
Enterprise Ready Data Pipelines with Hamilton
A collection of recipes for building enterprise data (data ⊇ ML ⊇ LLM) pipelines


Instructions for reading
This forms another reference architecture post, following our writeup on building Machine Learning (ML) pipelines with Hamilton (which is not required to read beforehand). This is separated into two pieces:
An overview of what we mean by enterprise needs, Hamilton, and some tools that might be useful
Implementations/recipes for the needs outlined in (1) (see the Solutions section)
We recommend reading through to the Solutions section, then skimming over/diving into the specific parts of the solutions themselves that you find relevant. Bookmark for later reference as you face the problems we outline.
General data processing, Machine learning (ML), and Large Language Model/GenAI pipelines all fall under the umbrella of what we’re describing as “data pipelines”. We wrote this post for anyone building (or working closely with) those pipelines, regardless of vertical.
If you do not have enterprise needs, you will likely still find these recipes useful, both for future work and for understanding the problem space. That said, you may also want to read through our Machine Learning reference architecture post – this outlines multiple other points along the trade-off curve, providing a variety of “recipes” as well to build out more sophisticated Machine Learning pipelines.

What type of builder are you?
Not everyone has the same requirements, especially in the world of data pipelines. Discrepancies between use-cases is something we think about regularly as the creators and maintainers of Hamilton, an open-source library used to express pipelines at a variety of environments, ranging from startups with a single-person data team to ML consultants to multinational enterprises who need to enforce structure and build code to last.
In a recent post, we discussed the trade-off between moving quickly and building reliably. We represented these as an “efficient frontier” and proposed a few solutions showing how using Hamilton can help change the shape of the curve by unlocking simpler to implement solutions, and help you move along the curve should your requirements change.

For this post, we will focus on the right side of the curve, illustrating how you can use Hamilton to reshape the curve towards more enterprise needs without sacrificing much, if any speed. We will:
Cover the basics of Hamilton
Talk about what differentiates enterprise requirements
Present a few recipes that aim to solve those requirements while simultaneously enabling a team to move faster (thus changing the shape of the curve)
Before we dive deeper, we want to clarify – while Hamilton is opinionated about some aspects of how you write code, the approaches outlined in this post are not prescriptive of how you should be using Hamilton. We believe that Hamilton can help individuals and teams along any point of this trade-off curve; use Hamilton to move notebook code quickly, then progress that code to handle more enterprise concerns.
Enterprise Needs
While everyone building data pipelines cares about the following:
Quickly moving from development to production
Writing code that won’t break and that is easy to read
Enabling fast production iteration cycles
Monitoring/evaluating production code with ease
Enterprises carry additional concerns. These generally fall into three buckets, which an enterprise has to balance. While you will likely identify with quite a few of the following regardless of your work environment, the combination of so many is what differentiates an enterprise mindset. Let’s dig into the overview of problems from an individual, team, and company perspective, then walk through some solutions.

Individual Needs
An enterprise is made of individuals, all of whom want to be able to move fast and productively, ensure job growth, get promoted, and enjoy a satisfying day-to-day job. Doing so can be tricky in an enterprise setting – large organizations have a tendency to build complex structures that slow people down and frustrate them1. A key part of the need of an enterprise platform (such as we’re outlining in this post) is to allow individuals to move quickly when working with their company’s data and APIs.
In particular, they will need to:
Read/write data to/from common sources
Manage credentials
Plug into infrastructure on which to run pipelines
Scale up compute
Track/manage offline and online experiments
Ensuring high-quality data
While individuals should be thinking on a team -> company level regularly (and quality enterprises will set up incentives accordingly), the needs above are most directly related to unblocking promotions/career growth.
Team Needs
Enterprises are often composed of multiple data teams. While these teams aim to ensure their individuals are productive, they also have a set of concerns that arise frequently when thinking at the team level. These involve:
Onboard new members/reducing bus factor
Know what artifact a team owns in production, e.g. models
Understand data lineage/connect data consumers to producers (to manage stakeholder/vendor relationships)
Easily manage and migrate data sources to ensure uniformity and reduce technical debt across a team
Manage on-call/debugging
Company Needs
At a company level, there are a host of risk management/inter-team productivity concerns that dominate. In particular, these end up breaking down into legal/compliance concerns, security concerns, and ensuring team orthogonality. Among many, these include
Ensure compliance to GDPR/CCPA/giving required information
Trace usage of datasets to satisfy (1) or for general data set discovery and inter-team dependencies
Track the set of models in production for usage auditing and license compliance
Track libraries used, and know if any have vulnerabilities
Report on cost
Before we dig into some tools in Hamilton that can help you with the concerns above, let’s give a brief overview of the Hamilton library.
Hamilton
If you are more of a learn-by-doing type, we recommend spending a few minutes on tryhamilton.dev to grok the following concepts, then skipping ahead to the next section.
Hamilton is a standardized way to build dataflows (any code that processes data) in python. The core concepts are simple – you write each data transformation step as a single python function, with the following rules:
The name of the function corresponds to the output variable it computes.
The parameter names (and types) correspond to inputs. These can be either passed-in parameter or names of other upstream functions.
# simple_pipeline.py
def digits_df() -> pd.DataFrame:
"""Load the digits dataset."""
digits = datasets.load_digits()
_digits_df = pd.DataFrame(digits.data)
_digits_df["target"] = digits.target
return _digits_df
def digits_model(digits_df: pd.DataFrame) -> svm.SVC:
"""Train a model on the digits dataset."""
clf = svm.SVC(gamma=0.001, C=100.)
_digits_model = clf.fit(
digits_df.drop('target', axis=1),
digits_df.target
)
return _digits_model
def predicted_digits(
digits_model: svm.SVC,
input_digits: pd.DataFrame) -> pd.Series:
"""Predict the digits."""
return pd.Series(digits_model.predict(input_digits))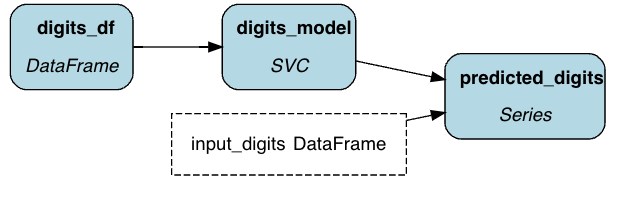
Together, Hamilton turns the functions into a Directed Acyclic Graph (DAG) for execution. To actually run the code, you instantiate a driver. You tell the driver what you need and it will run only the required functions.
from hamilton import driver
import simple_pipeline
dr = driver.Driver({}, simple_pipeline)
result = dr.execute(
[
"predicted_digits", # this is what we're requesting to be computed
],
inputs={"input_digits": load_some_digits()}
)As Hamilton is simply a way of organizing your code into a graph of functions, you can use it anywhere well-organized code is valuable (everywhere), and logic can be modeled with a DAG (most applications that manage the movement of data/objects). We’ve seen it used in contexts ranging from ML pipelines to LLM apps/RAG pipelines to implementations of microservices and data engineering workflows.
