
Feature Engineering with Hamilton
Write once*, run everywhere



TL;DR
Hamilton is a lightweight framework that gives you the tools to write clean, modular feature engineering pipelines. Hamilton is highly customizable and can help you solve the problem of keeping features for your model consistent across batch, streaming, and online execution contexts.
Between you and Production…
Imagine the following: as an MLE at a thriving e-commerce site, you’ve found an exciting new model that will significantly boost revenue and user retention. The only thing that stands between you and delivering this newfound efficiency is building a scalable, reliable, and consistent feature engineering pipeline that can serve your nightly model training and batch inference jobs as well as your real-time inference services, so you can adequately serve your customers.
If the prior sentence filled you with dread, you’re not alone. The most time-consuming and painful part of getting models to production is almost always extracting and preparing the data for production, combining it from disparate sources into a unified shape that your model can consume.
In this blog post we will talk about how Hamilton can help you build maintainable, portable workflows that share code across multiple contexts in which you execute your models. We will show code snippets to help you get started, and discuss how it compares with other approaches to feature engineering.
First, let’s dive a little more into what makes feature engineering tough.
Challenges with Feature Engineering
To highlight why feature engineering can be difficult, we’re going to present a scenario (inspired by a problem I faced in a previous job).
As the MLE on the onboarding team, your customers fill out onboarding surveys and you get to build production models that optimize the user experience based on that data. Your goal is to build a model that predicts some aspect of the customer’s behavior, enabling the site to suggest what they’re most likely to enjoy and buy.
The model is executed in a few different contexts:
Online servers to serve the user as quickly as possible
Batch ETLs, to get a snapshot of the results
Batch training, to update the model with new data
Streaming, as users sign up
Note that (1) and (4) are very similar, and unlikely to be done contemporaneously. For the purpose of this post we will group the batch modes together and the real-time modes together – extending to adjacent contexts is left as an exercise to the reader.

To design a robust system, you’ll need to think through the following:
Ensuring consistency between contexts. Given that you run the same model in multiple settings, the features need to be functionally the same – any differences should be documented and closely monitored to avoid training/serving skew.
Maintaining/debugging code. Spread across different contexts, you’ll want to ensure your pipeline is easy to debug, easy to understand the flow of data, and easy to modify/fix when it breaks. Knowing how features relate to each other so you can estimate downstream impacts of a change is critical.
Scaling. While not everyone has to deal with scaling issues, it's quite likely that the frameworks that are optimal for running on row-level/mini-batched data (python primitives, pandas) are different from those meant to execute on large scale data (spark).
Monitoring. You’ll want to understand how your features differ between contexts - ensuring that a context-specific bug doesn’t cause the quality of your model’s predictions to drop off in production, while staying high-quality in training.
Configuring versions/iterating on feature shape. A feature pipeline is likely to change over time as model creators develop more complex models and find new datasets. It is critical that changes are easy to make and track.
To help solve these, let’s first dig into Hamilton.
Hamilton
Hamilton is a lightweight tool for expressing dataflows in python. While it has a wide array of applications, it is particularly well-suited for feature engineering, One expresses a feature as a plain old python function – the name of which is the feature name, and the parameters names correspond to feature dependencies (other features or external inputs). You can request specific outputs, and Hamilton will execute just the dependencies required to produce them.
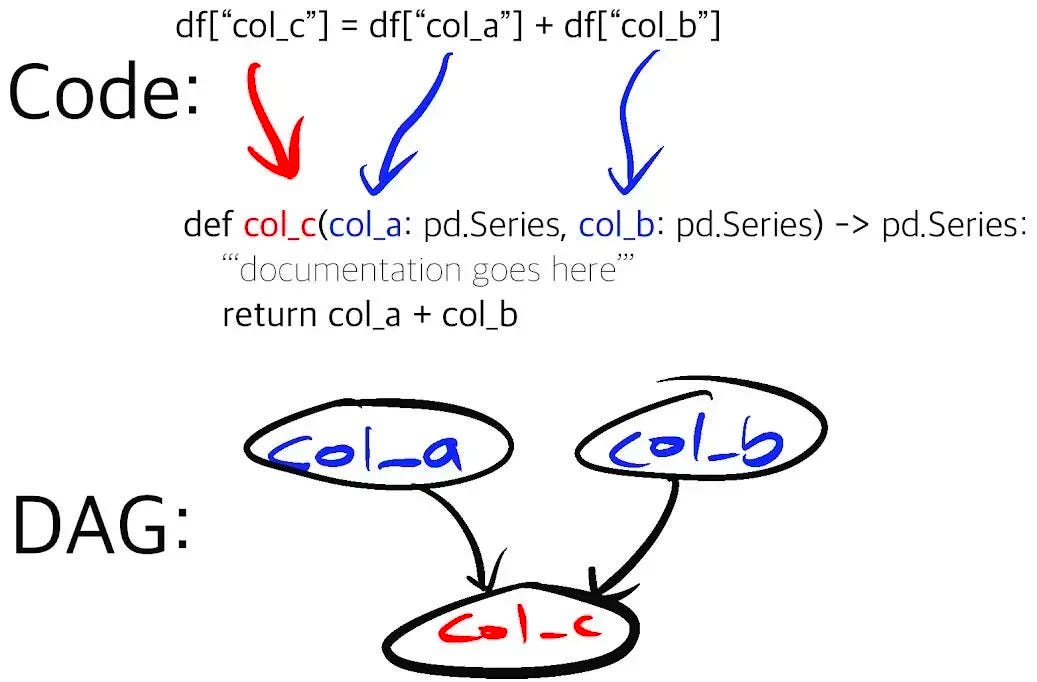
In constructing a feature engineering pipeline, Hamilton presents the following benefits:
Unit testable functions. Small, functional components are easy to unit test.
Modular code. Hierarchy is naturally presented as code is grouped into functions, and functions are grouped into modules.
Self-documenting assets. Due to the naming requirements, there is a natural mapping from a materialized feature to code that generated it.
Easy data validation. Hamilton’s check_output decorator allows you to run data quality assertions on the output of your functions.
Fine-grained lineage. One can easily determine the source and dependencies of any feature by looking at the code and visualizing the DAG.
Now that we’ve presented Hamilton, let’s dig into how we might apply it towards feature engineering.
Write Once*
When to Unify
You may have noticed the asterisk by “write once” throughout this post. This is because there is logic that is fundamentally different between the two contexts. Take a look at this table for equivalencies:

