
Customizing Hamilton’s Execution with the new Lifecycle API
How to tailor hamilton's runtime to your


In this post, we present a new API for customizing the execution of dataflows written in Hamilton. We will briefly go over Hamilton, talk about the new customization capabilities, walk through an example use of the new API, and share our vision of where we can take this in the future.
This post is meant for:
Individuals + teams that are using Hamilton and looking to learn more or are curious whether Hamilton can fit their needs.
Platform designers who are looking to draw inspiration from (or criticize) a platform’s design.
If this doesn’t describe you, we anticipate this will be a fun read anyway, but we do recommend you try out Hamilton at tryhamilton.dev.
First, let’s talk about Hamilton and why customization adds so much value.
A Framework for Processing “Data”
Hamilton is a standardized way to build dataflows (any code that processes data) in python. The core concepts are simple – you write each data transformation step as a single python function, with the following rules:
The name of the function corresponds to the output variable it computes
The parameter names (and types) correspond to inputs. These can be either external inputs or the names of other upstream functions
To demonstrate, let’s look at a simple ML pipeline (if MLOps is further from your day-to-day, check out others at tryhamilton.dev).
# simple_pipeline.py
def digits_df() -> pd.DataFrame:
"""Load the digits dataset."""
digits = datasets.load_digits()
_digits_df = pd.DataFrame(digits.data)
_digits_df["target"] = digits.target
return _digits_df
def digits_model(digits_df: pd.DataFrame) -> svm.SVC:
"""Train a model on the digits dataset."""
clf = svm.SVC(gamma=0.001, C=100.)
_digits_model = clf.fit(
digits_df.drop('target', axis=1),
digits_df.target
)
return _digits_model
def predicted_digits(
digits_model: svm.SVC,
input_digits: pd.DataFrame) -> pd.Series:
"""Predict the digits."""
return pd.Series(digits_model.predict(input_digits))
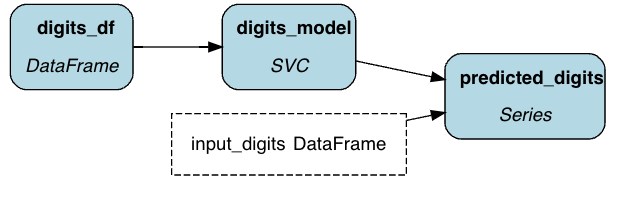
You then run these using a “driver”, which specifies how/where to execute the code.
from hamilton import driver
import simple_pipeline
dr = driver.Driver({}, simple_pipeline)
result = dr.execute(
[
"predicted_digits", # this is what we're requesting to be computed
],
inputs={"input_digits": load_some_digits()}
)The simplicity of the code structure means you can use this pattern for a variety of applications. Furthermore, as it is just a way of organizing code, it is fundamentally compatible with all existing python libraries. We have observed multiple companies using Hamilton for MLOps, LLMOps, and a wide array of other data processing :
Express their ML workflows (training, inference, and feature engineering)
Build extensible Retrieval Augmented Generation/LLM workflows
Represent the logic of a micro-service (data processing, API calls, error management)
And quite a few more (like processing files for data reconciliation/ETL) – we’ll be using the cases we just outlined above to make our points in this post.
Hamilton in different contexts
As we can use Hamilton to model a variety of different business problems, the technical needs naturally vary between them. Let’s look at these applications in more detail – consider that you have a reasonable design/implementation, and want to get it into production. What are some of the secondary concerns you might have? Here’s a sampling that we’ve seen in our work/previous roles:
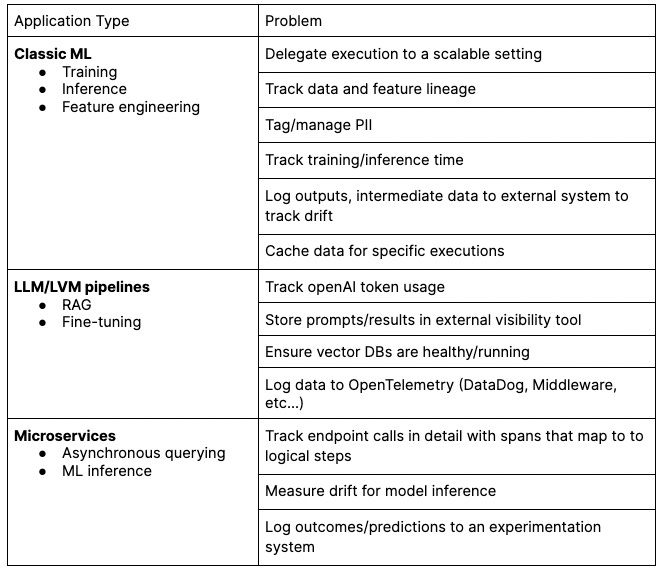
While Hamilton is good at building the scaffolding for these, most organizations will want to address these concerns in a specific way. Rather than stretching ourselves thin by reinventing the execution, auditing, telemetry, and validation wheels for every conceivable context, we have decided to keep Hamilton itself simple and add the ability to build/integrate any of these capabilities yourself!