Customizing Hamilton
The key to meeting enterprise needs with Hamilton is to treat it as a layer on top of which you can build your platform. While we won’t go into too much detail of the customization capabilities, it will be beneficial to walk through a few concepts that make Hamilton a highly versatile and customizable layer. We’ll be referring back to these throughout the rest of the post, so you can skim over then use this section as an index/reference if you need a refresher.
Lifecycle Adapters
Lifecycle adapters are a flexible API that define a set of callbacks Hamilton uses in execution. You implement these by subclassing predefined APIs and passing instantiations of those classes to the driver. There are quite a few, but the most important ones for this post are:
In the following case, we’re implementing two methods (run_before_node_execution and run_after_node_execution) in a NodeExecutionHook, which gets passed to the driver and called before and after node execution.
class ExampleHook(NodeExecutionHook):
def run_before_node_execution(
self,
*,
node_name: str,
**future_kwargs: Any
):
print(f"running: {node_name}")
def run_after_node_execution(
self,
*,
node_name: str,
**future_kwargs: Any
):
print(f"ran: {node_name}")
dr = driver.Builder().with_modules(...).with_adapters(ExampleHook())
dr.execute(...)We’ve used these to implement a progress bar, an interactive debugger, and a datadog integration (blog). For the sake of this post, all you need to know is that, to customize Hamilton’s execution (and do things with node/graph data), you can implement any number of these adapter classes and pass them into the driver. To read more, check out our recent writeup.
Materializers
Materialization is an API that allows you to centralize data loading/saving and abstract it from the user. There are two different ways to use it – through decorators on functions or the .materialize() call in the driver.
The decorator approach — we load training_data from a CSV (with the path specified by another node/input parameter named training_data_path) and save test_predictions in parquet format to the path ./predictions.parquet.
from hamilton.function_modifiers import load_from, save_to, source, tag
@load_from.csv(path=source("training_data_path"))
def trained_model(
training_data: pd.DataFrame,
hyperparameters: dict
) -> Model:
return Model(**hyperparameters).train(training_data)
@save_to.parquet(path="./predictions.parquet", id="save_predictions")
def test_predictions(
trained_model: Model,
test_features: pd.DataFrame
) -> pd.DataFrame:
return trained_model.predict(test_features)The driver approach — we do the same as above, but in a more ad-hoc manner:
dr.materialize(
from_.csv(
target="training_data",
path=source("training_data_path")),
to.parquet(
path="./test.parquet",
id="save_predictions",
dependencies=["test_predictions"])
)Materializers are registered, either by the framework, a plugin, or custom user-code. To write a materializer, all you have to do is implement the DataLoader or DataSaver classes, then register the class you just wrote. Note that data loaders return the data that was just loaded in addition to any metadata related to data loading.
from hamilton.io import materialization
from hamilton import registry
@dataclasses.dataclass
class CustomDataLoader(materialization.DataLoader):
"""Custom data loader that takes in a URI"""
uri: str
@classmethod
def applicable_types(cls) -> Collection[Type]:
return [pd.DataFrame]
@classmethod
def name(cls) -> str:
return "my_custom_loader"
def load_data(
self,
type_: Type[Type]
) -> Tuple[pd.DataFrame, Dict[str, Any]]:
return (
_my_custom_loading_function(self.uri),
{"uri": self.uri, **other_metadata}
)
registry.register_adapter(CustomDataLoader)
dr.materialize(
from_.my_custom_loader(
uri="...",
target="input_name_of_data_to_load")
)
)The data adapters API defines loaders/savers partitioned by two things:
A name (E.G. csv, parquet, s3)
The data type (E.G. pandas/polars DataFrame, dict, etc…)
Thus when referenced by name (E.G. to.csv, from_.parquet), Hamilton decides which loader/saver to call for a specific data type, by looking up adapters registered with that name. If multiple data savers/loaders have been registered that apply for that (name, data type) pair, it will always pick the most recently registered implementation (allowing you to override default behavior by registering after the fact). See the documentation on using data adapters for more information.
Typically, a set of materializer implementations form a platform, i.e. a centralized way, for loading/saving data. While investing heavily in this layer can be overkill in an individual or startup environment, it becomes critical in an enterprise setting due to the complexity of loading/saving data and the need to make migration to new data sources/upgrading I/O approaches easy.
Tagging Nodes
The user can tag nodes with metadata, specifying key/value pairs. While the tag keys are largely free-form, one can impose structure by namespacing keys with a “.”, enabling a hierarchical approach. Keys always take the form of strings, and values either string or list-of-strings (which indicate multiple values). Tagging nodes is done at definition time by decorating the associated function:
@tag(
owner="my_team_name",
region=["US", "UK"],
compliance_properties=["pii"],
data_produce="my_data_product",
)
def some_dataset(input_data: DataFrame) -> DataFrame:
...They are commonly used for a wide array of situations, including:
Marking nodes as included in a specific data product
Marking nodes as owned by some team/related to some initiative
Connecting arbitrary metadata to nodes for documentation/compliance reasons
You can access/search by tags using the list_available_variables method on the driver, which accepts a query (in the form of a dictionary) and returns a list of objects that have associated tags as metadata. To read more about tags, see the documentation.
While Hamilton has a variety of other customization capabilities, the above three (lifecycle adapters, materializers, and tags) will be particularly important in this post.
Solutions
Let’s go over recipes to meet the needs we outlined above. Note that these are not meant as fully-functioning, out-of-the-box examples. Rather, we intend them to give you a starting point, ensuring that the more abstract concepts we present are grounded in reality (code!), and help you avoid blank-page syndrome when starting your enterprise integration. They may gloss over an implementation of a function or two (usually as that would vary depending on implementation), and often use simplifying assumptions. Furthermore, there are often cases in which you’ll see two possible implementations for similar problems — Hamilton is highly customizable, and we aim to highlight the trade-offs.
Individual Needs
Read/write data to/from common sources
When a team is small, it is quite reasonable to perform s3 queries as part of your python code, load data from postgres, manipulate it in memory, save it out to another s3 bucket, have another pipeline that pulls from that bucket, manipulate it further…
In reading this (contrived, yet surprisingly realistic) chain of data movement, you’ve probably already lost count of the steps. At a large organization, this all gets more confusing – adding in tables consumed by other teams with strict SLAs, contracts that may (or may not) be written down, shared compute resources that need to load data in a specific way, and so on.
