]
result = dr.execute(
outputs,
inputs={"model_path": ..., "target": ..., ...}
)Option 3: Inject the model using a DataLoader via .materialize().
This process can be thought of as another way to override something in the pipeline, by using a DataLoader. To tie into our earlier example, we could write a MLFlow loader that injects a model saved to MLFlow into the pipeline, instead of training a new one.
# --------- adapters.py
from hamilton.io.data_adapters import DataLoader
@dataclasses.dataclass
class MLFLowLoader(DataLoader):
model_uri: str
model_type: str = "sklearn"
@classmethod
def applicable_types(cls) -> Collection[Type]:
return [object]
def load_data(self, type_: Type) -> Tuple[object, Dict[str, Any]]:
loader = getattr(mlflow, self.model_type)
model = loader.load_model(model_uri=model_info.model_uri)
return model, {} #
@classmethod
def name(cls) -> str:
return "mlflow"
# ---------- run.py
import adapters
from hamilton.registry import register_adapter
register_adapter(adapters.MLFLowLoader) # register the adapter
from hamilton.io.materialization import from_, to
...
dr = (
# declare the driver and what the pipeline is to be built from
driver.Builder()
.with_modules(data_loading, featurization, model_pipeline)
.build()
)
model_uri = ... # get it from somewhere
# create the MLFlow loader --
# it will inject the value as "trained_model"
mlflow_loader = from_.sklearn_mlflow(
id="mlflow_loader",
model_uri=model_uri,
target="trained_model"
)
# specify the additional outputs we want from the pipeline
outputs = ["predictions_and_evaluation"]
materializer_results, results = dr.materialize(
mlflow_loader,
additional_vars=outputs,
inputs={"target": ..., ...}
)As you can see, you can do things a few different ways with Hamilton. What it really boils down to is (a) what code do you want to touch to make such a change, (b) what dependencies (as in python environment) do you want and where.
How do I create multiple models in the same pipeline?
Option 1: Write more functions.
If you’re adding a new model type, or a variant, you could just encode that in a new function.
# ------------ model_pipeline.py
def trained_model(featurized_data_set: pd.DataFrame,
target: pd.Series, ...) -> "model":
"""Trains a model based on the featurized data set."""
_model = some_framework.fit(featurized_data_set, target: pd.Series)
# any other logic
return _model
def other_trained_model(featurized_data_set: pd.DataFrame,
target: pd.Series, ...) -> "model":
"""Trains a model based on the featurized data set using ..."""
_model = some_other_framework.fit(
featurized_data_set, target: pd.Series)
# any other logic
return _model
def predictions_and_evaluation_model1(
trained_model: "model",
some_data_set: pd.DataFrame,
some_labels: pd.Series) -> dict:
"""Exercises the trained_model on the given data set and evaluates it"""
_predictions = trained_model.predict(some_data_set)
_eval = some_evaluation(_predictions, some_labels)
return {"predictions": _predictions, "eval": _eval}
def predictions_and_evaluation_model2(
other_trained_model: "model",
some_data_set: pd.DataFrame,
some_labels: pd.Series) -> dict:
"""Exercises the other_trained_model on the given data set and evaluates it"""
_predictions = other_trained_model.predict(some_data_set)
_eval = some_evaluation(_predictions, some_labels)
return {"predictions": _predictions, "eval": _eval}This means, however, that for evaluation or downstream consumers of your model, you need to provide uniquely named downstream versions of those functions. This is why we have a second evaluation function above. This may or may not be desirable. It’s good to be explicit where it matters.
Option 2: create agnostic model fitting logic and use @subdag.
Hamilton allows you to reuse parts of the pipeline within the pipeline itself. This sub part is termed subdag, for sub directed acyclic graph. Say we want to fit many types of models, but the process for fitting and evaluation is the same, we could then write a pipeline that’s agnostic, and then reuse it, by connecting it with the values we want it to run over. We skip over model_fitting.py here, and instead focus on the subdag part.
# ----- model_fitting.py
# contains our functions for fitting, evaluation, etc.
# see https://github.com/DAGWorks-Inc/dagworks-examples/blob/main/machine_learning/components/model_fitting.py
# see the image below of what is being parameterized
# ----- model_pipeline.py
from hamilton.function_modifiers import subdag, source
import model_fitting
@subdag(
model_fitting, # module to build subdag from
inputs={
"data_set": source("data_set_v2"),
},
config={"clf": "svm",
"shuffle_train_test_split": True,
"test_size_fraction": 0.2},
)
def svm_model(
fit_clf: base.ClassifierMixin,
training_accuracy: float, testing_accuracy: float
) -> dict:
return {
"svm": fit_clf,
"metrics": {"training_accuracy": training_accuracy,
"testing_accuracy": testing_accuracy}
}
@subdag(
model_fitting, # module to build subdag from
inputs={
"data_set": source("data_set_v2"),
},
config={
"clf": "logistic",
"shuffle_train_test_split": True,
"test_size_fraction": 0.2,
},
)
def lr_model(
fit_clf: base.ClassifierMixin,
training_accuracy: float, testing_accuracy: float
) -> dict:
return {
"logistic": fit_clf,
"metrics": {"training_accuracy": training_accuracy,
"testing_accuracy": testing_accuracy}
}
# ----- run.py
# we would now request `svm_model` and `lr_model` as outputs,
# or we could save each of them to MLFlow via our materializerWhat the decorator is effectively doing is expressing what the sub-pipeline is (see image below), and what we’re wiring through to it. So in this example we’re creating two models: SVM and Logistic Regression. The sub-pipeline fits the model and returns some metrics. The function parameters on the `lr_model()` and `svm_model()` functions declare what they pull from the “subdag” - `fit_clf` and `training_accuracy` respectively. To request these models to be built in our pipeline, it is a matter of requesting svm_model and/or lr_model. One can see a full example of this here.
