
Dynamic DAGs: Counting Stars with Hamilton
Introducing Dynamic DAGs in Hamilton!


TL;DR – in this post we share a new set of features in Hamilton that allow nodes to be dynamically generated, grouped, and executed in parallel. We go over a toy problem of counting unique stars between git repositories, and talk about the direction we’ll be moving in the future.
A Whole New DAG
When we first launched Hamilton + DAGWorks on hackernews, one of the biggest questions we got was whether Hamilton could be extended to dynamically generate nodes in a DAG (thank you @slotrans!). These nodes would have cardinality and parameters known only at runtime. While Hamilton comes with a powerful set of compile-time configuration capabilities, the DAG was entirely fixed after instantiation.
We are excited to announce that, with sf-hamilton==1.26.0, you can dynamically generate and parallelize nodes based on other nodes’ outputs!
In this post we’ll talk about why this is essential, how it’s implemented, how you can get started with it, and how you can extend it.
Hamilton: A Primer
If you’re not familiar with Hamilton, here’s a quick primer to get you started. Hamilton is a Python micro-framework for writing data transformations. One writes Python functions in a declarative style, which Hamilton parses into nodes in a graph based on their names, arguments and type annotations. You can request specific outputs, and Hamilton will execute the required nodes (specified by your functions) to produce them.

Motivation
In talking to Hamilton/Hamilton-curious data practitioners, we identified a series of themes that all required some level of dynamism. While these are feasible with vanilla Hamilton, they require some creative use of multiprocessing/DAG shapes and/or the extensive use of for-loops:
Processing a set of files in parallel, unknown at runtime.
Conducting a series of calls out to LLMs for retrieval augmented generation (RAG) in bulk.
Running a model over a dynamically determined set of hyper-parameters.
Running some algorithmically intensive time-series operations over a set of date ranges.
Loading up lots of small S3 URIs, processing them, then joining.
The exciting thing was that Hamilton was the most natural way to express these computations. Unfortunately, the static nature of Hamilton DAGs pushed the task of shaping these DAGs into the configuration layer, which resulted in less readable code and more complicated than necessary DAG shapes.
API
To represent dynamic DAGs, we introduce two new types:
Parallelizable[T]– Synonymous to a python generator, a function returning this indicates that anything that follows this node (untilCollect[T]) should be run for each yielded item, potentially in parallel.Collect[T]– Synonymous to a python generator, a function accepting this as a parameter aggregates across all previous executions of this result.
Confused? Let’s look at an example:
| def file_to_load() -> Parallelizable[str]: | |
| for file_ in _list_files(...): | |
| yield file_ | |
| def file_contents(file_to_load: str) -> str: | |
| with open(file_to_load) as f: | |
| return f.read() | |
| def all_contents(file_contents: Collect[str]) -> str: | |
| out = "".join(file_contents) | |
| return out |
In the code above we generate a set of files to load, execute `file_contents` over those files (potentially in parallel), and concatenate them all in `all_contents`.
All that’s left is to tell Hamilton to execute the code, and we have a new special Driver builder API to do so!
| import functions | |
| dr = ( | |
| driver.Builder() | |
| .enable_dynamic_execution(allow_experimental_mode=True) | |
| .with_modules(functions) | |
| .build() | |
| ) | |
| dr.execute(["all_contents"]) |
Note that this is currently labeled experimental, although we guarantee that the API is stable and that we will adhere to semantic versioning. Experimental just signifies we will be investing heavily in this feature. We will be removing the flag shortly.
Counting Stars
Let’s go over a pretty simple example that’s relevant to what we do at DAGWorks. When we initially launched DAGWorks, we forked the Hamilton repository from the original location at our old employer. While this gave us full control over the direction of the project, it came with one unfortunate side-effect – our star-count reset to zero. We can't just add the two counts together naively since there will be some overlap. In order to know the true star-count we want the union of the two sets of star gazers.