For an individual contributor (IC), thinking about all of that at once can be a headache, and quite likely counter-productive towards their goal of quickly getting a pipeline to production. The key to reducing cognitive burden is providing the proper layer of abstraction. The bare minimum is a tool to read and write data to the various sources in a way that is platform-approved (meaning that it will work, work the same for everyone, and not carry negative externalities). Once you have a unifying I/O layer, the movement of data becomes more like lego bricks, allowing the IC to quickly assemble their pipelines. This is where materializers come in handy.
As we discussed before, materializers provide a level of abstraction between the code reading/writing the data and the user’s intention. While a data loading and saving library (often multiple) can form some sort of abstraction layer, materializers afford a much-needed level above due to the ability to consciously architect and simply express I/O. They allow for:
Easy loading – a simple statement to load data from a source through a unified API
Behind-the-scenes flexibility – a platform team can always change the way data is loaded
Lineage and metadata tracking (more later on)
Furthermore they can easily call out to any custom I/O tooling you’ve already built, enabling easy migration. In the following example we implement a data loader that delegates to an existing library:
from hamilton.io import materialization
@dataclasses.dataclass
class WrapExistingIOLibrary(materialization.DataLoader):
query: str # SQL query
database: str #
def load_data(
self,
type_: Type[Type]) -> Tuple[pd.DataFrame, dict]:
df = my_library.query(
db=self.database,
query=self.query)
return (
df,
{
"query": self.query,
"db": self.database,
"num_rows": len(df)
}
)
@classmethod
def applicable_types(cls) -> Collection[Type]:
return [pd.DataFrame]
@classmethod
def name(cls) -> str:
return "my_source_name"
registry.register_adapter(WrapExistingIOLibrary)
dr = driver.Builder().with_modules(...).build()
dr.materialize(
from_.my_custom_loader(
query="SELECT * FROM my_table",
database="my_teams_research_data",
target="input_name_to_load_to",
),
to.somewhere(...)
)Manage credentials
A wise engineer once told me they live by the CREAM acronym – credentials rule everything around me. This is because managing credentials is difficult. Enterprises often deal with systems that need to talk to each other and are heavily locked down. While Hamilton is not a credentials management system (nor does it have an associated one), it can help solve some common problems with credentials. A few things that can give people headaches:
Ensuring that a proper environment variable is set for access
Acquiring a set of credentials through a secrets manager
Ensuring a sidecar exists when running your dataflow to allow external API calls to a certain service
An important aspect in building a platform is to help shift left, ensuring that productivity-decreasing failures happen as quickly as possible before they get to production. In this case, that means reducing the cognitive burden of managing credentials while automating when possible and failing quickly (with good error messages) otherwise. We have observed a few common approaches using Hamilton:
A common “configuration” module to load up any secrets needed
In this example, secrets.py is a configuration module (to be added to the list of hamilton modules at driver instantiation) by anyone who needs secrets.
# secrets.py
@extract_fields({
"snowflake_username": str,
"snowflake_password": str,
"snowflake_account": str
})
def snowflake_credentials() -> dict:
# delegate to a secrets manager
return _load_secrets(
"snowflake_username",
"snowflake_password",
"snowflake_account"
)
# data.py
def connection(snowflake_credentials: dict, db: str) -> Connection:
return _create_snowflake_connection(**snowflake_credentials, db=db)A pre_graph_execute hook to set environment variables
We do something similar to the above, except we pass data through environment variables. This is useful in the case that a library/tool expects secrets to be set as part of the environment.
class CredentialsSetupHook(GraphExecutionHook):
def run_before_graph_execution(self, **future_kwargs: Any):
secrets = _load_secrets(
"snowflake_username",
"snowflake_password",
"snowflake_account")
os.environ["SNOWFLAKE_USERNAME"] = secrets["snowflake_username"]
os.environ["SNOWFLAKE_PASSWORD"] = secrets["snowflake_password"]
os.environ["SNOWFLAKE_ACCOUNT"] = secrets["snowflake_account"]
def run_after_graph_execution(self, **future_kwargs: Any):
del os.environ["SNOWFLAKE_USERNAME"]
del os.environ["SNOWFLAKE_PASSWORD"]
del os.environ["SNOWFLAKE_ACCOUNT"]Environment validations within materializers themselves
In this case we simply build a better materializer by ensuring that the environment variables (as demonstrated above) are set — this allows the user to know what to change before they hit a credentials error. Note that this is purely demonstrating the usefulness of enabling materializers to centralize code — clear/actionable errors make code better, regardless of whether it is written using Hamilton. This would work well with the pre_graph_execute hook above.
@dataclasses.dataclass
class SnowflakeLoader(materialization.DataLoader):
query: str
conn: Connection
def load_data(
self,
type_: Type[Type]
) -> Tuple[pd.DataFrame, dict]:
for key in [
"SNOWFLAKE_USERNAME",
"SNOWFLAKE_PASSWORD",
"SNOWFLAKE_ACCOUNT"]:
assert key in os.environ, (
f"Environment variable: {key} is not set. "
"Please ensure it is set by using the "
"CredentialsSetupHook! You can do this by..."
)
return _query_snowflake(...)
@classmethod
def applicable_types(cls) -> Collection[Type]:
return [pd.DataFrame]
@classmethod
def name(cls) -> str:
return "snowflake" Plug into execution infrastructure
Enterprise data pipelines need to work across a variety of different contexts. For instance, you may want to:
Run your dataflow locally to debug
Run an abbreviated version of your pipeline on gitlab and ensure the data looks reasonable as an integration test
Run a staging and/or production context on airflow
Run feature engineering as a final step of an analytics pipeline
And so on… Furthermore, some organizations move through multiple orchestration/execution systems before settling on a stable implementation. Making it easy to write code that is portable is key to ensuring that an IC does not spend the majority of their time writing if/else statements for each context (or, let’s be real, throwing up their hands and running it only in production, or never migrating to the new system).
While a python script is often a reasonable layer of abstraction, it does not encapsulate the structural differences between contexts. In particular, Hamilton can help an IC:
Run only specific parts of the pipeline
In this example, we define our data loaders separate from our data processing. In production, we use the data_loaders.py module to load/clean our data, whereas we pass in sample (already-cleaned) data in development, and do not include the data processing module.
