
Expressing PySpark Transformations Declaratively with Hamilton
How you can use Hamilton's new PySpark API to build modular, scalable dataflows.


Transforming Data at Scale
Computational scalability shouldn't come at the cost of code complexity.
In this blog post we’ll be focusing on how Hamilton can help you build highly maintainable dataflows at scale with PySpark. We will introduce a brand-new Hamilton API for organizing PySpark transformations, show how it improves vanilla PySpark code, walk through some use-cases, and present the roadmap for Hamilton and PySpark moving forwards.
First, a primer on the two technologies (just in case you’re new to one or both).
Apache Spark
Apache Spark (and its python API PySpark) is an open-source library for building out highly scalable data transformations. At its core is the notion of the RDD (resilient distributed dataframe), which represents a lazily evaluated, partitioned, in-memory dataset that stores the information needed to recreate the data if any of the servers computing it fail. The PySpark library gives data practitioners a dataframe-centric API to interact with this in Python, enabling them to specify computation and scale up to the resources they have available. Since its introduction in 2014, Spark has taken off and is now the de facto way to perform computations on large (multi gb -> multi tb) datasets.
PySpark Painpoints
Just like any data transforming code, Spark applications can be difficult to maintain and manage, and often devolve into spaghetti code over time. Specifically, we've observed the following problems with PySpark applications:
They rarely get broken up into modular and reusable components.
They commonly contain "implicit" dependencies. Even when you do break them into functions, it is difficult to specify which columns the transformed dataframes depend on, and how that changes throughout your workflow.
They are difficult to configure in a readable manner. A monolithic Spark script likely has a few different shapes/parameters, and naturally becomes littered with poorly documented if/else statements.
They are not easy to unit test. While specific user defined functions (UDFs) can be tested, Spark transformations are tough to test in a modular fashion.
They are notoriously tricky to debug. Large collections of Spark transformations (much like SQL transformations) will often have errors that cascade upwards, and pinpointing the source of these can be quite a challenge.
Hamilton
Hamilton is an open-source Python framework for writing data transformations. One writes Python functions in a declarative style, which Hamilton parses into nodes in a graph based on their names, arguments and type annotations. You can request specific outputs, and Hamilton will execute the required nodes (specified by your functions) to produce them.
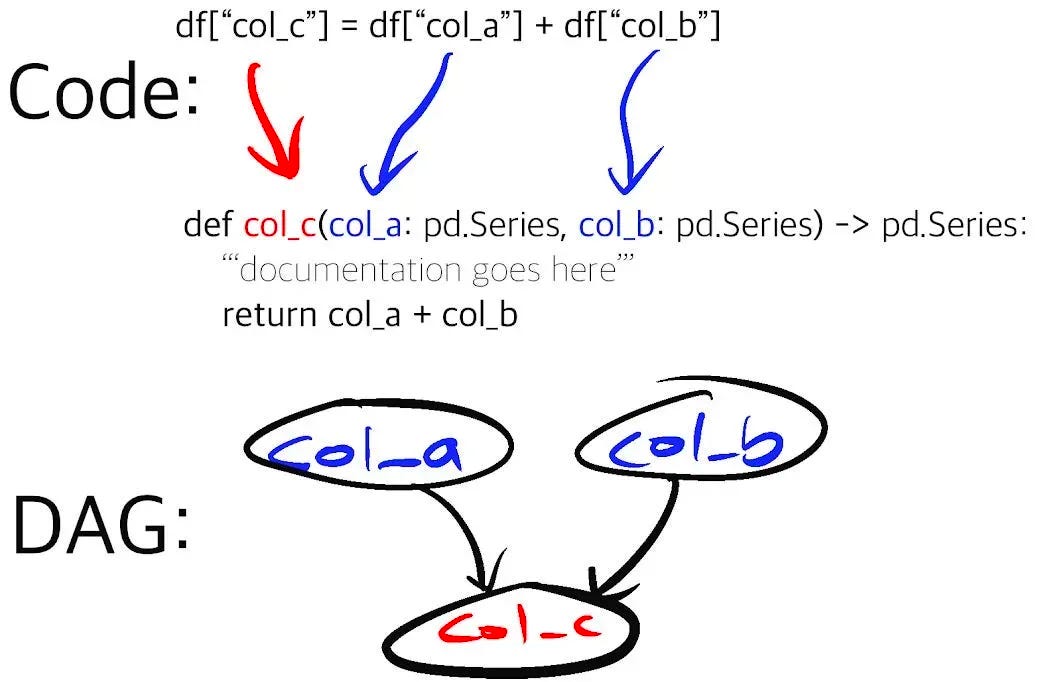
While this paradigm is simple, it comes with a variety of benefits for the writers, maintainers, and future inheritors of the code. By virtue of the paradigm and a few of its core features, adopting Hamilton gives you:
Unit testable functions. Small, functional components are easy to unit test.
Modular code. Hierarchy is naturally presented as code is grouped into functions, and functions are grouped into nodes.
Self-documenting assets. There is a natural mapping from data generated to code that generated it.
Easy data validation. Hamilton’s check_output decorator allows you to run data quality assertions on the output of your functions.
Fine-grained lineage. One can easily determine the source of any transformation and its dependencies by looking at the code.
Integration
Breaking your code into “Hamilton functions” with PySpark dataframes as inputs and outputs gets you most of the way towards the Hamilton advantages listed above. That said, it falls flat in a critical area – column-level lineage/transformation simplicity. For complex series of map operations, Spark represents all transformations on a single dataframe in a linear chain by repeatedly calling withColumn/select to create columns.
For dataframe APIs that manage indices, Hamilton improves this experience by encouraging the user to pull apart column-level transformations then join later. With columns that share cardinality, this is generally an efficient approach. Spark, however, has no notion of indices. Data is partitioned across a cluster, and once a set of columns is selected it has the potential to be reshuffled. Thus, the two options one previously had for integrating with PySpark both have disadvantages:
Extracting into columns then joining is prohibitively expensive and taxing on the Spark optimizer (which we have not found was smart enough to detect this pattern)
Running pure DataFrame transformations does not afford the expressiveness that Hamilton provides.
Hamilton 1.27.0 introduces a new API to give the user the best of both worlds. You can now express column-level operations in a DAG on the same dataframe, as part of a multi-step process.
With the new @with_columns decorator, your break your Spark applications into two classes of steps:
Cardinality non-preserving operations (joins, aggregations, and filters)
Cardinality-preserving operations (row-wise maps and their more efficient map-partition implementations, and rolling/broadcasted aggregations)
Examples of (1) include filtering a customer dataset to a specific region, joining that dataset with a dataset of purchases, and determining statistics/counts over that dataset. Examples of (2) include transformations on the prices of items bought, normalization (de-meaning) of those prices, and rolling time-level aggregations.
You represent (1) as a series of linear operations – functions instead of chained PySpark calls. The decorator @with_columns gives you the power to delegate functions representing a DAG of transformations that perform (2) to another module/set of functions. This allows them to be unit tested, self-contained, and reused.
Hamilton then compiles this sub-DAG of transformations into chained functions of PySpark dataframes, while preserving column-level relationships for display in the DAG for visualization.

While above image is intended as eye-candy to demonstrate the power of Hamilton + PySpark, let’s demonstrate how this works through a simple example:
(1) We load up/join our data for processing:
| import pyspark.sql as ps | |
| from hamilton.function_modifiers import load_from, value, source | |
| @load_from.csv(path=value("data_1.csv"), inject_="raw_data_1", spark=source("spark")) | |
| @load_from.parquet(path=value("data_2.parquet"), inject_="raw_data_2", spark=source("spark")) | |
| def all_initial_data(raw_data_1: ps.DataFrame, raw_data_2: ps.DataFrame) -> ps.DataFrame: | |
| """Combines the two loaded dataframes""" | |
| return _custom_join(raw_data_1, raw_data_2) |
(2) We specify the group of UDFs that we wish to apply as map operations to the dataframes. Note that, in this case, we’re using pandas UDFs (vectorization for the win!), but the integration enables multiple other function shapes, including Python primitives and functions of PySpark dataframes/columns.
| import pandas as pd | |
| def column_3(column_1_from_dataframe: pd.Series) -> pd.Series: | |
| return _some_transform(column_1_from_dataframe) | |
| def column_4(column_2_from_dataframe: pd.Series) -> pd.Series: | |
| return _some_other_transform(column_2_from_dataframe) | |
| def column_5(column_3: pd.Series, column_4: pd.Series) -> pd.Series: | |
| return _yet_another_transform(column_3, column_4) |
(3) Finally, we specify which columns we wish to apply using the @with_columns decorator.