In the case of map operations, logic (and thus code) reuse between contexts is feasible. Furthermore, these transformations play a particularly important role. As features in a feature set share a common entity, they can all be represented as map transformation (either an identity from an upstream column, or something more complex). As you’ll see with Hamilton, these map transformations themselves can even form a feature catalog!
While every feature pipeline is different, we’ve observed these expanding quickly and taking over a codebase. So, although these are the only pieces that can be written once, there is very high value in doing so.
In non-map operations, the computation varies between contexts. In fact, the decision of how to translate the operation to an online mode can potentially influence the decision a model makes, in non-trivial ways. Employing a streaming aggregation technique to normalize features can enable a model to quickly react to changes in the underlying distribution. This may prove overly complex, or critical, depending on the context and the sensitivity of the model.
Most current approaches to ensuring consistency between online and batch contexts don’t give you the flexibility to make these decisions. They commonly fall into two categories:
Entirely different code that can be optimized for each case (and, if well-designed, can be consolidated with a series of assertions)
High level, opinionated DSLs
Hamilton presents a middle ground between the two – you can reuse map operations between the two cases, and reimplement any non-map operations in just the way you want.
Common Operations
To start off our pipeline, we’ll build a series of “common” (map) operations using Hamilton. Note that we elect to use pandas series as inputs/output.1 That said, you can happily employ any dataframe library (as well as python primitives) with only minor adjustments to the code.
The map transformations we write here will be run both in batch and online – these form the core of your “feature catalog”. Note that these currently rely on features that we have not defined yet — we’ll be filling those in.
| def is_male(gender: pd.Series) -> pd.Series: | |
| return gender == "male" | |
| def is_female(gender: pd.Series) -> pd.Series: | |
| return gender == "female" | |
| def is_high_roller(budget: pd.Series) -> pd.Series: | |
| return budget > 100 | |
| def age_normalized(age: pd.Series, age_mean: float, age_stddev: float) -> pd.Series: | |
| return (age - age_mean) / age_stddev | |
| def time_since_last_login(execution_time: datetime, last_logged_in: pd.Series) -> pd.Series: | |
| return execution_time - last_logged_in |
This forms the following (currently disjoint) DAG, which represents the commonalities between the different contexts.