# data_loading.py
@load_from.csv_s3(uri=source("training_data_uri"))
def cleaned_data(
loaded_data: pd.DataFrame
) -> pd.DataFrame:
return _clean_data(data)
# data_processing.py
def filtered_data(data: DataFrame) -> DataFrame:
return data.where(...)
def feature_data(filtered_data: DataFrame) -> DataFrame:
return _process_features(filtered_data)
# run.py
production_driver = (
driver
.Builder()
.with_modules(data_loading, data_processing)
.build()
)
features_prod = production_driver.execute(["feature_data"], inputs={})
test_driver = (
driver
.Builder()
.with_modules(data_processing)
.build()
)
features_test = test_driver.execute(
["feature_data"],
inputs={"loaded_data": _generate_test_data(...)}
)Load data from different locations in different environments
We can use materializers along with config.when to enable loading from different sources along with the driver — just remember to pass the right config into the driver (as shown below)
# data_loading.py
from hamilton.function_modifiers import config, load_from
@load_from.csv(path="local_data.csv")
@config.when(env="dev")
def cleaned_data__dev(loaded_df: pd.DataFrame) -> pd.DataFrame:
# clean, test data in dev
return loaded_df
@load_from.csv_s3(uri=source("training_data_uri"))
@config.when(env="prod")
def cleaned_data_prod(loaded_df: pd.DataFrame) -> pd.DataFrame:
return _clean_data(loaded_df)
# run.py
dr_dev = (
driver
.Builder()
.with_modules(data_loading)
.with_config({"env" : "prod"})
.build()
)
dr_prod = (
driver
.Builder()
.with_modules(data_loading)
.with_config({"env" : "dev"})
.build()
)A few other tools (such as overrides) can also help with ad-hoc testing/running subsets of the DAG.
Once we make use of the capabilities presented above, we often package it into a simple script (run.py is the name we commonly use). This allows it to be run from anywhere that runs python (and, if run.py is composed of functions, imported and then run). You can see examples of integrating Hamilton into multiple runtimes:
While python functions/scripts are the touch-points in these integrations, it would be straightforward to build a custom airflow operator, a fastAPI endpoint generator, or a tool for your own custom workflow orchestration system for the purpose of providing an ergonomic API to run a subsection of a Hamilton DAG. We have left the details of this out, but reach out if you’re curious – we’re happy to point you in the right direction or write another post on specific customizations.
Scale up compute
While dealing with big data is not strictly a large-company concern, most large companies will have to deal with scaling at some point. In particular, they will often prove out a concept on a toy dataset/smaller set of dimensions before ramping up to the real need. The act of scaling itself can often be a make-or-break in adding value to the organization. While Hamilton does not provide its own scaling capabilities, the abstraction it presents does make it easier to move from small -> medium -> large scale by delegating to python libraries that handle scaling well. While there is rarely a one-size-fits-all solution to dealing with big data, let’s outline a few common problems and how to use Hamilton constructs to solve them. Note that get a bigger machine or use a faster/more efficient library are both reasonable approaches to scaling (to an extent) – as Hamilton is infrastructure/library agnostic it is perfectly compatible.
Transform features on larger datasets
In this example we use the @with_columns decorator to apply a set of row-based UDFs written in pandas to a dataset that get executed in topological order on a spark dataframe.
import pandas as pd
import pyspark.sql as ps
from hamilton.plugins import h_dask, h_spark
def raw_data() -> ps.DataFrame:
return ...
def feature_1(column_1_from_df: pd.Series) -> pd.Series:
return ...
def feature_2(column_2_from_df: pd.Series) -> pd.Series:
return ...
def feature_3(feature_1: pd.Series, feature_2: pd.Series) -> pd.Series:
return ...
@h_spark.with_columns(
feature_1,
feature_2,
feature_3,
columns_to_pass=["column_1_from_df", "column_2_from_df"]
)
def df_with_features(raw_data: ps.DataFrame) -> ps.DataFrame:
return raw_dataDelegate model training/data processing to external compute
This example defines a decorator @requires_resources that indicates that a certain amount of GPU/CPU is required for a task. We use apower-user featurein Hamilton to (a) assign the right executor to the task, and (b) delegate to our favorite resource-aware executor/scheduler combination, such as modal or ray.
def requires_resources(
gpu: int = None,
cpu: int = None,
memory_gb: int = None
):
return tag(
requires_gpu=str(gpu),
requires_cpu=str(cpu),
requires_memory_gb=str(memory_gb)
)
# model_training.py
def training_data() -> pd.DataFrame:
return _load_data(...)
@requires_resources(gpu=2, cpu=10)
def train_model(training_data: pd.DataFrame) -> Model:
... # train your model with a big machine
class DelegatingExecutionManager(ExecutionManager):
def __init__(self, remote_executor: TaskExecutor):
self.local_executor = SynchronousLocalTaskExecutor()
self.remote_executor = remote_executor
super().__init__([self.local_executor, remote_executor])
def get_executor_for_task(
self,
task: TaskImplementation) -> TaskExecutor:
for node in task.nodes:
if "required_cpu" in node.tags\
or "required_gpu" in node.tags:
return self.remote_executor
return self.local_executor
class RemoteExecutor(TaskExecutor):
def submit_task(self, task: TaskImplementation) -> TaskFuture:
required_cpu, required_gpu, required_memory_gb = 0, 0, 0
for node in task.nodes:
required_cpu = max(
int(node.tags.get("required_cpu", "0")),
required_cpu
)
required_gpu = max(
int(node.tags.get("required_gpu", "0")),
required_gpu
)
return TaskFutureWrappingPythonFuture(
modal_or_ray_or_something_else.submit(
cpu=required_cpu, gpu=required_gpu)
)
# a few methods left out for brevity
# run.py
dr = (
driver
.Builder()
.with_modules(model_training)
.enable_dynamic_execution()
.with_execution_manager(
DelegatingExecutionManager(RemoteExecutor()))
.build()
)Scale pandas to a much bigger dataset
In this case we use Hamilton’s GraphAdapter capabilities (which are an extension of lifecycle adapters) to delegate Hamilton’s execution to a dask distributed dataset.
from dask.distributed import Client, LocalCluster
cluster = LocalCluster()
client = Client(cluster)
graph_adapter = h_dask.DaskGraphAdapter(
client,
h_dask.DaskDataFrameResult(),
use_delayed=False,
compute_at_end=True,
)
dr =(
driver
.Builder()
.with_modules(...)
.with_adapters(graph_adapter)
.build()
)Note that one can also do this with a tool such as Modin, that aims to be a drop-in, highly scalable replacement for pandas.
Track experiments
Not only do ICs often have to switch between multiple projects, but they also have to track/share the results of those projects, or pick up projects to iterate on something in production that they stopped working on months ago. As models they release can have large impacts, tracking results and being able to explain/justify decisions is critical.
This tracking/justification is a source of considerable stress (and considerable time) for most. High-caliber data scientists will often self-impose some structure on the work they do to ensure that everything is logged, tracked, and managed. While Hamilton is not, in itself, an experimentation manager, it does make it easy to log data to one, and switch between (or log to multiple).
One can make logging to an experimentation manager/model registry (whether it be MLFlow, W&B, or a custom one) with materializers or hooks.
Using materializers for experiment management affords the following two advantages:
Abstract away the way the model is registered
Make it easier to migrate by keeping the model registry decoupled from the model construction
As you can see, we implement an MLFlow materializer below that forms a (slightly opinionated) approach to calling out to MLFlow.