| from hamilton.plugins.h_spark import with_columns | |
| import pyspark.sql as ps | |
| import map_transforms # file defined above | |
| @with_columns( | |
| map_transforms, | |
| columns_to_pass=["column_1_from_dataframe", "column_2_from_dataframe"] | |
| ) | |
| def final_result(all_initial_data: ps.DataFrame) -> ps.DataFrame: | |
| """Gives the final result. This decorator will apply the transformations in the order specified in the DAG. | |
| Then, the final_result function is called, with the result of the transformations passed in.""" | |
| return _process(all_initial_data) |
And that’s it! The final DAG we’ve produced looks like this:

The easiest way to think about this is that the @with_columns decorator linearizes the DAG. It turns a DAG of Hamilton functions into a linear chain, repeatedly appending those columns to the initial dataframe in topological order. It is equivalent to calling withColumns repeatedly on the same dataframe with new transformations, while preserving lineage and reducing the space of transforms to operate just on the data they need.
Some Real World Code
We’ve implemented three of the TPC-H benchmarking queries to demonstrate how this looks on more realistic examples. While we won’t dive in too much here (there’s more in the README), we can highlight:
If you don’t have time to read through all of these, no worries! The TL;DR is:
Use Hamilton functions that transform standard PySpark dataframes to represent a few chained transformations. the boundary between functions will be, at the widest, when the dataframe changes dimensions, but occasionally you’ll want to break it up further.
Use with_columns to represent multiple columnar operations. While our examples did not contain more than 2-3, we’ve seen organizations manage hundreds of linear transformations in real-world feature-engineering workflows. A side effect of using Hamilton in this way is that you effectively build out a “bank of transforms” that can be standalone DAGs in themselves. This presents a standard means to share feature or metric definitions.
If in doubt, start by writing PySpark code. It is easy to break it into functions. You can use python debugging and partial execution to quickly and efficiently determine which steps should occur next.
Taking a Step Back
Looking at the bigger picture, Hamilton with PySpark enables you to build Spark applications with fine-grained lineage. You can represent column-level transformations while ignoring index-management while scaling up to levels that only Spark allows. This enables you to write concise, unit testable UDFs that break up the complexities of Spark code into highly configurable, self-documenting and modular components.
Not only can you now represent full PySpark applications with Hamilton, but you can seamlessly move between PySpark, pandas, and primitive Python, all while representing lineage through code. For example, you can build a metrics or feature definition “layer” (here it would just be Python code) that can be shared and reused across your codebase!
To really tie it together, you can write a large Spark ETL with Hamilton, break it into modules, and use those to determine job/serialization boundaries, either calling .collect()/.cache() between tasks, or serializing to/deserializing from external storage.
All this said, there are many tools to achieve scaling with Hamilton, and you might not need the full PySpark integration. To use Spark + Hamilton, You can also:
Run your map-level Hamilton pandas code in PySpark if you just want to execute a DAG of UDFs.
Run using pandas-on-spark if you wish to use the pandas-on-spark API to manage pandas dataframes in Spark.
Spark is not the only way to scale. Hamilton integrates seamlessly with Modin and Polars for other scalable computation that does not involve the PySpark API.
Moving Forward
Looking ahead, we’re really excited about the future of Hamilton with Spark. Up next are:
Better visualizations to represent the
@with_columnsgroup more naturallyEasy compilation/breaking up of Hamilton code into multiple tasks (E.G. Airflow jobs that run distinct subsets of your Hamilton DAG)
Similar integrations with other index-less dataframe APIs
If you’re looking to get started, clone the basic hello_world example, run it, and adapt it to your own case.
We want to hear from you!
If you’re excited by any of this, or have strong opinions, drop by our Slack channel / or leave some comments here! Some resources to get you help:
📣 join our community on Slack — we’re more than happy to help answer questions you might have or get you started.
⭐️ us on GitHub
📝 leave us an issue if you find something
Other Hamilton posts you might be interested in:
tryhamilton.dev – an interactive tutorial in your browser!