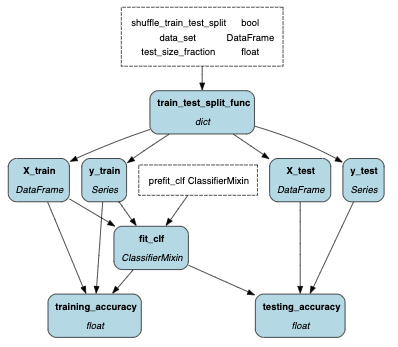
@subdag is often used in data processing, complex feature engineering, and model fitting and evaluation (e.g. hyper parameter tuning) use cases. An extension of @subdag is @paramterized_subdag, which (as you probably guessed) allows you to parameterize @subdag.
Can I cache parts of the pipeline easily during development?
Model pipelines can take a while to execute. There’s nothing more frustrating than it breaking, fixing it, and then having to wait a long time for it to re-run because it’s starting from scratch. Checkpointing/caching is one technique to be able to pick up where you left off, and Hamilton supports you doing this. We now use an adapter again. An adapter can modify many aspects of how Hamilton operates. For this use case, Hamilton has a CachingAdapter that modifies the pipeline as it is executed, i.e. it checks a cache for a value, else it performs computation. Use this for parts of the pipeline that take a long time to compute. It is not a fully fledged checkpointing solution, but we have this on our roadmap! To use it we just need to do two things (1) tag functions we want to cache or “checkpoint”, and (2) pass the adapter in at Driver construction time. Note, the CachingAdapter is an example of a community contribution from a user at IBM.
# ------- model_pipeline.py
from hamilton.function_modifiers import tag
@tag(cache="pickle")
def trained_model(featurized_data_set: pd.DataFrame,
target: pd.Series, ...) -> "model":
"""Trains a model based on the featurized data set."""
_model = some_framework.fit(featurized_data_set, target: pd.Series)
# any other logic
return _model
# -------- run.py
from hamilton import base, driver
from hamilton.experimental import h_cache
import data_loading, features, model_pipeline
# Initialise the cache directory
cache_path = "tmp"
pathlib.Path(cache_path).mkdir(exist_ok=True)
cache_adapter = h_cache.CachingGraphAdapter(cache_path, base.Default())
dr = (
driver.Builder()
.with_modules(data_loading, featurization, model_pipeline)
.with_adapters(cache_adapter) # add the adapter
.build()
)
dr.execute(...)This only executes trained_model and its upstream dependencies if there is no cached value for it. That way, if fitting a model took a long time, you wouldn’t need to recompute it. This adapter assumes you can write to a local filesystem. You could extend it for your needs and have it write to a place of your choice. For an example using the CachingAdapter see this code. Note: you could replicate some of this functionality to an extent with materializers, and these two approaches will be merging in the future.
Some best practices
In this section, we highlight a few best practices. Note, more are listed here, as are a variety of HOW-TOs here.
Where should I start?
Hamilton is just a library, and you can derive value from it incrementally. So most people start by either using Hamilton on a greenfield project, or rewriting a small portion of an existing pipeline with it, such as a set of feature engineering steps. From there, it’s up to you how to proceed! We’re happy to help if you have questions.
How do I convince others?
We wrote a post on ADKAR (that reached the front page of Hacker News!) which is a way to structure your thinking on how to convince others that Hamilton is worth a shot.
About Development to Production:
Here are some more guiding thoughts on using Hamilton in development and taking it to production.
Data: It all fits in memory.
If all your data and work fits in memory on a single machine, great! This means that what you do locally with Hamilton will transfer to production with no required modifications! Yes, really!
Data: it doesn’t all fit in memory.
In development you might have a toy data set, but when you run it in production it’s bigger. With Hamilton you can logically create an end-to-end pipeline, and then later decide to only run different subsections of it. This is the general advice (other than moving to a distributed data type) on how to deal with cases where you can’t run everything in memory when moving to production. Commonly this is where you pair Hamilton with a macro orchestration system like Airflow (see this blog).
In our toy example we could run the featurization, and model parts in separate “jobs”. E.g.