In short, there are a lot of possibilities that excite us. While representing and executing your dataflows as DAGs of python functions is enough to help you iterate faster to production, everyone will eventually need to BYO some tool to get to production. We have built the new lifecycle API to make doing so first-class.
Customizing Execution
At a high level, the lifecycle API allows you to customize multiple components of Hamilton’s execution. You write functions (through inheriting provided classes) that run at different stages of a DAG’s “lifecycle”, and pass them into the driver.
There are two levels of APIs:
[Internal] A set of base classes that Hamilton registers and executes during the lifecycle. These use internal constructs and may not necessarily be stable between minor/patch versions.
[External] A secondary set of base-classes that you (the user!) can implement – these form an opinionated and largely complete set of tools for customizing Hamilton’s lifecycle. We intend to quickly add more APIs as users come to us with requirements.
To explain how customization in Hamilton works, we will first go over the general structure for the internal-facing API, which will help you grok how the external API plugs into Hamilton. We will then walk through a few of the customization options available using the external API, connecting it back to the list of capabilities we talked about above, and show how to plug them back into Hamilton’s execution.
Let’s walk through the lifecycle stages of Hamilton’s execution as we’ve defined them internally. Recall that these are the building blocks – they’re worth understanding to become powerful with the external API, but you will not interface with them directly.
Internal API
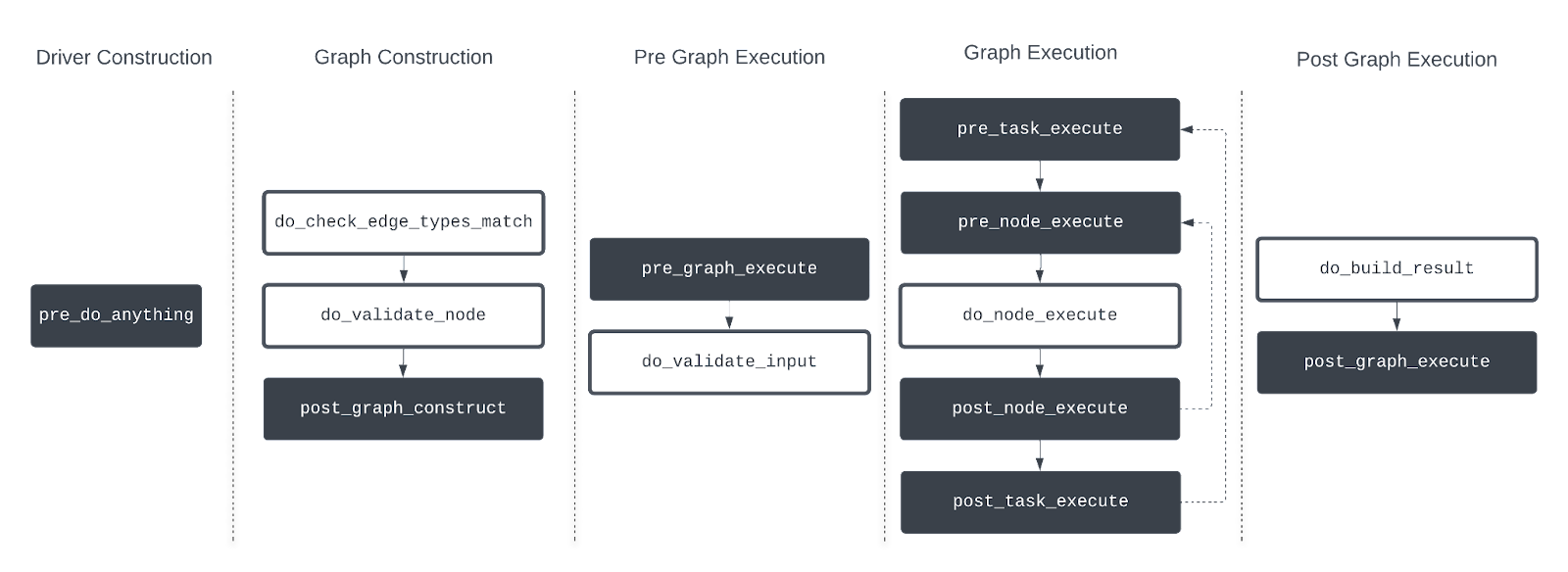
A diagram of the current set of lifecycle customizations, broken down into stages. Arrows represent temporal dependencies, arrows back indicate a loop over multiple nodes/tasks. Explanation of colors below.
The diagram above shows what customizations are available, and how they play into DAG execution. A few things might jump out:
The color scheme
This differentiates a hook (white text on black background) from a method (black text on white background). A hook is a step that has no output – E.G. a side-effect. A single lifecycle step can execute as many hooks as you want. For example, you can have an arbitrary number of post_node_execute hooks. Methods can currently have only one implementation per given Hamilton execution (e.g. only one way to do node execution.)
The presence of tasks versus nodes
This accounts for Hamilton’s new task-based dynamism capability, in which groups of nodes are generated at runtime and delegated to an executor (such as ray/dask) to allow for a greater degree of parallelism/flexibility. We have hooks that manage these as well, but we won’t be digging into them in this post.
The lack of callbacks explicitly handling execution failures
This is by design – failure cases are handled by the same functions as successes. E.G. post_node_execute consumes a boolean parameter success, as well as a nullable object parameter, error, that are only set in the finally block of an exception.
Lifecycle stages are all defined as base classes that register (through an internal-facing decorator) the lifecycle function as a single step. Note this is framework code — you will never use this decorator. We include it to help contextualize the code you will write.
@lifecycle.base_hook("post_node_execute")
class BasePostNodeExecuteAsync(abc.ABC):
@abc.abstractmethod
def post_node_execute(
self,
*,
run_id: str,
node_: node.Node,
kwargs: Dict[str, Any],
success: bool,
error: Optional[Exception],
result: Any,
task_id: Optional[str] = None,
):
"""Hook that is called immediately after node execution.
:param run_id: ID of the run, unique in scope of the driver.
:param node_: Node that is being executed
:param kwargs: Keyword arguments that are being passed in
:param success: Whether or not the node executed successfully
:param error: The error that was raised, if any
:param result: The result of the node execution
:param task_id: ID of the task, defaults to None
"""
passThis indicates that this class declares a lifecycle hook post_node_execute, which subclasses implement by defining the identically named function. This lifecycle hook forms an implicit contract with the driver (really, anything that executes a Hamilton DAG). It declares several inputs (run_id, node_, kwargs, etc…) as keyword arguments, and does not return anything. You can find the comprehensive set of currently available (internal-facing) base-classes here.
While these currently form the full set of customizable lifecycle steps, we will likely be adding more over time. Furthermore, the design allows for asynchronous functions, ensuring that these can be run in a python web service as well as a batch job. The design also allows you to mix/match with multiple inheritance (mixins), to build classes that implement a variety of lifecycle hooks/methods.
While you can subclass these directly (and may want to purely for messing around/prototyping new capabilities), the code you write will not be considered “stable”, as it both uses internal constructs (E.G. the Node object), and relies on a potentially changing API. This allows us to add and remove parameters as needed without breaking any user-code.
The limitations on the internal API are why we built a user-facing API (next section)!
User Facing API
The user-facing lifecycle API consists of a set of classes that implement one or more hooks/methods. You can subclass these to customize execution. All extensible methods are keyword-only, and have methods with **future_kwargs appended to ensure we can add (but not subtract) parameters and nothing will break. You can find the full set in api.py. Let’s take a look at the NodeExecutionHook, which we’ll be using later to build a debugging capability for Hamilton:
class NodeExecutionHook(BasePreNodeExecute, BasePostNodeExecute, ABC):
"""Implement this to hook into the node execution lifecycle. You can call anything before and after the driver"""
@abc.abstractmethod
def run_before_node_execution(
self,
*,
node_name: str,
node_tags: Dict[str, Any],
node_kwargs: Dict[str, Any],
node_return_type: type,
task_id: Optional[str],
**future_kwargs: Any,
):
"""Docstring abridged for simplicity"""
@abc.abstractmethod
def run_after_node_execution(
self,
*,
node_name: str,
node_tags: Dict[str, Any],
node_kwargs: Dict[str, Any],
node_return_type: type,
result: Any,
error: Optional[Exception],
success: bool,
task_id: Optional[str],
**future_kwargs: Any,
):
"""Docstring abridged for simplicity"""While the user-facing API has replaced pre_node_execute with run_before_node_execution, and post_node_execute with run_after_node_execution, it is otherwise similar. The purpose of adding separate methods is to provide a stable interface to the desired hooks. Running arbitrary code before and after node execution is as easy as implementing this classes, and then plugging back in (next section!)
Plugging Back In
To plug back into the driver, all you have to do is pass the constructed lifecycle methods classes in as objects. With the old (constructor) API, you can do it as follows:
from hamilton import driver
adapter1 = CustomLifecycleAdapter(...)
adapter2 = CustomLifecycleAdapter2(...)
dr = driver.Driver(
{...}, #config
module1, module2, module3,
adapter=[adapter1, adapter2]
)
dr.execute(...)With the new builder API, it is just as easy:
dr = (
driver
.Builder()
.with_modules(module1, module2, module3)
.with_config({...})
.with_adapters(adapter1, adapter2)
.build())
dr.execute(...)And that’s all there is to it! Note that this is a superset of the GraphAdapter API (if you happen to be familiar) – all graph adapters that were previously built will continue to work. In fact, all they do now is implement a few lifecycle methods/hooks.