@dataclasses.dataclass
class MLFLowSaver(DataSaver):
"""Our MLFlow Materializer"""
experiment_name: str
model_type: str # e.g. "pyfunc", "sklearn", "spark", ...
artifact_path: str
run_name: str = None
@classmethod
def applicable_types(cls) -> Collection[Type]:
return [object]
@classmethod
def name(cls) -> str:
return "mlflow"
def save_data(self, model: object) -> Dict[str, Any]:
mlflow.set_experiment(self.experiment_name)
# Initiate the MLflow run context
with mlflow.start_run(run_name=self.run_name) as run:
ml_logger = getattr(mlflow, self.model_type)
model_info = ml_logger.log_model(
model,
self.artifact_path,
)
return {
"model_info": model_info.__dict__, # return some metadata
"run_info": run.to_dictionary(),
"mlflow_uri": f"{mlflow.get_tracking_uri()}/#/experiments/{run.info.experiment_id}/runs/{run.info.run_id}",
}Using a hook enables full standardization – this can be used to track any artifact with a custom artifact decorator to mark a node as containing an artifact. This can also compute a hash of the graph/inputs to disambiguate the results. Note a lot of what you can accomplish with hooks can also be accomplished with materializers. The choice of which to use depends on what you want to make explicit or implicit.
In this case we define a tagging decorator (@artifact), that works in conjunction with the MLFLowSaverHook to save any decorated artifacts to MLFlow.
def artifact(fn):
return tag(properties=["artifact"])(fn)
class MLFlowSaverHook(NodeExecutionHook):
def __init__(self, run_name: str, experiment_name: str):
self.experiment_name = run_name
self.run_name = run_name
def run_after_node_execution(
self,
*,
node_name: str,
node_tags: Dict[str, Any],
result: Any,
**future_kwargs: Any
):
if result is not None and "artifact" in\
node_tags.get("properties", []):
materializer = MLFLowSaver(
experiment_name=self.experiment_name,
model_type=_derive_model_type(result),
artifact_path=node_name,
run_name=self.run_name,
)
materializer.save_data(result)
@artifact
def model(training_data: DataFrame, hyperparameters: dict) -> Model:
return Model(**hyperparameters).train(training_data)
dr = driver.Builder().with_adapters(MlFlowSaverHook(...)).build()At DAGWorks we’ve also built a dual production-monitoring/experimentation-lite management tool. More on that later.
Ensure quality data
When data is bad, it is better for code to break early than to break later or (horrifyingly) not at all. While it may be tempting to say model training will break or look off when the data is bad to avoid validation, this is an overoptimistic and failure-prone approach.
Data quality assertions can be one of the biggest improvements to a pipeline a data scientist can use. While you won’t be able to catch everything, shifting quality concerns left will help kill any problems you can anticipate before you know it. Hamilton provides a simple tool to integrate data quality that allows for customization as needed, and integrates with popular offerings. It also helps keep both the schema/validation concerns close to the code. That way, you only need a single pull request to change or update concerns and can avoid working between two different systems.
You can use pandera to validate data:
import pandera as pa
from hamilton.function_modifiers import check_output
@check_output(
schema=pa.DataFrameSchema(
{
"a": pa.Column(pa.Int),
"b": pa.Column(pa.Float),
"c": pa.Column(pa.String, nullable=True),
"d": pa.Column(pa.Float),
}
)
)
def dataset() -> pd.DataFrame:
return ...As well as write a custom validator:
from hamilton.data_quality import base
from hamilton.function_modifiers import check_output_custom
class NoNullValidator(base.DataValidator):
def applies_to(self, datatype: Type[Type]) -> bool:
return issubclass(datatype, pd.Series)
def description(self) -> str:
return "Ensures that the data has no nulls"
@classmethod
def name(cls) -> str:
return "no_nulls"
def validate(self, dataset: Any) -> ValidationResult:
return ValidationResult(
passes=dataset.notnull().all(),
message="No nulls found in dataset",
diagnostics={
"num_nulls": len(dataset) - dataset.notnull().sum(),
"num_rows": len(dataset),
},
)
@check_output_custom(
NoNullValidator(importance="fail")
)
def dataset() -> pd.DataFrame:
return ...Note that data validation has the capability to either warn (log an error) or fail, and can apply to whatever data type you want. At an enterprise setting, custom data validators often become a component of a central library, affording a level of standardization across dataflows.
Team Needs
Onboard new members/reduce bus factor
A well-run team should not be bound by key-member dependencies – while individuals will always have essential roles that drive the team forward, they should feel free to take a vacation, move onto another project/team without guilt, or hand their work off to a new colleague. Hamilton inherently makes this easier by standardizing the code in pipelines, allowing everything to be visualized in a graph and broken into logical, bite-sized components. This is already a step-up compared to bespoke frameworks or programming styles (likely developed by/for individual data scientists, engineers, etc...), but Hamilton also has a few customization capabilities that can make it easier.
For instance, one could ensure that every function’s docstring is not empty by writing a simple hook:
class DocstringValidator(StaticValidator):
def run_to_validate_node(
self, *, node: HamiltonNode, **future_kwargs
) -> Tuple[bool, Optional[str]]:
docstring = node.documentation
if len(docstring) == 0:
return False, f"Node {node.name} has no docstring! -- all nodes must have a docstring!"
return True, None
dr = (
driver
.Builder()
.with_modules(...)
.with_adapters(DocstringValidator())
.build()
)Reducing onboarding/handoff complexity has the secondary effect of increasing the usable lifetime of code. As code (especially data code) often models an assumption that gets less true over time, it has a half-life, meaning that it requires regular maintenance and alteration to function properly. Well-organized, documented, and onboarding-friendly code is easier to maintain and thus simpler to slow down or reverse natural degradation.
One can also programmatically remove cruft with minimal linting. Using a lifecycle adapter, one can ensure that, for a given configuration, there are no dangling functions that have been implemented but are not used. This could be utilized in CI to ensure that no additional data is left out, or that dead code is quickly removed. While it is possible to do something to this effect with python variables/linting in CI, that is an imperfect approach to identifying unused code and becomes much more difficult when referring to the columns of a dataframe. We can also write a hook to help find unused functions — this does a traversal of the graph and ensures that no functions are unreferenced.
def partition(graph: HamiltonGraph) -> List[List[HamiltonNode]]:
edges = collections.defaultdict(set)
name_map = {node.name: node for node in graph.nodes}
for node in graph.nodes:
for dependency in node.required_dependencies & node.optional_dependencies:
edges[dependency].add(node.name)
edges[node.name].add(dependency)
node_to_source = {}
def traverse(node: HamiltonNode, group: str):
if node.name in node_to_source:
return # dfs already completed
node_to_source[node.name] = group
for dependency in edges[node.name]:
traverse(name_map[dependency], group)
for node in graph.nodes:
traverse(node, node.name)
return list(
itertools.groupby(
sorted(node_to_source.keys()),
lambda x: node_to_source[x]
)
)
class GraphIslandValidator(StaticValidator):
def __init__(self, min_island_size: int = 1):
self.min_island_size = min_island_size
def run_to_validate_graph(
self, graph: HamiltonGraph, **future_kwargs
) -> Tuple[bool, Optional[str]]:
partitions = partition(graph)
for graph_partition in partitions:
if len(graph_partition) < self.min_island_size:
return False, f"Partition {partition} has less than {self.min_island_size} nodes!"Know which models are in production
New ML team managers will often come in and ask the simple question. What models do we have in production? There is rarely a simple answer – most teams don’t have a spreadsheet tracking their models (along with links to associated workflows). If they are (relatively) well-organized it takes the form of naming conventions of pipelines, or a per-project google doc, and if not, it takes the place of mental note/tribal knowledge among the more senior on the team.
