
Separate data I/O from transformation -- your future self will thank you.
How to build maintainable pipelines from dev to production




A Motivating Example
Imagine you just inherited a model training pipeline. You start digging through the code, and find something interesting… Each step saves and loads multiple dataframes to S3 — with hardcode file formats, buckets, and keys. Multiple steps in an Airflow DAG conduct complex ML training/feature engineering, then periodically save and load components. You have to dig through the code to figure out the location of the produced/consumed data. Migrating this to new infrastructure, file formats, privacy requirements, etc… requires locating and modifying code, which may or may not break your jobs in subtle ways.
If you’ve encountered this in the past, you’re not alone. Let’s dive into why these problems are so endemic in data code, and how we can avoid them.
On Code for Data
The term “ETL” (extract, transform, load) is overused in the data community for a reason. It represents the vast majority of code that anyone doing data engineering, data science, research, and ML engineering writes throughout their career.
Extract – pull some data from a source
Transform – process the data with the goal of extracting value
Load – throw the transformed version over the wall to someone else
Now, let’s imagine code you’ve seen that does this – it is responsible for a lot! Whether it lives within a jupyter notebook and gets haphazardly shipped to production, or comprises a well-structured component of an airflow DAG, it likely carries many, if not all, of the following responsibilities:
Extract
Load multiple datasets from disparate external sources
Conduct filters/joins in the data warehouse
Manage credentials/data permissioning
Load models (in the case of inference/retraining)
Load metrics, configuration, etc…
Transform
Filter data, remove outliers
Conduct in-memory joins of smaller datasets
Engineer features
Convert data to embeddings
Load
Save output data to a local file for analysis
Save output (training, evaluation, inference) data to the data warehouse
Populate some database
Put models in a model registry
Output metrics (both during and after model training)
And so on…
Now, let’s imagine two ways to build this:
Code is coupled – the logic for transformation is interspersed with the logic for I/O
Code is decoupled – the logic for transformation is fully separated from the logic for I/O
In this post, we argue that (2) is far superior to (1), and demonstrate how proper implementation can help speed up development of ML models from research to production. We utilize the open-source library Hamilton to build an end-to-end example of a production ML pipeline, and show how this approach can be extended to multiple infrastructure configurations as well as various disciplines/problem spaces (RAG with LLMs, data engineering, etc…).
The Benefits of Decoupling
Separate I/O from transformation logic will improve your pipelines, giving them:
Clearer, more legible, code
Portability across infrastructure/execution contexts
The primary aim behind both of these is to reduce cognitive burden of the developer and future maintainers when performing common tasks. Decoupling I/O from transformation is critical to improve clarity of code and reducing technical debt – when reading (and determining what to modify), data transformations are difficult enough without having to juggle the current state of the data and the infrastructure/sources. Coupling to a vendor API, for example, can make it quick to get something out, but in the medium-to-long-term is technical debt that burdens you and your team.
A migration across infrastructure, vendors, data sources, and execution contexts can be an involved task – one regularly has to juggle multiple integrations and build systems to work in a variety of settings. When migrating, the logic should generally remain the same, while the infrastructure, data sources, and execution context will often change. Decoupling will reduce the places one needs to look and the subsequent changes required to carry out a successful migration.
If you’ve done much work in data, you’ve probably come to the above conclusions on your own – nothing about this is particularly novel. Decoupling is just good software practice, and you have likely completed enough migrations/inherited enough code to understand the challenges of doing it wrong. The easy part of any software story, however, is knowing the right way to do it (and, subsequently, blogging about it). The hard part is doing it right from the start, in the real world. The rest of this post focuses on how to do just that. First, however, we want to introduce the library we’ll be using to build and manage our pipelines, Hamilton.