To solve this, we built a Hamilton pipeline that performs the union and gives us the star-history plot that everyone knows and loves:
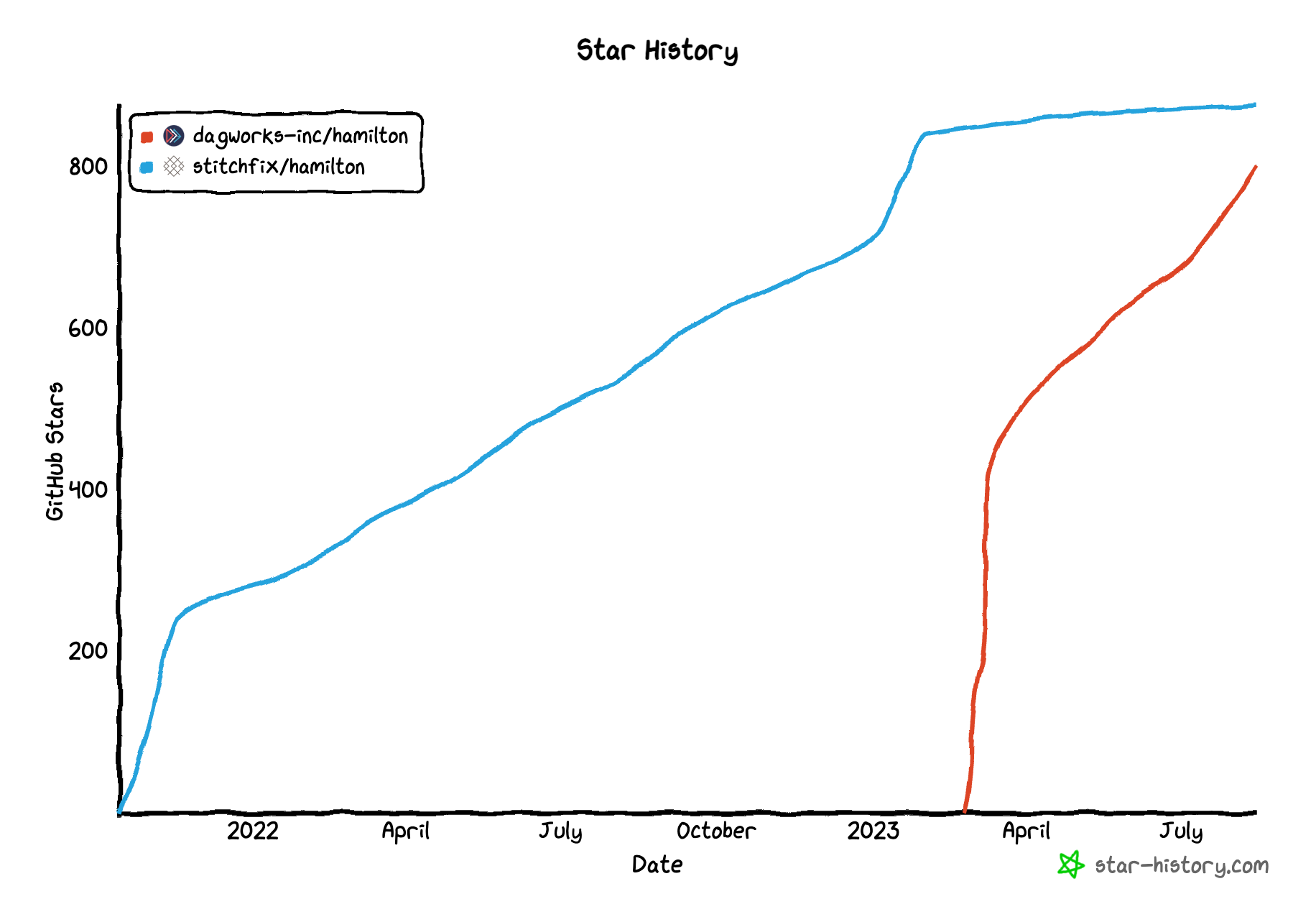
We’re going to go over the high-level components, but you can also download/play with the code here. The code is parameterized for any set of github repositories, so you can use it to count stars across your organization or some set of other repositories.