Model registries (such as MLFlow and WandB) can help solve this, but there are other simple solutions when the team buys into Hamilton. One can define a @model decorator that simply wraps a call to @tag. Assuming that a node outputs a model artifact, this gives us metadata to specify a node as producing a model, and can attach additional metadata as well:
def model(
model_type: str,
team: str,
purpose: str,
applicable_regions: List[str],
training_data: Optional[str] = None,
):
kwargs = {
"model_type": model_type,
"team": team,
"purpose": purpose,
"applicable_regions": applicable_regions,
"training_data": training_data,
}
return tag(**{key: value for key, value in kwargs.items() if value is not None})
With this decorator, you can do quite a bit (implementations left as a an exercises to the reader):
Search through relevant repositories + branches on your VCS for code that implements
@model– that’s a baseline list of modelsBuild a hook to write that model to a registry or metadata store (or, even, update a google spreadsheet of models/report)
Validate that a model artifact is saved during production by inspecting a graph for required materializers
Ensure that all models are of an approved format (this is specific to organizations that have limits on the model capabilities they can ship to production)
Build a custom hook around a driver that logs every model to a namespace give a hash of the DAG, bypassing the need to call out to MLflow or WandB directly.
Note that a few of these could be done with materializers as well — in most cases you’ll want materializers for I/O that needs to be explicit (E.G. anything used downstream by other pipelines), and hooks for logging/other stuff that should be included by default.
Understand data lineage/connect data consumers to producers
Another difficult question for a team to answer is what datasets are we using? Answering this is critical for stakeholder/vendor relationships, understanding what (internally generated/externally purchased) data is valuable to a team. This requires either structure and inspection (such as Hamilton) or uniformal use of a data loading utility that tracks all data users access. By leveraging Hamilton’s structure and materializers, one can easily do the following:
Track all data sources/when they were last used
Make a mapping of data sources to data products
This example illustrates how to do a graph traversal to track lineage from data sources to output data products.
class LineageHook(NodeExecutionHook, GraphExecutionHook):
def __init__(self):
self.lineage_pairs = []
self.metadata_collection = {}
def run_after_node_execution(
self,
*,
node_name: str,
node_tags: Dict[str, Any],
**future_kwargs
):
if node_tags.get("hamilton.data_saver", False) or node_tags.get(
"hamilton.data_loader", False
):
self.metadata_collection[node_name] = {
"task_id": task_id,
"run_id": run_id
}
def run_before_graph_execution(
self,
*,
graph: graph_types.HamiltonGraph,
execution_path: Collection[str],
run_id: str,
**future_kwargs: Any,
):
data_products = [
node
for node in graph.nodes
if node.tags.get("hamilton.data_saver", False) and node.name
in execution_path
]
data_sources = [
node
for node in graph.nodes
if node.tags.get("hamilton.data_loader", False) and
node.name in execution_path
]
pairs = []
for node in data_products:
linked_sources = dfs(node, search_for=data_sources)
pairs.extend(
[(source_node.name, node.name) for source_node in
linked_sources])
self.lineage_pairs = pairs
def run_after_graph_execution(self, **future_kwargs: Any):
do_something_with(self.lineage_pairs) # up to you!Ensure easy migration of data sources
Everyone’s least-favorite aspect of their job is handling migrations. E.g. migrating file types from one file format to another, or using a new table in a slightly different format. This often takes the form of platform/data engineering teams hounding data scientists + MLEs to change the source of data they’re reading from, or the way they’re reading it, and tracking migrations on a spreadsheet, or leaving old data sources around and not attempting migration. A proper abstraction layer is key to making migration easier, which requires a uniform data reading/writing capability. Although perfect abstractions are a pipe dream (parameters will likely always need to change), the quality of (and ability to modify) abstractions can be improved significantly if:
They use a framework to load/save data
Loading and saving data is (largely) called in a co-located manner
Hamilton materializers are one such framework for loading/saving data. They can be built (and shared) internally, allowing a platform team to specify a set of loaders and the associated parameters. They have two forms – a decorator that injects data (for loading)/appends a saving node (for saving), as well as a parameter to the driver.materialize function, ensuring that they’re largely decoupled from the execution code, called in a centralized manner.
Thus, when a platform team needs to make a sweeping change, they can:
Define a new version of the centralized I/O library
Push their team to use the newest version (they can track the version used with telemetry)
Deprecate the old version/move any data behind the scenes
Should changes need to be made to user code (in the case that the abstraction is not, in fact, perfect), the fact that data loading is called in a uniform manner helps them speed that process up.
This abstraction allows for an interesting pattern. The set of available materializers composes an interface for I/O. Instead of determining the public-facing portion of that interface by enumerating the implementation of the I/O (E.G. dump_to_s3, save_to_model_registry, etc…), with Hamilton they can be selected according to their purpose:
to.model(
key="trained_model",
namespace="my_project",
partition_by="day",
env="prod",
sample_data=source("training_data"),
sample_result=source("predictions"),
dependencies=["trained_model"]
) # Save a model to the model registry
to.blob(
key="raw_dataset",
namespace="my_project",
dependencies=["raw_dataset"]
) # Save a blob to a blog store
to.media(
key="roc_plot",
namespace="my_project",
depenencies=["raw_dataset"]
) # Save a static asset to something accessible by a CDNAnd so on… Thus changing implementation only requires re-implementing the data loader to use the new one and ensuring people update the library (which can be automated through other means).
To make this a bit more concrete, a blob data loader might look something like this:
@dataclasses.dataclass
class BlobLoader(materialization.DataLoader):
key: str
project: str
env: Literal["prod", "dev", "staging"]
date: datetime
variant: str = "main"
callback: Callable = cloudpickle.load
def __post_init__(self):
self.bucket = f"{self.env}-artifacts" # global bucket
def _get_path(self):
return f"{self.project}/{self.variant}/{self.date.strftime('%Y-%m-%d')}/{self.key}"
def load_data(self, type_: Type[Type]) -> Tuple[Type, Dict[str, Any]]:
client = boto3.client("s3")
response = client.get_object(
Bucket=self.project,
Key=self.key,
)
return (
self.callback(response["Body"]),
{
"path": self._get_path(),
"size": response["ContentLength"]
},
)
@classmethod
def applicable_types(cls) -> Collection[Type]:
return [object]
@classmethod
def name(cls) -> str:
return "blob"
# run.py
dr = driver.Builder()....build()
dr.materialize(
from_.blob(
key=...,
project=...,
env="prod",
date=datetime.now()
)
)Manage on-call/debugging
Coming in at a close second to migrations, on-call is a common “least-favorite” element of an enterprise data job. The trickiest part of on-call is often triaging – quickly figuring out what the root cause of an issue is and how to fix it. Data quality checks (as we’ve already discussed) help shift any potential issues left – from the inference/training to the data generation component. Furthermore, Hamilton’s stack trace naturally makes it clear where in the DAG a failure occurred. We can take debugging one step further to save/log information when a failure occurs, however, using hooks.
We can run this callback after a node executes, only on failure. It will:
Gather up the kwargs/node name/any other information
Format it
Send it to a slack channel as a notification
Note we could also have it gather information about the run if needed by implementing a post_graph_execute hook, and do something as fancy as store pickled versions of keyword arguments, log the docker image that was used, then launch a jupyter notebook and give the user access to that notebook (implementation left as an exercise to the reader). While this won’t work in the case of odd data (just broken data, either with a data quality assertion or an exception in the code), one could also use the same tool to store a variety of input parameters regardless of failure, allowing a quick interactive session to be pulled up with any of the nodes.
class SlackNotifier(NodeExecutionHook):
def run_after_node_execution(
self,
*,
node_kwargs: Dict[str, Any],
node_name: str,
error: Exception,
**future_kwargs: Any
):
if error is not None:
node_kwargs_formatted = "\n".join(
[f"{key}: {value}" for key, value in
\node_kwargs.items()]
)
stack_trace = traceback.format_exc()
slack_message = (
f"*Node {node_name} Execution Error!*\n\n"
f"*Context:*\n"
"Error occurred during node execution.\n\n"
f"*Node Arguments:*\n"
f"```\n{node_kwargs_formatted}\n```\n\n"
f"*Error Traceback:*\n"
f"```\n{stack_trace}\n```"
)
webhook_url = "YOUR_SLACK_WEBHOOK_URL"
requests.post(webhook_url, json={"text": slack_message})Company Needs
Ensure compliance
Managing compliance to regulatory data requirements is an essential, yet often monotonous component of many people’s roles. While there are quite a few regulations (and new ones coming out all the time), let’s look at data privacy/GDPR as an example. In particular, knowing which datasets contain PII (and thus are impacted by a deletion request) can involve significant auditing/regular approval of a growing number of datasets. This can be automated to an extent if you know the relationships between data beforehand and understand its general provenance/lineage due to the structure of the code.
Say that every transformation preserves PII usage unless it is tagged with a @anonymized decorator that would be used for a specific anonymizing operation, aggregation, or model training:
def anonymized(fn):
return tag(compliance_properties=["no_pii"])(fn)To mark produced tables as GDPR concerns, all you have to do is:
Look up all materialized outputs (the materializer nodes output metadata, which you can control if you write your own implementations).
Record the tables outputted by those nodes
Backtrack until you either
Find an anonymized node
Find an input table
For each in (3.b), you can check if they contain PII (either through a parameter on the data loader or an external metadata repository), and mark the corresponding output tables as *also* containing PII (either asking the user to place a tag, add the right anonymizer, or record the output to the repository.
class PIITracker(NodeExecutionHook, GraphExecutionHook):
def __init__(self):
self.output_map = {}
self.input_map = {}
def run_after_node_execution(
self,
*,
node_name: str,
node_tags: Dict[str, Any],
result: Any,
**future_kwargs: Any
):
if node_tags.get("hamilton.data_saver", False):
self.output_map[node_name] = extract_uri(result)
elif node_tags.get("hamilton.data_loader", False):
_, metadata = result # Tuple of data, metadata
self.input_map[node_name] = extract_uri(metadata)
def run_after_graph_execution(
self,
*,
graph: graph_types.HamiltonGraph,
results: Optional[Dict[str, Any]],
**future_kwargs: Any,
):
all_nodes_by_name = {node.name: node for node in graph.nodes}
nodes_with_pii = set()
nodes_without_pii = set()
def dfs(node: HamiltonNode):
if node.name in nodes_with_pii or node.name in\
nodes_without_pii:
# already visited
return
if "no_pii" in node.tags.get("compliance_properties", []):
nodes_without_pii.add(node.name)
return # no need to traverse further
if node.name in self.input_map and\
contains_pii(self.input_map[node.name]):
nodes_with_pii.add(node.name)
return
for dependency in node.required_dependencies:
dfs(all_nodes_by_name[dependency])
if dependency in nodes_with_pii:
nodes_with_pii.add(node.name)
return
for result in self.output_map:
dfs(all_nodes_by_name[result])
outputs_with_pii = [
self.output_map[node] for node in nodes_with_pii
]
for output in outputs_with_pii:
mark_as_containing_pii(output)Note that Hamilton’s lineage capability can help with a variety of other regulations as well using similar tactics – we may consider another post on this if there is interest.
Trace usage of datasets for global querying
Similar to GDPR, a company may want to know the entire assortment of datasets in use – how many times they are loaded, which team loads them, etc… This can be vital for inter-team communications, evaluation of purchased dataset quality, and understanding the structure of business decisions.
Using materializers/data adapters enables a similar approach to data regulation management. This can be done with a simple hook after node execution that looks for metadata released on read + a tag indicating a loader node, logging the dataset source/metadata to some table for later analysis/auditing.
class DataSetTracker(NodeExecutionHook):
def run_after_node_execution(
self,
*,
node_name: str,
node_tags: Dict[str, Any],
result,
**future_kwargs: Any
):
if node_tags.get("hamilton.data_saver", False):
artifact_type = extract_type(result)
artifact_uri = extract_uri(result)
track_dataset(
uri=artifact_uri,
name=node_name,
last_written=datetime.now()
)Globally examine at set of models in production
Similar to experiment tracking above, we can apply this at a company level – aggregating models across teams/initiatives. In addition to the tools outlined above, we can log metadata to a central analytics database with the model name, the date of the pipeline run, and the pipeline’s configuration. Note that this could work in addition to logging to MLFlow or a centralized repository – a tool such as this allows for different/custom MLOps tools across teams with a unified approach.
class ModelTracker(NodeExecutionHook):
def run_after_node_execution(
self,
*,
node_name: str,
node_tags: Dict[str, Any],
node_type: Type,
result,
**future_kwargs: Any,
):
if node_tags.get("hamilton.data_saver", False):
artifact_type = extract_type(result)
artifact_uri = extract_uri(result)
if artifact_type == "model":
track_model(
uri=artifact_uri,
name=node_name,
last_written=datetime.now(),
model_type=str(node_type),
)Track libraries with security vulnerabilities
Security teams often want a cross-cutting analysis of vulnerabilities that might be present in code run at their company. This involves scanning the environment to detect, record, and potentially error out on the use of libraries with known vulnerabilities. To do this, you can add a hook that does a scan prior to graph execution, calling out to the pypa advisory database. While this provides little advantage in a pre-built docker image (as you can easily shift left to, say, a pre-commit), it does allow for the latest use of libraries in an ETL in case you want to be on the bleeding edge. Furthermore, it allows you to get closer to the code that actually runs, ensuring that any pipeline that is run will fail if it is not secure.
class VulnerabilityTracker(GraphExecutionHook):
def gather_vulnerabilities(self) -> Dict[str, Any]:
library_data = [
{
"package":
{
"ecosystem": "PyPI",
"name": dist.metadata["Name"]
},
"version": dist.version,
}
for dist in importlib.metadata.distributions()
]
with_vulnerabilities = {}
url = "https://api.osv.dev/v1/querybatch"
data = {"queries": library_data}
response = requests.post(url, json=data)
response_data = response.json()
for i, result in enumerate(response_data["results"]):
if len(result["vulns"]) > 0:
with_vulnerabilities[library_data[i]["package"]\
["name"]] = library_data[i]["version"]
return with_vulnerabilities
def run_before_graph_execution(self, **future_kwargs: Any):
vulnerabilities = self.gather_vulnerabilities()
if len(vulnerabilities) > 0:
raise Exception(
f"Vulnerabilities found: {vulnerabilities}. "
"Please fix before running graph! "
"Thank you for keeping us safe."
)Report on cost
Compute can be one of the top costs for an organization – they often put significant effort into managing it. Using a hook from Hamilton, you can get a glimpse at the price of running data pipelines at a per-function level! While there are a few approaches, you will likely want to measure:
Time of a node
Resource usage (CPU, GPU, memory)
Cost of the compute you are using (lambda, EC2 fixed, spot, etc…)
While attribution in cloud cost is complex, if you have some view into (3) (E.G. if you’re using an EC2 instance, you can query metadata: https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-instance-metadata.html), then you can figure out how much an individual function/DAG costs!
To do so, you could write a hook that:
Gathers EC2 metadata
Looks up the cost
Records time before/after nodes
Records any other information (for metadata/analysis)
Computes the duration of the node
class CostEstimator(GraphExecutionHook, NodeExecutionHook):
def __init__(self):
self.ec2_type = gather_ec2_type()
self.cost_per_hour = get_cost_per_hour(self.ec2_type)
self.node_start_times = {}
self.node_costs = {}
def run_before_node_execution(
self,
*,
node_name: str,
node_tags: Dict[str, Any],
node_kwargs: Dict[str, Any],
node_return_type: type,
task_id: Optional[str],
run_id: str,
**future_kwargs: Any,
):
self.node_times[node_name] = datetime.now()
def run_after_node_execution(
self,
*,
node_name: str,
**future_kwargs
):
node_time = (datetime.now() - self.node_times[node_name])\
.total_seconds()
cost = node_time * self.cost_per_hour / 3600
self.node_costs[node_name] = cost
def run_after_graph_execution(self, **future_kwargs: Any):
for executed_node in self.node_costs:
print(f"node: {executed_node} cost:\
${self.node_costs[executed_node]}")As direct cost is tricky to measure, it is often worth measuring the actual resource usage versus available usage (memory, CPU, GPU), and finding which functions can be optimized/are wasted. You can modify the above code to do that as well.
DAGWorks platform
At DAGWorks, we have built a tool to satisfy many of the capabilities we presented above (and we’re planning significant extensions to cover more - reach out if you want to pilot some of these features).
Specifically, the DAGWorks platform can:
Help you track models/datasets by presenting a data catalog of your DAGs
Gain visibility into failures/data issues to make on-call easier
Manage experiments, metrics, datasets, and production runs
Provide visibility into data lineage, allowing you to trace data from an input source through your transformations to an output source.
Allow you to track DAG executions across multiple “macro”-orchestration tasks
We’ve built it as a natural, enterprise-level companion to Hamilton. It’s free to try, and only requires a one-line change from your Hamilton code. You can sign up at dagworks.io.
Some parting thoughts…
Change Management
For better or for worse, decisions are rarely made by fiat. A platform team can not expect everyone to use their exciting new technology if they don’t leverage the right set of incentives and approaches to change management. Even if adoption is off the charts, they can’t always expect people to use their product in the right way. Furthermore, should they succeed in gaining widespread adoption, the change likely will not occur overnight.
We direct readers who are interested in change management to our post on the ADKAR approach, which outlines a succinct, actionable way to handle change (such as getting a data team to use Hamilton!). Otherwise, it is up to the platform team to ensure that their team uses all of the hooks above. This can be achieved with a number of tools:
Add a default set of hooks as a constant that users can import and include with their driver
Create a wrapper around the driver that automatically injects those hooks
Ensure that incentives are aligned for use – this is one of the reasons we focused so much on individual concerns in this post. The key to getting individuals to quickly adopt your tool is by showing them clear and immediate value. Sneak in some long-term value as well, and everyone wins!
Incremental Adoption
While some of the above are made more useful once everyone buys in (E.G. compliance), they can all be adopted incrementally. The common approach towards migration is:
Determine a pilot project to show value
Use that momentum to onboard the team to Hamilton for new/rewritten projects
Over time (and due to the half-life of code), the vast majority of pipelines will be written in Hamilton.
Note that, (especially in the case of compliance/security/lineage), many of these are automations of manual processes. This fact can be used to encourage adoption. Say, for instance, that you normally have to go over and manually validate (then get a checkmark from your boss) which tables contain PII and which ones don’t. By using Hamilton’s materialization feature to ensure uniform I/O and the hooks outlined above to track for PII, you would be able to bypass this task – freeing up time and mental energy. This, in addition to security concerns and easy lineage querying could free up enough time to make it appealing to migrate, especially for newer pipelines.
We’d love to hear from you!
If you’ve made it all the way here, thank you for sticking with us! While we dug fairly deep into customizing Hamilton for enterprise settings, there is still quite a bit we have not covered. If you have more enterprise needs, or questions about implementing the strategies we outlined above, feel free to reach out! In the meanwhile, here are some resources to get you started:
📣 join our community on Slack — we’re more than happy to help answer questions you might have or get you started.
⭐️ us on GitHub
📝 leave us an issue if you find something
Other Hamilton posts you might be interested in:
While this is not true everywhere, we’ve seen enough data platforms to know that, if special care is not taken, complexity almost always leads to slow, frustrated data teams. Specifically, we are writing this post to help teams avoid that.