Let’s Build
Now that we know the architecture of customizing Hamilton’s lifecycle, how you can build your own, and how to plug back into the driver, let’s run through some examples.
Create a Debugger
The goal is to make it really easy to debug Hamilton’s execution. In executing Hamilton DAGs, we often want to pause and examine what went wrong. To do so, we will add a hook to allow the user to enter an interactive debugging mode at execution time, both during (within the user-defined function), and after (with the ability to inspect results/kwargs). Note this is a simplification of the available PDBDebugger.
To do this, we’re going to use the following two debugging capabilities built into python:
pdb.set_trace() to pause execution after a node
pdb.runcall() to pause execution within the body of a function
If you’re not familiar with pdb, I highly recommend reading through the documentation, although that is not necessary to understand this post.
We’re going to combine implementation of two classes:
NodeExecutionHook (to execute after a node runs). This requires implementing
run_before_node_executionandrun_after_node_execution.NodeExecutionMethod (to execute the node itself). This requires implementing
run_to_execute_node.
class PDBDebugger(NodeExecutionHook, NodeExecutionMethod):
def run_to_execute_node(
self,
*,
node_callable: Callable,
node_kwargs: Dict[str, Any],
**future_kwargs: Any) -> Any:
"""This is run to execute the node callable.
All this does is run the node_callable with the node_kwargs in a PDB debugger.
:param node_callable: Function that the node runs
:param node_kwargs: Keyword arguments passed to the node
:param future_kwargs: Reserved for future backwards compatibility.
:return: The result of running the node
"""
return pdb.runcall(node_callable, **node_kwargs)
def run_after_node_execution(
self,
*,
node_name: str,
node_tags: Dict[str, Any],
node_kwargs: Dict[str, Any],
node_return_type: type,
result: Any,
error: Optional[Exception],
success: bool,
**future_kwargs: Any):
"""Launches a PDB debugger after a node executes with all context information you could possibly want. Param docs left out for simplicity"""
pdb.set_trace()As you can see above, the implementation is simple. There is a bit of boilerplate code (largely so we can pass any information through to the user for debugging), but the meat of this is simple. That said, it is very powerful – you can now launch an interactive debugger before/after every node in your pipeline. Note that you would likely want to filter nodes with a constructor argument (so it just pauses on specific ones). This is done in the official PDBDebugger as referenced above.
To run this, all you need to do is instantiate and pass to your driver:
dr = (
driver
.Builder()
.with_modules(module1, module2, module3)
.with_config({...})
.with_adapters(PDBDebugger())
.build()
)
dr.execute(...)Other Capabilities
Along with a full implementation of the PDBDebugger we built above, Hamilton comes out of the box with:
A PrintLn hook, for gaining quick visibility into the inputs/outputs of nodes
Multiple GraphAdapters, for customizing execution (including caching and scaling on dask/ray/spark)
ResultBuilders, for joining results together post-execution
A progress bar using TQDM (see gif!)
And we intend to add more as good ideas come in! Stay tuned, and reach out for requests.
Looping Back
Recall we started this blog post with a promise of nearly infinite customization. While the technology we demonstrated above hints at how we can achieve that, we have not yet shown that any of the things we wanted to do are possible with the lifecycle API. Let’s stitch it back together with the stages we defined above:

Note the suggestions above are more intended as inspiration than a detailed technical outline. The details are, obviously, dependent on what you’re trying to achieve, but we believe that all of these (and more!) are unlocked with the new APIs. If you find yourself needing more API customizations, stuck on where to get started, or curious if the lifecycle customizations can help you, please reach out and we’ll help you dig in more (links at the bottom).
Wrapping Up
In this post we:
Conducted a quick overview of the Hamilton library
Discussed a range of potential applications + customizations that would improve these
Presented the structure of the new lifecycle API, which allows you to customize almost any component of Hamilton’s execution
Built out a custom debugger using the lifecycle API
Tied the new API back to the initial problems that motivated the post
We’re really excited about where this can go – we plan to develop quite a few of the adapters we listed above. If you’re interested in contributing, please reach out! We can help make vendor tooling more accessible, boost any open-source tool by making it easy to plug into Hamilton, and help you think through the right abstraction to use for your use-case.
We Want to Hear from You
If you’re excited by any of this, or have strong opinions, drop by our Slack channel / or leave some comments here! Some resources to get you help:
📣 join our community on Slack — we’re more than happy to help answer questions you might have or get you started.
⭐️ us on GitHub
📝 leave us an issue if you find something
Other Hamilton posts you might be interested in: