
Lineage + Hamilton in 10 minutes
Spend less time debugging your pipelines by using Hamilton’s out of the box lineage capabilities.

Spend less time debugging your pipelines by using Hamilton’s out of the box lineage capabilities.

Hamilton is a general purpose open-source micro-framework for describing dataflows. It is great for data & Machine Learning (ML) work. In this post, we’re going to walk you through Hamilton’s lineage capabilities that can help you quickly answer common questions that arise while working with data & ML, so that you can work more efficiently and collaborate more effectively with colleagues. If you’re not familiar with Hamilton we invite you to browse the following:
www.tryhamilton.dev (interactive in the browser overview)
Introducing Hamilton (backstory and introduction)
Lineage
What do I mean by lineage you may ask? In the context of machine learning and data work, “lineage” refers to the historical record or traceability of data as it is transformed and manipulated into things like tables, statistical models, etc. Lineage helps one to determine the provenance, quality, and reliability of “data”, as it aids in understanding how data has been transformed.
Why you should care about lineage?
If you’re the author of what you have to manage, you probably have a fair idea how everything that you’ve written connects. But, for someone to inherit your work, or to bring on a collaborator, or having to debug something you wrote six months ago, getting up to speed can be a challenge! I’ve heard of teams taking over a quarter to understand work a colleague left behind (they’re obviously not using Hamilton)! In situations such as these, is where lineage can be a great help. To provide some more context, here are some common situations that result in lost productivity, general unhappiness, and even outages:
(a) debugging a data problem with your training set/model (that turned out to be an upstream data issue).
(b) trying to determine how someone else’s pipeline works (because you inherited it, or have to collaborate with them).
(c) having to fulfill an auditing requirement on how some data got somewhere (e.g. GDPR, data usage policies, etc.).
(d) wanting to make a change to a feature/column, but not having a good way to assess potential impacts (e.g. the business changed and so did data collected).
Practically speaking, most people working in data and machine learning don’t encounter or understand the value of having “lineage” because more often than not, it’s a headache to do well. Usually an external system is needed (e.g. open lineage, Amundsen, Datahub, etc), which then needs users to do extra work to populate it with information. The good news is, if you use Hamilton, there isn’t the need for another system to get lineage; making use of lineage is straightforward too!
Lineage as Code
With Hamilton, you do not need to add anything else, and you get lineage.
By virtue of writing code in the Hamiltonian way, you are defining computation within functions, and then specifying via function input arguments, how things connect, encoding lineage. Taking this code and connecting with e.g. a version control system (e.g. git), then also provides you with the means to snapshot lineage at points in time! Because you have to update code to change how computation operates, you, by definition, then update lineage without you having to do anything 😎.

At a high level the recipe for ‘Lineage as Code’ and then subsequently accessing it is:
Write Hamilton code & version it.
Instantiate a Hamilton Driver, it’ll then have a representation of how data and compute flow as defined by your Hamilton code. The Driver object can then emit/provide information on lineage!
Using your version control system, you can then go back in time to understand how lineage changes over time, since it’s encoded in code!
Adding metadata to make lineage more useful!
Lineage gets more useful, when you can also attach metadata to it. Hamilton by default enables you to express how things connect, but by attaching extra metadata, we can now connect business and company concepts via the lineage you have encoded with Hamilton.
For example, you can annotate functions that pull data with concerns such as PII, ownership, importance, etc., and annotate functions that create important artifacts, e.g. models, data sets, with similar information. With these functions now annotated, the set of questions lineage can answer is now much greater! Other systems, in contrast, require you to put this metadata somewhere else; a YAML file, a different part of the code base, or separately curate this information in some other place. Philosophically with Hamilton, we believe it makes the most sense to annotate the actual code directly, since that ensures that the source of truth of code & metadata is always up to date. With Hamilton, it’s easier to maintain both since there’s only a single place needed to make a change.
In Hamilton, the way to add extra metadata is through the use of the `@tag` and `@tag_outputs` decorators. They allow one to specify arbitrary string key-value pairs. This provides flexibility and the ability for you and your organization to define tags and values that make sense for your context.
For example, the following code adds a bunch of metadata to:
> The titanic_data function specifying its source, an owner, importance, contains PII, and links to some internal wiki.
> The age and sex columns, specifying that they are PII.
Note: I’m showing a slightly more complex example with multiple decorators just to show that things don’t get more complex than this — the code is still quite readable!
@tag_outputs(age={"PII": "true"}, sex={"PII": "true"})
@extract_columns(*columns_to_extract)
@tag(
source="prod.titantic",
owner="data-engineering",
importance="production",
info="https://internal.wikipage.net/",
contains_PII="True",
target_="titanic_data",
)
def titanic_data(index_col: str, location: str) -> pd.DataFrame:
"""Returns a dataframe, that then has its columns extracted."""
# ... contents of function not important ... code skipped for brevityWhile the following code helps provide more context from a business perspective on the model being created:
@tag(owner="data-science", importance="production", artifact="model")
def fit_random_forest(
prefit_random_forest: base.ClassifierMixin,
X_train: pd.DataFrame,
y_train: pd.Series,
) -> base.ClassifierMixin:
"""Returns a fit RF model."""
# ... contents of function not important ... code skipped for brevityWith this extra metadata now attached to functions and therefore lineage, we can use that as context to ask more useful questions. More on that below.
How to answer lineage questions with Hamilton
The basic mechanics of answering lineage questions relies on instantiating a Hamilton Driver, which under the hood creates a directed acyclic graph (DAG) to represent its view of the world, and then using the functions the Driver has. Let’s list the relevant Driver functions and what they do.
Visualizing lineage (i.e. displaying the DAG):
display_*() there are three display_* functions. One that helps you display how everything defined connects. Then a function to only visualize what’s upstream, and then one to visualize what is downstream of a given function/node.
visualize_execution() which helps visualize everything that is required to produce some outputs. Useful for displaying what
.execute()does.visualize_path_between() which helps visualize a path between two nodes.
Getting access to metadata for lineage needs:
list_available_variables() Enables one to get all the “functions/nodes” and access to their tags.
what_is_downstream_of() Enables one to get all the “functions/nodes” that are downstream of the one specified.
what_is_upstream_of() Enables one to get all the “functions/nodes” that are upstream of the one specified.
what_is_the_path_between() Enables one to get all the “functions/nodes” that comprise the path between two specified “functions/nodes”.
With Hamilton, using the functions above, you get programmatic access to lineage as well as visualizing it, which means that you can ask these questions in your CI systems, or in a notebook that uses the code that’s running in production, or anywhere that python runs!
To recap what we’ve talked about thus far, the general recipe to answer lineage questions is therefore as follows:
Write Hamilton code.
Use
@tagto annotate functions.Instantiate a Driver that creates your DAG.
Use the Driver functions to ask/answer questions.
To keep this post short, we won’t do an extensive deep dive into their use, we’ll just surface some general questions that you can answer in a straightforward manner with Hamilton, with some examples using the functions above. The toy problem we’ll be using is an end-to-end model pipeline in Hamilton that builds a model to predict Titanic survival; the code and more information can be found in the Hamilton repository’s Lineage example. Terminology side note: we use function and node interchangeably, since in Hamilton a function becomes a node in our visualizations.
(1) What sequence of operations produced this data/model?
This is a common question to ask, how do we get from A->B, where A can be some data, `->` is opaque to us, and B can be some artifact (either more data or a model/object).
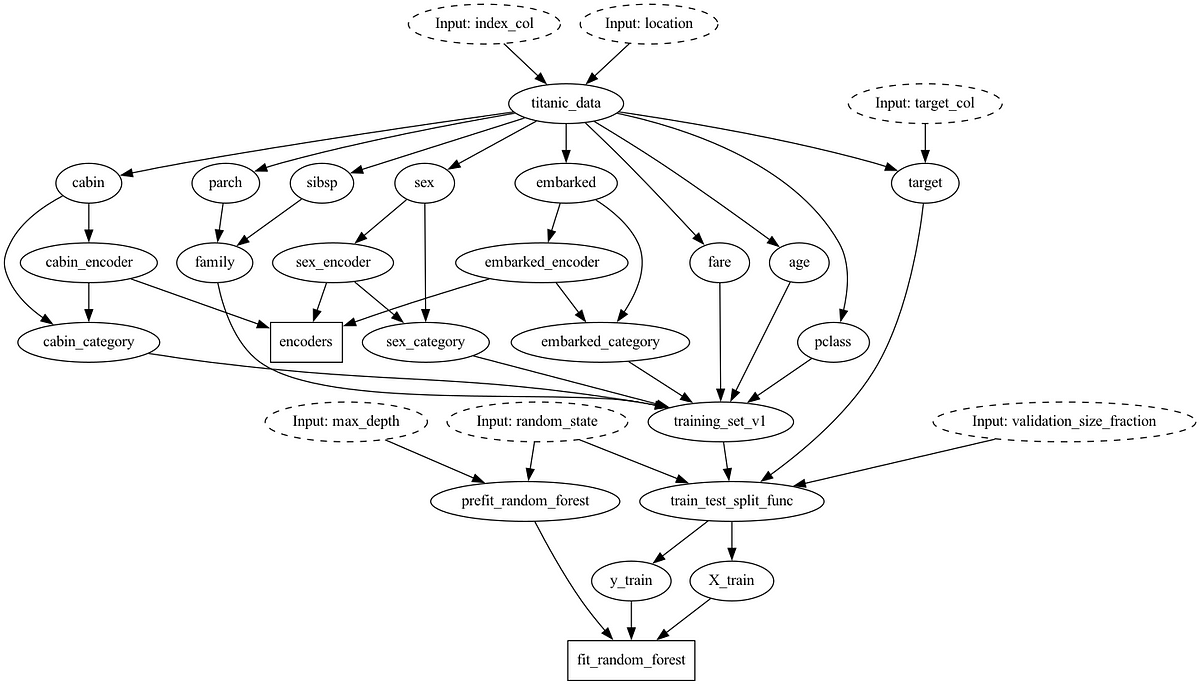
With Hamilton, by virtue of writing code in the style prescribed by Hamilton, you clearly and easily define the sequence of operations of what should happen and how it relates! So if you can’t answer the question by looking at the code itself, you can ask Hamilton for help. In the context of our example, to understand how say the feature_encoders are created, without knowing much about them at all, we can ask the Hamilton Driver to visualize how they’re created for us:
...
# create the driver
dr = driver.Driver(config, data_loading, features, sets, model_pipeline, adapter=adapter)
# visualize how it's created
dr.visualize_execution(
[features.encoders], "encoder_lineage", {"format": "png"}, inputs=inputs
)Which outputs:
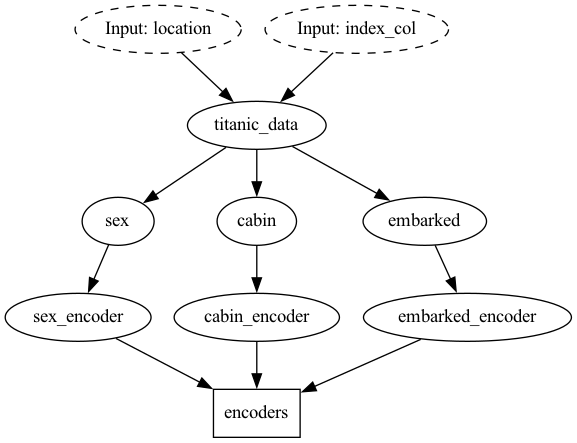
You can then pair this with walking through your code base to more easily navigate and understand what is going on.
(2) Whose/What data sources led to this artifact/model?
This is useful for debugging data issues, as well as understanding what teams and data sources an artifact/model depends on. For our Titanic example, say there is something funky with our Random Forest model and we want to double check, for the current production model, what the data sources are and who owns them so we can go ping them. To determine this, we can write the following code:
# create the driver
dr = driver.Driver(config, data_loading, features, sets, model_pipeline, adapter=adapter)
# Gives us all the operations that are upstream of creating the output.
upstream_nodes = dr.what_is_upstream_of("fit_random_forest")The above two lines create a Driver, and then pull all upstream nodes of fit_random_forest . Then we can iterate through the nodes and pull the information we want:
teams = []
# iterate through
for node in upstream_nodes:
# filter to nodes that we're interested in getting information about
if node.tags.get("source"):
# append for output
teams.append({
"team": node.tags.get("owner"),
"function": node.name,
"source": node.tags.get("source"),
})
print(teams)
# [{'team': 'data-engineering',
# 'function': 'titanic_data',
# 'source': 'prod.titanic'}] (3) Who/What is downstream of this transform?
Answering this question is effectively the complement of (2). You commonly encounter it when someone wants to make a change to a feature, or a data source. Using our Titanic example, say we’re on data engineering and want to change the source data. How could we determine what the artifacts that use this data are and who owns them?