A Library for Structured Transformation
Hamilton is a lightweight tool for expressing dataflows in python. One represents an artifact (feature, loaded data, trained model, result of an external API call, etc…) as a plain old python function. The name of the function forms a pointer for the artifact it creates, and the parameter names correspond to feature dependencies (other artifacts or external inputs). You can request specific outputs, and Hamilton will execute just the dependencies required to produce them, by compiling those functions into a directed acyclic graph (DAG), and traversing them in the proper order.
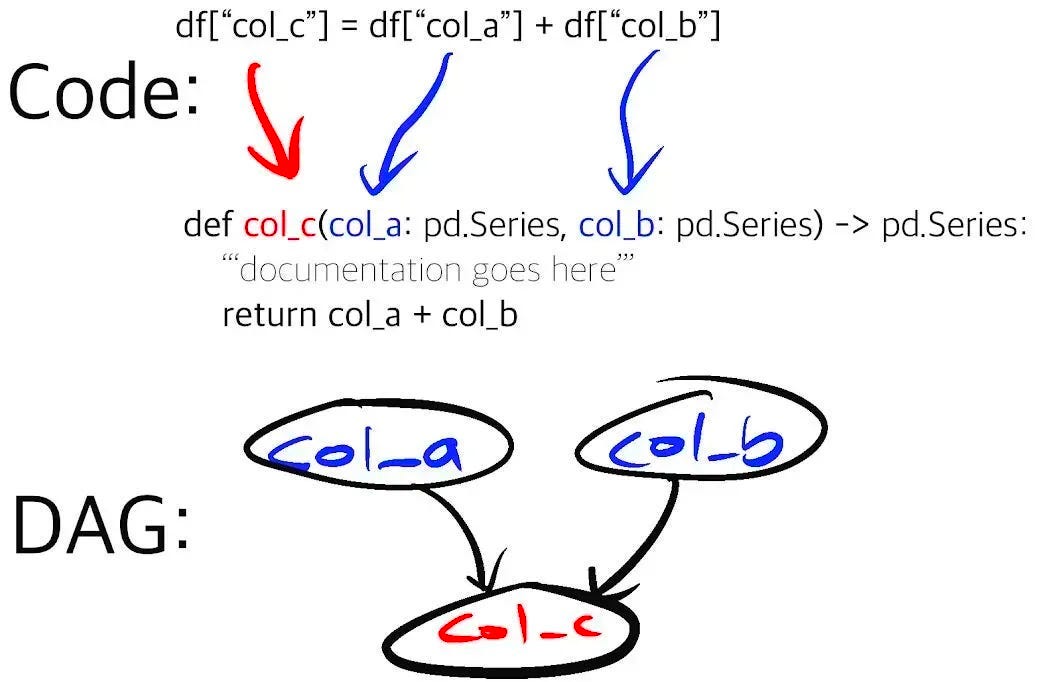
Hamilton is particularly well-suited towards constructing modular, reusable ML/LLM workflows that handle all aspects of ETLs – data loading, data transformation, and data saving. How can this help you write I/O code that’s fully decoupled from your transformation logic?
To explain, we need to introduce two Hamilton-specific concepts:
Drivers
Data adapters
Drivers
As Hamilton DAGs are constructed from python objects, they don’t actually *run* code. The driver is a tool that enables one to specify what code to run, and how. A driver loads up modules, compiles them into a DAG, and executes that DAG with a specified input and output.
Adapters
Data adapters are tools that one can use in Hamilton to express I/O – a wide range are available, and they are pluggable, meaning you can build your own. They can be applied in one of two ways:
(2) is the primary tool we will leverage to separate I/O from transformations. These get called in the following manner:
| dr = driver.Driver({}, ...) | |
| dr.materialize( | |
| from_.csv( | |
| target="node_to_load_to", | |
| path="./input_data.csv", | |
| ), | |
| to.csv( | |
| id="data_saving_node", | |
| dependencies=["col_1", "col_2", "col_"], | |
| path="./path.csv"), | |
| ) |
Developing ML Pipelines
Let’s build and productionize a model from a classic ML problem, predicting survival from the Titanic dataset. Assume we’ve done some of the essential base tasks – justified the business value, aligned the stakeholders (both N/A for this toy-example, but essential in general), and played around with the data. We sense that there is some correlation, and have a sneaking suspicion that a simple logistic regression model will work well, but want to leave the ability to switch out model/feature engineering capabilities without an entire rewrite.
To get this done, we’re going to develop backwards. Start from the outside, and work in. We will first specify:
The artifacts we need
The data we have
We’re going to use materializers to do this:
| materializers = [ | |
| from_.csv( | |
| path=source("location"), | |
| target="titanic_data" | |
| ), | |
| to.pickle( | |
| id="save_trained_model", | |
| dependencies=["trained_model"], | |
| path="./model_saved.pickle" | |
| ), | |
| to.csv( | |
| id="save_training_data", | |
| dependencies=["train_set"], | |
| combine=base.PandasDataFrameResult(), | |
| path="./training_data.csv", | |
| ), | |
| to.png( | |
| id="save_confusion_matrix_plot", | |
| dependencies=["confusion_matrix_test_plot"], | |
| path="./confusion_matrix_plot.png", | |
| ), | |
| ] | |
| dr.materialize( | |
| *materializers, | |
| inputs={"location": "./data/titanic.csv", "test_size": 0.2, "random_state": 42} | |
| ) |
As you can see, we have a few contracts we’ll need to adhere to:
We accept a dataset called `titanic_data` (given to us by a parameter “location”)
We output a model called `trained_model` (we save this to a pickle file locally, for later use)
We output `train_set` as datasets (we save these as files for post-hoc analysis)
We output/plot a confusion matrix on the test data set and save that to a file
Note that the contract is not set in stone – we can easily modify (add more inputs/ outputs). Furthermore, we can change the implementation of the contract, both by fleshing out the interior (how the data is processed and loaded), and by changing the location/format to which we save/write the outputs.
That said, a contract is a good place to start, and it allows us to break out our workflow into components. We will work step-by-step, writing each capability in a separate module, so we can easily layer them together.
First, let’s get the training set created – we will add functions that take our input data and:
Extract columns from it
Process those into features we might want
Split those into training/test sets
We now have a base set of features that we can use for our model, and have implemented a full path through from the input to the output!

We can actually run it, if we comment out the materializers relying on data that we have not yet produced. In a development/research scenario, we’d run it first, examine the saved data, and iterate on what we have. For now, however, let’s move ahead to adding model creation/training.

Finally, let’s add some plots – we can use the plotting materializer to output a confusion matrix.

And there we have it! An ETL for training a model. For the sake of brevity we will not delve into online inference, batch inference, hyperparameter selection, and many of the other common model productionization techniques. These are left as an exercise to the reader, that said, we’ll happily take contributions to Hamilton and this blog on those topics!
Moving Towards Production
Now that we’ve built our pipeline, let’s demonstrate the value of separating materialization from loading. Consider what we may want to do to make this “production-ready”:
Capture more metrics: Add the materializer for a plot, add the metric if necessary
Alter it to run on a production dataset: Create a new script that runs the driver, passing in another `from_.`. Alternatively, set it to accept a runtime parameter that determines the data source, if they’re in the same shape.
Save model/data to a permanent location instead of a local one: Save the model to a model registry, using an MLFlow/modelDB materializer.
Add integration tests: Pass data in directly to the driver, call execute() rather than materialize, make assertions on the results.
Alter any of the data stores/model registries: Simply change the materializer to the new location! And, if you want to transition slowly, you can always keep the old one in.
As we have our logic separated from I/O, the materializer API makes these all easier. These are primarily driver-side changes. One only has to know what “nodes” are available, and can modify their script that calls the driver with new materializers, or even create multiple scripts for different configurations. If you operate in a hand-off model, we’ve found this setup works quite well to keep areas of responsibility (e.g. data science vs engineering) separate.
Orchestration
One advantage of writing code as modular DAG components with detached I/O is the ability to seamlessly move between different execution platforms. For instance, say one starts on a small data set locally, then needs to break it up into tasks in the cloud to run on airflow (or prefect, dagster, metaflow, etc…) to read from a production dataset. This effort requires minimal refactoring. As materializers can also inject data, they have the capability to replace a node in the DAG and short–circuit upstream computation.
Thus, if you want the following high-level tasks
Generate training data, test data
Train the model
Evaluate the model on test data
Moving execution onto or between orchestration systems is as easy as a few driver calls. The only thing that changes between them is the nodes that we output, and the loaders we pass in (note you can also restrict the nodes that are run, but we won’t show that here). This is compatible with any manner of orchestration system that runs python.
For an example of how to integrate with these systems, see:
Extending Capabilities
Materialization in Hamilton is pluggable, meaning that you can write your own infrastructure-specific adapters, building off of the existing set. This means that you can:
Hide credential/ACL management
Manage data partitions in your warehouse according to a custom strategy
Add reasonable defaults that the data team can use
Add checks/assertions to ensure the data has a proper format prior to saving
And so on. These can form a specific library of I/O capabilities, enabling your team to move faster, write to/read from the right location, and not have to think about any of the standard “platform” concerns.
You can read more about data adapters/learn how to write your own in the documentation.
Furthermore, this strategy is applicable towards more than just typical ML problems. The approach of decoupling I/O from transformation is valuable regardless of the complexity of the data processing involved.
See the following for how you can apply this more generally:

And it is not hard to imagine more! In all of these cases, decoupling I/O from processing can be critical to quick development, and, often, can let you share code between them much easier.
Wrapping up
Decoupling I/O from transformations can help you in a variety of ways:
If you (or your colleague) has to migrate — you’ll spend far less time digging through code
You’ll be able to easily move between contexts, allowing for rapid local development and larger scale deployments
While it requires a little upfront thought — your future self will thank you!
We’ve tried to make this all easy with Hamilton, and are working towards a broader vision.
As a thought experiment, consider what it would look like if all the code you wrote was in a nicely decoupled format (say, perhaps, Hamilton…). You utilize a library of transforms to build clean, self-documenting pipelines, and have a separate assortment of materializers that get tacked onto the edges to bring your models to production. Once you buy into this paradigm, there’s a lot that you can do:
You can track how your data moves *between* flows, getting a sense of intra-, as well as inter-, DAG lineage
You can rerun any subset of your DAG in any context, allowing you to view the unified logic for an entire pipeline separately from how it is executed.
You could “compile” your DAG to any orchestration/execution system, allowing you to migrate systems with the press of a button, and automagically deploy a highly customized, complex model to conduct batch inference at scale, streaming predictions, and online inference.
This is our all on the roadmap with Hamilton – stay tuned for further progress!
We want to hear from you!
If you’re excited by any of this, or have strong opinions, drop by our Slack channel / leave some comments here! Some resources to help you get started:
📣 join our community on Slack — we’re more than happy to help answer questions you might have or get you started.
⭐️ us on GitHub
📝 leave us an issue if you find something
📈 check out the DAGWorks platform and sign up for a free trial
Other Hamilton posts you might be interested in:
tryhamilton.dev – an interactive tutorial in your browser!