While this example is simplified to showcase a concise feature-engineering workflow, we anticipate this segment will expand substantially, contributing to most of the complexity of the pipeline and forming the feature catalog.
Run Everywhere
Now we get to the tricky part – the code that has to be different between online and batch. To specify the behavior on a per-context basis, we utilize the config.when decorator. The behavior is simple — when the condition passed to @config.when evaluates to true, that function is used in the DAG. Note that Hamilton gives you other approaches to do implementation-swapping. For instance, you can reassign the functions to separate modules, loading just the module you need for your context (see this blog post for an example of swapping out implementations).
Joins/Loading
It is likely that not all your data will come from the same table. In this case, we’ll be loading our survey features and joining with browsing data-related features that have been recorded by another system. In batch processing these loads would could from a table in your data warehouse, updated nightly. The join would be a standard join (in your dataframe library or SQL). Online, that table (or the upstream source of it) is wrapped in a service that you can query with up-to-date data. In this case we’ll be joining our client data with the table of login data.
| #data_loaders.py | |
| @config.when(mode="batch") | |
| @extract_columns("budget", "age", "gender", "client_id") | |
| def survey_results(survey_results_table: str, survey_results_db: str) -> pd.DataFrame: | |
| """Map operation to explode survey results to all fields | |
| Data comes in JSON, we've grouped it into a series. | |
| """ | |
| return utils.query_table(table=survey_results_table, db=survey_results_db) | |
| @config.when(mode="batch") | |
| def client_login_data__batch(client_login_db: str, client_login_table: str) -> pd.DataFrame: | |
| return utils.query_table(table=client_login_table, db=client_login_db) | |
| # join.py | |
| @config.when(mode="batch") | |
| def last_logged_in__batch(client_id: pd.Series, client_login_data: pd.DataFrame) -> pd.Series: | |
| return pd.merge(client_id, client_login_data, left_on="client_id", right_index=True)[ | |
| "last_logged_in" | |
| ] |

To run online, we’ll be querying an external service rather than conducting an in-process join (we are pushing the join operation into the service with the data, similar to how one might do a join in SQL rather than in memory).
| @config.when(mode="online") | |
| @extract_columns( | |
| "budget", | |
| "age", | |
| "gender", | |
| ) | |
| def survey_results__online(client_id: int) -> pd.DataFrame: | |
| """Map operation to explode survey results to all fields | |
| Data comes in JSON, we've grouped it into a series. | |
| """ | |
| return utils.query_survey_results(client_id=client_id) | |
| @config.when(mode="online") | |
| def last_logged_in__online(client_id: int) -> pd.Series: | |
| return utils.query_login_data(client_id=client_id)["last_logged_in"] |
This compiles to the following DAG:

Aggregations
As we normalize the age variable in both online/batch mode, we need to perform an aggregation. In batch, this is straightforward – we perform the aggregation, gather the scalars, then apply the normalization back on the age series to form age_normalized.
| @config.when(mode="batch") | |
| def age_mean__batch(age: pd.Series) -> float: | |
| return age.mean() | |
| @config.when(mode="batch") | |
| def age_stddev__batch(age: pd.Series) -> float: | |
| return age.std() |

For the online case, we will assume that the training routine saves static values to a queryable key-value store for the mean/standard deviation. All we have to do is retrieve the data online:
| @config.when(mode="online") | |
| def age_mean__online() -> float: | |
| return utils.query_scalar("age_mean") | |
| @config.when(mode="online") | |
| def age_stddev__online() -> float: | |
| return utils.query_scalar("age_stddev") |

Alternatively, one could envision performing this calculation online in a variety of ways. In other cases, assuming static data might not be optimal. We could collect streaming values, pass to efficient sliding window aggregators, and recompute efficiently on the fly. While Hamilton does not provide the infrastructure/algorithm to do this specific sort of computation, it makes it easy to swap out implementations and run tests/experiments between them.
Inference
Finally, we tie everything together with a model! This is the same in batch/online mode, although you may load the model differently.
| def features( | |
| time_since_last_login: pd.Series, | |
| is_male: pd.Series, | |
| is_female: pd.Series, | |
| is_high_roller: pd.Series, | |
| age_normalized: pd.Series, | |
| ) -> pd.DataFrame: | |
| return pd.DataFrame(locals()) | |
| def predictions(features: pd.DataFrame, model: Model) -> pd.Series: | |
| """Simple call to your model over your features.""" | |
| return model.predict(features) |
Now that we’ve built all our pieces, the DAG has two different forms:

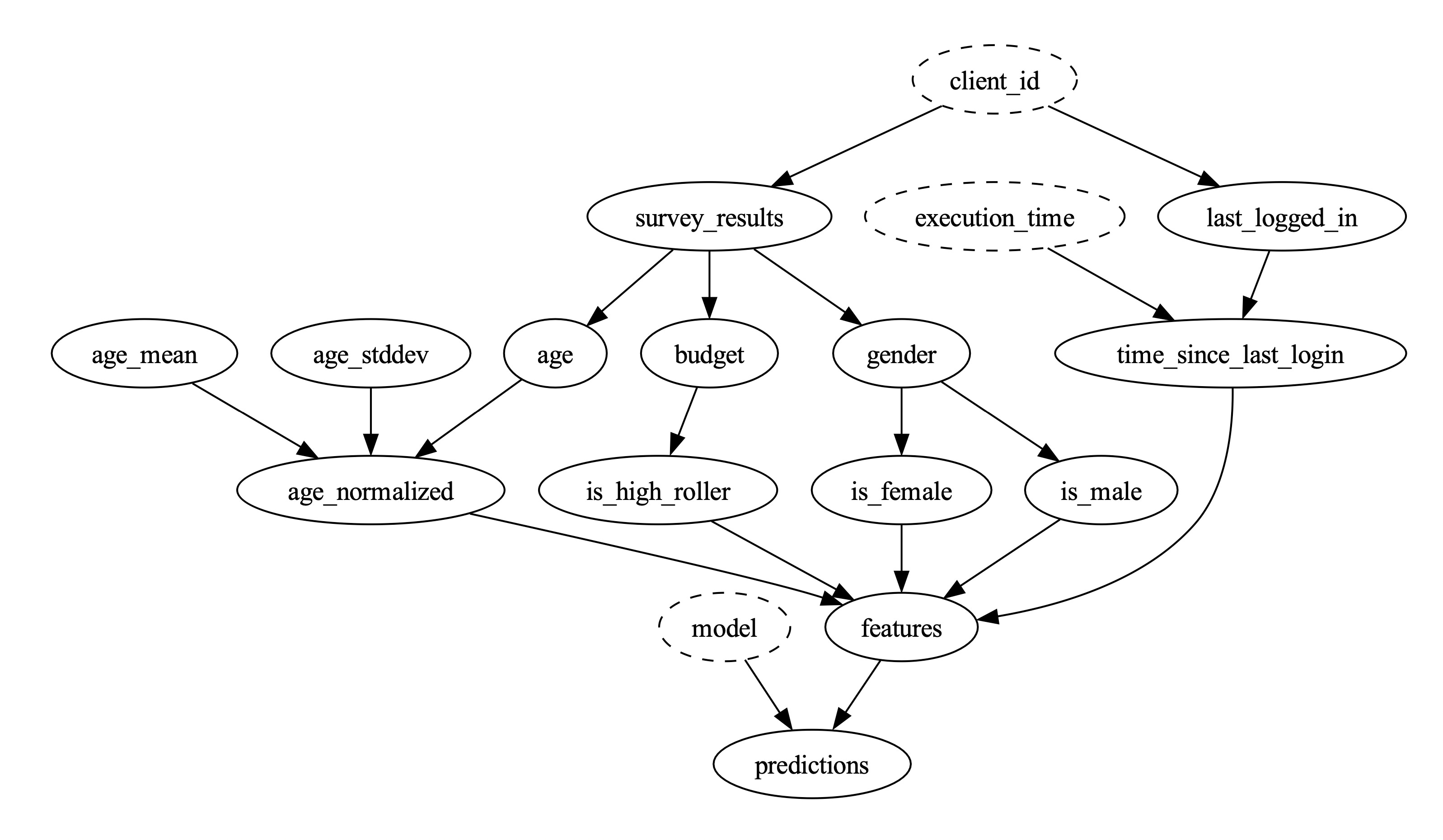
Note that the map operations and the model execution component share the exact same code.
Executing
Now that we’ve written all the code, it is straightforward to run. For batch mode, we simply need to instantiate a driver, execute it with the desired parameters (databases/tables in this case), and do something with the results.
| from hamilton import driver | |
| dr = driver.Driver( | |
| {"mode": "batch"}, | |
| aggregations, data_loaders, joins, features, model | |
| ) | |
| inputs = { | |
| "client_login_db": "login_data", | |
| "client_login_table": "client_logins", | |
| "survey_results_db": "survey_data", | |
| "survey_results_table": "survey_results", | |
| "execution_time": datetime.datetime.now(), | |
| } | |
| df = dr.execute(["predictions"], inputs=inputs) |
In the online case, we’ll take the same modules, instantiate another driver, and execute that in a FastAPI service:
| app = FastAPI() | |
| dr = driver.Driver( | |
| {"mode": "online"}, | |
| aggregations, | |
| data_loaders, | |
| joins, | |
| features, | |
| model, | |
| adapter=base.DefaultAdapter(), | |
| ) | |
| @app.get("/predict") | |
| def get_prediction(client_id: int) -> float: | |
| series_out = dr.execute( | |
| ["predictions"], inputs={"client_id": client_id, "execution_time": datetime.now()} | |
| )["predictions"] | |
| return series_out.values[0] |
All of this code is available on the github repo with instructions on adapting to your use-case. Feel free to download and modify!
Extensions/Integrations
Hamilton provides a highly customizable way to build production-ready feature engineering pipelines, while reducing the surface area of changes required to iteration. One could easily imagine a host of extensions:
Handling model objects – the serialized model could provide a few of the static data (aggregations), and execute inference on post-processed data (both in batch/online). A simple
functools.lru_cachedecorator on top of the model loading function could allow the service to store this as state (although you’d have to determine an adequate model release/update process.) The model execution component could easily be represented as a Hamilton function and shared between online and batch, although the processing of the model result might differ.Data observability – while Hamilton is not an observation platform, you can utilize the DAGWorks platform for tracking/managing your DAGs and results as well as exploring lineage and forming a feature catalog. Tooling such as evidently and whylabs can help monitor data to avoid data drift between training, batch inference, and online inference.
Connection to a feature store — while Hamilton provides lightweight featurization tooling and orchestration, you may find it advantageous to store either the preprocessed or post-processed results in a feature store (either as part of batch/training). We have outlined how one could use Feast to do this, but Hamilton should work happily with any feature store.
Scaling up — we’ve represented the transformations in pandas, which may limit the scale of your application. Hamilton, however, has a variety of integrations with scaling libraries. Modin can allow you to seamlessly scale pandas up. Hamilton comes out of the box with PySpark integrations, enabling you to mix/match pandas UDFs with PySpark transformations. This allows you to scale up the pandas map operations to work for individual rows, mini-batch, and large datasets. See the blog post on the new spark integration to get started.
Up Next
Looking ahead, we’re really excited about the potential Hamilton has to improve productionizing/iterating on feature engineering workflows. We’re planning the following:
First class feast/other feature store integrations.
Integration with service tooling to make moving subcomponents of an ETL into a streaming setting. Got a favorite streaming framework that speaks Python? Let us know.
Improved caching to allow for one-time-loading of static data, such as aggregation results (see the caching graph adapter for current progress).
We want to hear from you!
If you’re excited by any of this, or have strong opinions, drop by our Slack channel / leave some comments here! Some resources to help you get started:
📣 join our community on Slack — we’re more than happy to help answer questions you might have or get you started.
⭐️ us on GitHub
📝 leave us an issue if you find something
📈 check out the DAGWorks platform and sign up for a free trial
Other Hamilton posts you might be interested in:
tryhamilton.dev – an interactive tutorial in your browser!
While this is marginally less efficient for online row-level operations than managing python primitives, the difference is likely to be dwarfed by the network cost. Furthermore, should one decide to conduct operations in mini-batches, it is a far cleaner way to model computation.