We use the what_is_downstream_of() Driver function to get nodes that are downstream:
# create the driver
dr = driver.Driver(config, data_loading, features, sets, model_pipeline, adapter=adapter)
# Gives us all the operations that are upstream of creating the output.
downstream_nodes = dr.what_is_downstream_of("titanic_data")Then analogously like in (2), we just loop through and pull out the information we want:
artifacts = []
for node in downstream_nodes:
# if it's an artifact function
if node.tags.get("artifact"):
# pull out the information we want
artifacts.append({
"team": node.tags.get("owner", "FIX_ME"),
"function": node.name,
"artifact": node.tags.get("artifact"),
})
print(artifacts)
# [{'team': 'data-science', 'function': 'training_set_v1', 'artifact': 'training_set'},
# {'team': 'data-science', 'function': 'fit_random_forest', 'artifact': 'model'},
# {'team': 'data-science', 'function': 'encoders', 'artifact': 'encoders'}](4) What is defined as PII data, and what does it end up in?
With regulations these days, this is becoming a more common question that needs to be answered. Building off of the above, we can combine a few Driver functions to answer this type of question.
In the context of our Titanic example, let’s say our compliance team has come to us to understand how we’re using PII data, i.e. what artifacts does it end up in? They want this report every month. Well, with Hamilton we can write a script to programmatically get lineage information related to PII data. To start we need to get everything marked PII:
# create the driver
dr = driver.Driver(config, data_loading, features, sets, model_pipeline, adapter=adapter)
# using a list comprehension to get all things marked PII
pii_nodes = [n for n in dr.list_available_variables()
if n.tags.get("PII") == "true"]Then to get all artifacts that are downstream, we just need to ask for all nodes that are downstream, and then filter to ones with the “artifact” tag:
pii_to_artifacts = {}
# loop through each PII node
for node in pii_nodes:
pii_to_artifacts[node.name] = []
# ask what is downstream
downstream_nodes = dr.what_is_downstream_of(node.name)
for dwn_node in downstream_nodes:
# Filter to nodes of interest
if dwn_node.tags.get("artifact"):
# pull out information
pii_to_artifacts[node.name].append({
"team": dwn_node.tags.get("owner"),
"function": dwn_node.name,
"artifact": dwn_node.tags.get("artifact"),
})
print(pii_to_artifacts)
# {'age': [{'artifact': 'training_set',
# 'function': 'training_set_v1',
# 'team': 'data-science'},
# {'artifact': 'model',
# 'function': 'fit_random_forest',
# 'team': 'data-science'}],
# 'sex': [{'artifact': 'training_set',
# 'function': 'training_set_v1',
# 'team': 'data-science'},
# {'artifact': 'encoders', 'function': 'encoders', 'team': None},
# {'artifact': 'model',
# 'function': 'fit_random_forest',
# 'team': 'data-science'}]} Can I get this in my notebook/IDE?
Some of you might be thinking why not have this type of lineage view as you develop? Great idea! Since we’re an open source project we’d love some help here; if you’re interested in testing/contributing, we have an alpha version of a VSCode extension, started by Thierry Jean, that can help you visualize lineage as you type. We’d love contributions.

To finish
With Hamilton, your code defines lineage. This means you get lineage out of the box without the need for another system, and when coupled with a version control system and extra metadata, a very straightforward and lightweight means to understand how data & code connect.
Hamilton enables programmatic access to the lineage and metadata you encode, which enables you to place this in CI jobs, scripts, or anywhere that python runs.
I hope you enjoyed this quick overview, and if you’re excited by any of this or want more resources, here are some links:
📣 join our community on slack — we’re more than happy to help answer questions you might have or get you started.
⭐️ us on github.
📝 leave us an issue if you find something.
📚 browse our documentation. E.g. see lineage section.
▶️ learn Hamilton with a tutorial directly in your browser .
Other Hamilton posts you might be interested in:
Developing scalable feature engineering DAGs (Hamilton with Metaflow)
The perks of creating dataflows with Hamilton (Organic user post on Hamilton!)