# ----------- Job 1
from hamilton.io.materialization import to
from hamilton import driver
# import the modules
import data_loading, features, model_pipeline
dr = (
# declare the driver and what the pipeline is to be built from
driver.Builder()
.with_modules(data_loading, featurization, model_pipeline)
.build()
)
# use materializer to save feature set
feature_saver = to.parquet(
id="feature_saver",
path="...",
dependencies=["featurized_data_set"]
)
# we don't request model computation here as an output
materialized_results, results = dr.materialize(
feature_saver,
inputs={"location": ...,}
)
# ----------- Job 2
from hamilton.io.materialization import from_
from hamilton import driver
# import the modules
import data_loading, features, model_pipeline
dr = (
# declare the driver and what the pipeline is to be built from
driver.Builder()
.with_modules(data_loading, featurization, model_pipeline)
.build()
)
# use materializer to load and inject features into graph
feature_loader = from_.parquet(
id="feature_saver",
path="...",
target="featurized_data_set",
)
# we request model computation as an output but, start from the feature set from the prior job!
materialized_results, results = dr.materialize(
feature_loader, ["trained_model"],
inputs={"target": ...,}
)Did you notice that the structure for the jobs is pretty similar? A byproduct of Hamilton, is that all jobs take on a similar look and feel — that’s standardization at work for you! As a side note, this enables teams that operate in a hand-off model to work more effectively; Hamilton helps standardize the code being handed-off, how to exercise it, debug it, and understand it.
Compute: I need to parallelize.
Hamilton has two facilities for parallelizing computation. One uses GraphAdapters to connect with Ray, Dask, and Pyspark, or uses the Parellelizeable type construct that delegates to Ray, Dask, or your executor of choice. You can find a quick write up on using the GraphAdapter with Ray, and here on using Parallelizeable. We have ideas for extensions to both, so if you find something you want/need to extend reach out.
Using CI effectively.
With Hamilton, not only can you unit test every function, but you also have a great integration testing story. With the overrides= capabilities, along with the ability to only run what’s required to compute a result, you can set up integration tests quickly and easily, exercising entire chains of functions. Hamilton also reduces the need to create “mock” objects since you can swap function implementations (@config, via modules), override values in the graph via overrides= or inject values in with a materializer.
Future Roadmap
We’re excited for the future of Hamilton and have a lot on the roadmap. Here are some of the things that we’re really looking forward to:
We started hub.dagworks.io to make it easier to share python modules with Hamilton code. We want to make it easy to pull some Hamilton code off-the-shelf for a specific task. E.g. feature engineering, model fitting, etc. and in three lines of code download and execute it! We’re working on adding more and looking for contributions to grow this and make it even easier to start with Hamilton to accomplish various tasks. E.g. feature engineering over common data sets, common model fitting and evaluation strategies, etc.
We’re going to be adding more “materializers” (data savers/loaders) over time. We want to make connecting to your favorite tools and vendors quick and simple. If we don’t have a materializer that fits, (e.g. you want to connect to a vendor or you are a vendor and want to make it easier to connect to you), we can help you and contribute it back to the community!
Driver chaining. Some logic and pipelines could be more simply expressed if you could “chain” drivers together. This would allow you to instantiate different parts of the pipeline separately and then connect them together, making it easier to dynamically create different graph parameterizations.
Fingerprinting. Firms that process data regularly to make business decisions author pipelines, updating them regularly, to do so. But, they don’t want their pipelines to reprocess data if code or data hasn’t changed. Fingerprinting is a technique to help evaluate this. The net result is that only what’s changed will be computed when a pipeline is run. Reach out if this would interest you.
Open telemetry and open lineage integration. These are two standards that Hamilton could implement and provide you with instrumented code without you having to lift much of a finger! Usually, it is quite a bit of work to properly integrate these. With Hamilton, we could hide a lot of the details and make it a one line code change to give you full instrumentation of your code!
To finish
Wow, this is the longest technical post we’ve written. Thank you for reading if you got this far! Hopefully we’ve imbued you with the following:
What an end-to-end ML Pipeline looks like in Hamilton, from something very simple, to more sophisticated.
The benefits of using Hamilton to structure your ML Pipeline over other approaches.
An idea of what your development to production journey might look like using Hamilton. If this isn’t clear, let us know so we can add more to this post!
What the key components to think about are when building an ML pipeline:
Curation of modules that correspond to different parts of the pipeline.
Materializers to help separate platform concerns from.
How one might iterate on pipelines and handle changes that happen through the lifecycle of a ML Pipeline, utilizing various Hamilton constructs where appropriate.
Try Hamilton for your next project, or replace a small part of your pipeline with it. We’d love your feedback on how it works out for you! If you have thoughts, or questions, leave a comment!
Resources, resources, resources
More resources to help you get that ML Pipeline up and running!
❓Join our Slack for help and community.
🔭 Browse examples in the repo, and also on hub.dagworks.io.
📒 Tutorial notebooks and more examples.