We’ll be using the github starring API, which is paginated. To get started, we’re going to break this workflow into a few components:
Gather star-count for each repo and break into pagination chunks
Gather the unique stargazers + starring time for each chunk
Aggregate the results
We will use the Parallelizable/Collect for querying both star-count per repo and querying the list of unique stargazers.
First, let’s look at how we get star count – we generate unique URLs for each repo and signify that downstream functions can be run in parallel.
| def starcount_url(repositories: List[str]) -> Parallelizable[str]: | |
| """Generates API URLs for counting stars on a repo. We do this | |
| so we can paginate requests later. | |
| :param repo: The repository name in the format 'organization/repo' | |
| :return: A URL to the GitHub API | |
| """ | |
| for repo in repositories: | |
| yield f"https://api.github.com/repos/{repo}" |
Then, we chunk those up into distinct queries, which we execute in parallel:
| def star_count(starcount_url: str, github_api_key: str) -> Tuple[str, int]: | |
| """Generates the star count for a given repo. | |
| :param starcount_url: URL of the repo | |
| :param github_api_key: API key for GitHub | |
| :return: A tuple of the repo name and the star count | |
| """ | |
| response = requests.get( | |
| starcount_url, headers={"Authorization": f"token {github_api_key}"} | |
| ) | |
| response.raise_for_status() # Raise an exception for unsuccessful requests | |
| data = response.json() | |
| return data["full_name"], data["stargazers_count"] |
We subsequently group them into a single dictionary so we have pagination data:
| def stars_by_repo(star_count: Collect[Tuple[str, int]]) -> Dict[str, int]: | |
| """Aggregates the star count for each repo into a dictionary, so we | |
| can generate paginated requests. | |
| :param star_count: A tuple of the repo name and the star count | |
| :return: The star count for each repo | |
| """ | |
| star_count_dict = {} | |
| for repo_name, stars in star_count: | |
| star_count_dict[repo_name] = stars | |
| return star_count_dict |
We repeat a similar process, utilizing the stars count we arrived at to break into paginated requests that we run in parallel.
<script src="
| def stargazer_url( | |
| stars_by_repo: Dict[str, int], per_page: int = 100 | |
| ) -> Parallelizable[str]: | |
| """Generates query objects for each repository, with the correct pagination and offset. | |
| :param stars_by_repo: The star count for each repo | |
| :param per_page: The number of results per page | |
| :return: A query object for each repo, formatted as a generator. | |
| """ | |
| for repo_name, stars in stars_by_repo.items(): | |
| num_pages = ( | |
| stars + per_page - 1 | |
| ) // per_page # Calculate the number of pages needed for pagination | |
| for page in range(num_pages): | |
| yield f"https://api.github.com/repos/{repo_name}/stargazers?page={page + 1}&per_page={per_page}" | |
| def stargazers(stargazer_url: str, github_api_key: str) -> pd.DataFrame: | |
| """Gives the GitHub username of all stargazers in this query | |
| by hitting the GitHub API. | |
| :param stargazer_query: Query object to represent the query | |
| :param github_api_key: API key for GitHub | |
| :return: A set of all stargazers | |
| """ | |
| headers = { | |
| "Authorization": f"token {github_api_key}", | |
| "Accept": "application/vnd.github.v3.star+json", | |
| } | |
| response = requests.get(stargazer_url, headers=headers) | |
| response.raise_for_status() # Raise an exception for unsuccessful requests | |
| data = response.json() | |
| records = [ | |
| { | |
| "user": datum["user"]["login"], | |
| "starred_at": datetime.strptime(datum["starred_at"], "%Y-%m-%dT%H:%M:%SZ"), | |
| } | |
| for datum in data | |
| ] | |
| return pd.DataFrame.from_records(records) | |
| @save_to.csv(path=value("unique_stargazers.csv")) | |
| def unique_stargazers(stargazers: Collect[pd.DataFrame]) -> pd.DataFrame: | |
| """Aggregates all stargazers into a single set. | |
| :param stargazers: Set of stargazers, paginated | |
| :return: A set of all stargazers | |
| """ | |
| df = pd.concat(stargazers) | |
| unique = df.sort_values("starred_at").groupby("user").first() | |
| return unique |
The DAG looks like this – we’ve added a few new visualization capabilities to mark what parts of the DAG could run many times over some input:

The double-line node indicates a
ParallelizableorCollectnodeThe crow connector indicates a many -> one relationship.
Parallelizablewill have the crow connector leading from it, indicating a one to many relationship.Collectwill have the opposite crow connector leading into it, signifying a many to one relationship.In the image above we have two
Parallelizable->Collectsub-DAGs. One from startcount_url to stars_by_repo. The other from stargazer_url to unique_stargazers.
To sum it all up, we get the following results!

Degrees of Freedom
The default execution mechanism will group nodes (you can think of them as mapping to functions) into tasks that reside between Parallalizable and Collect, delegating those to a threadpool to run. The rest will be run in the main thread. That said, it’s all customizable. You can change the grouping strategy, as well as the execution mechanism with the driver.Builder. We won’t go into the full set of configurations available (we’re actively building them as well), but the code shows how you can swap between Dask, Ray, multithreading, and local execution, which allows easy debugging on a smaller DAG.
Furthermore, we’re actively working on caching to allow you to restart failed workflows part of the way through.
Why write code this way?
We created Hamilton to enable anyone to adopt good software engineering practices and write clean and maintainable code. This gets easier when one logically express themselves at the datum level of processing, handing the execution of code to a framework. For example, by removing the for-loops and executors from within Hamilton functions, it’s even simpler to:
Unit and integration test functions. They don’t have to deal with execution!
Have someone come in and read/understand the sequence of logic, without being distracted by all the loops and executors in the code.
Port your code to run anywhere that python runs. You haven’t leaked that it has to run a particular way.
Scale your code. Flipping the switch from Ray to Dask to Spark is now a much lighter lift than before!
Now imagine…
With the new, powerful execution capabilities, take a step back to envision what you can now do with dynamic DAGs and pluggable executors:
Load up all CSVs from a downstream process, run them through a set of transformations then materialize the result.
Run parallel calls to Whisper to quickly transcribe a set of YouTube videos.
Conduct a grid search on remote executors over hundreds of possible hyper-parameter sets.
Run trading simulations in parallel over a large set of time-ranges and model parameters.
Process a massive set of S3 files in parallel to analyze your application’s usage.
The sky’s the limit. We want to hear from you, and would love to see examples of what you come up with!
Extensions/future directions
In addition to what we’ve already built, we’ve got a whole lot of exciting things in the works:
More expansive executors – we already have Dask/Ray executors implemented, but we’ll be improving them and opening up the API to be more extensible/customizable.
Spark-based executors – while we have a few spark-based integrations, we are making this first-class. We will shortly have tooling that allows Hamilton DAGs to group into sets of discrete UDFs and utilize the new task-management abstraction to execute them efficiently as UDFs.
Sequentialwill allow you to execute tasks in order while garbage collecting the recently used memory.Caching/development/profiling/requesting intermediate features – all debugging capabilities coming soon!
We want to hear from you!
If you’re excited by any of this, or have strong opinions, drop by our Slack channel / or leave some comments here! Some resources to get you help:
📣 join our community on Slack — we’re more than happy to help answer questions you might have or get you started.
⭐️ us on GitHub
📝 leave us an issue if you find something
Other Hamilton posts you might be interested in: