Slack summary pipeline with dlt, Ibis, and Hamilton
A lightweight & modern Python ETL stack


For open-source projects, building a community is pivotal to establishing a roadmap, getting feedback, and supporting users. In the case of Hamilton, Slack is our first line to provide direct technical help and guidance. However, the platform is limited in two main ways for community management:
Message expiry: on the free tier, Slack messages become unavailable after 90 days. Consequently, time and effort spent to craft valuable questions and answers are lost.
Closing threads: Slack is primarily a messaging platform and doesn’t have features to close or lock threads. Therefore, it can be ambiguous if an inquiry leading to a thread was resolved or not. We want to avoid missing user issues.
For these reasons, we built a pipeline to store Slack messages and used large language models (LLMs) to summarize: the question, the answer, and if the issue was resolved.
In this blog
We will detail the process of building our Slack pipeline using the trio of open-source Python libraries dlt, Ibis, and Hamilton to form a lightweight ETL stack
By the end, you’ll have learned:
What is ETL, ELT, and Reverse ETL
Why adopt a lightweight stack
How dlt, Ibis, and Hamilton complement each other
dlt kickstarts your data project with off-the-shelf
SourcesandDestinationsIbis reduces the development-production gap with portable data transformations
Hamilton enables modular and extendable dataflows
How to build the Slack summary pipeline
ETL, ELT, and Reverse ETL
To understand how these tools fit together, we need to briefly explain what ETL stands for. The letters refer to “extract, transform, load”, each one being an operation in a data pipeline.
Extract is about retrieving data from a Source, which can a public API, a customer relationship management (CRM) system, an operational database, etc.
your CRM provides an API to export JSON data
Transform is about converting extracted data into a meaningful format, for analytics or machine learning purposes for instance.
JSON data is normalized into a
contactand acompanytableLoad is about storing the transformed into a Destination data storage (filesystem, database, data warehouse).
the
contactand thecompanytables are stored in your data warehouse
These operations can be ordered and chained in several ways to create pipelines for different use cases. Importantly, the source and destination most often “speak different languages”, so an intermediary is required to move data from one place to another. By trying hard enough, a lot of software can be modelled as simple ETL processes 😅.
ETL
“Extract, Transform, Load” (ETL) generally means getting a large amount of raw data, transforming it, and storing processed values. For decades, it was the preferred way to write analytics pipelines. While it avoids storing large amounts of raw data, it requires moving the data twice: from source to the transformation process, and from there to the destination.

In the above diagram, ETL is handled by a Python process. Concretely, it could be your personal computer or an EC2 instance executing a script or a CLI command to extract data, transform data locally, and then load it.
However, production data can exceed the storage and compute capacity of a single machine. In that case, an orchestrator (a fancy Python process) will extract the data to a computation engine (e.g., Spark) for the transformation process.

ELT
“Extract, Load, Transform” (ELT) moves all the raw data from source to destination, and then executes transformations at the destination, moving the data only once. This approach is associated with the introduction of data warehouses that have both significant computation and storage (e.g., Snowflake, Databricks).
ELT isn’t really all that different from ETL. It’s mostly a matter of which data is stored and what system is responsible for compute. The Python process keeps the same role of invoking code to execute (e.g., SQL queries).

Since the Python process only extracts and loads the data, no computation engine is required, leading to ELT pipelines typically having simpler architectures. The orchestrator only has to schedule the Python process, which remains responsible for managing data movement and transformations.

Reverse ETL
“Reverse ETL” is best understood as swapping the roles of what is typically the source and the destination. For example, the source are sales forecasts generated by data scientists (E), which are formatted (T) and loaded back into the CRM system (L).

Using a lightweight Python stack
dlt is an “extract, load” tool while Hamilton and Ibis handle the “transform” step, covering all steps of ETL pipelines and their variations. This stack is deemed lightweight because it’s only composed of Python libraries with a handful of dependencies each. Consequently, you can get started with
pip install dlt ibis-framework sf-hamiltonNo complicated installation, platform signup, database, or service deployment required. You just need a Python environment!
Benefits
Python code centric: everything is Python code, limiting the sprawl of script, queries, and config (
.py, .sql, .yaml, .json)Interoperable / no lock-in: this stack will work with any orchestrator or platform allowing you to run Python code
Backend portability: the same transformations will run across backends
Open-source: free and community-driven roadmap
What is dlt?
dlt stands for “data load tool” and it’s a library providing a ton of connectors to Sources (Slack, GitHub, Hubspot, Google Analytics, etc.) and Destinations (S3, Snowflake, DuckDB, BigQuery, etc.). Sources and destinations can be connected using a dlt Pipeline, or used separately.
To start a project, use this CLI command to initiate a pipeline (Slack to DuckDB here):
dlt init slack duckdb It will generate in your project the files for the Slack source and the DuckDB destination. The slack/ directory will include a README detailing how to get a Slack API token and pass credentials.
Then, you can run the pipeline with:
python slack_pipeline.py # file generated by `dlt init`After executing the pipeline once, you can launch a Streamlit web app to inspect the ingested data and the pipeline metadata with
dlt pipeline slack show # `slack` is the pipeline nameSee the dlt introduction to learn more.
While data loading may seem straightforward, dlt efficiently handles common data engineering challenges:
When loading data from a source, it automatically normalizes columns and generates table schemas, making it easy to detect upstream schema changes.
A batch and a row identifier is added to each loaded records, providing incremental loading out of the box. This can dramatically reduce your ingestion pipeline cost and latency.
Unlike other frameworks with a catalog of data connectors (Airflow, dbt, etc.), dlt is just a library. You aren’t restricted to a particular tool and it’s interoperable with any orchestrator.
It’s easy to wrap a private API endpoint to create a custom dlt source and connect it to a supported destination to get all of the benefits of dlt.
What is Ibis?
With Ibis, you can define data transformations once and execute them on multiple backends (BigQuery, DuckDB, PySpark, Snowflake, etc.). This is a boon for data professionals as it allows you to develop locally, on DuckDB for instance, and be confident your code will work on your production backend (which likely won’t be DuckDB) without any code rewrite!
Writing Ibis code is akin to writing SQL queries but with the Python language. With Ibis you define an expression, which is then compiled to SQL and executed directly on the backend. For example:
# count the number of messages per thread
table1 = (
table0
.group_by("thread_id")
.agg(message_count=ibis._.count())
)
table1.to_pandas() # execute and return a dataframeIf you’re curious, you can compile the Ibis code with ibis.to_sql(table1) and view the resulting SQL query
SELECT
t0.thread_ts,
COUNT(*) AS message_count
FROM table0 AS t0
GROUP BY 1What is Hamilton?
Hamilton helps define dataflows of transformations with regular Python functions. Like dbt, it is a declarative transform tool, but it isn’t limited to SQL operations. Hamilton supports all Python types and can enable ML and LLM workflows end-to-end. Since it's just a library, it can run without or within any orchestrator, or even power your FastAPI server, Streamlit UI, or LLM application!
In the picture below, notice how function and parameter names define dependencies between functions. Hamilton can automatically assemble the Python module on the left into the dataflow shown on the right.

Using Hamilton with Ibis allows you to break down your complex queries into reusable and easy to test components. Hamilton improves your project readability with docstrings, type hints and visualizations generated directly from code. Together they provide a Pythonic dbt-like experience that is portable across backends.

Building the Slack summary pipeline
We will create a pipeline using dlt to “extract & load” Slack messages and Hamilton + Ibis to “transform” data into summaries using the OpenAI API. After a few minutes, we had set up the dlt pipeline and loaded Slack data into a local DuckDB instance. Then, we built a dataflow of Ibis data transformations using Hamilton. We leverage the backend’s Python user-defined functions (UDFs) to call the OpenAI API from the backend. This way, all transforms are handled by the destination in ELT fashion.
To move the code from development to production, we will simply have to change the dlt destination to another Ibis-supported backend (e.g., Snowflake, Postgres) and ensures that UDFs are supported!
slack_summaries/
├── .dlt/
│ ├── .sources
│ ├── config.toml
│ └── secrets.toml
├── slack/
│ ├── __init__.py
│ ├── helpers.py
│ ├── settings.py
│ └── README.md
├── transform.py
├── run.py
├── notebook.ipynb
└── README.mdIn the repository, the directories .dlt/ and slack/ were generated by dlt and transform.py contains the Hamilton + Ibis data transformations. The file run.py contains the code to execute both the dlt pipeline (EL) and the Hamilton dataflow (T). This allows us to run the full ELT pipeline as a single script. There’s also a notebook with some explanations, allowing you to explore content interactively.
Extract & Load pipeline
The dlt pipeline to extract & load Slack data is found in run.py. It defines the Slack pipeline with destination DuckDB, configures the Slack source to retrieve the “General” and “Help” channels, and executes the pipeline.
slack_pipeline = dlt.pipeline(
pipeline_name="slack",
destination="duckdb",
dataset_name="slack_data",
full_refresh=True,
)
dlt_source = slack.slack_source(
selected_channels=["general", "help"],
replies=True,
)
load_info = slack_pipeline.run(dlt_source)Transform dataflow
Hamilton uses Python functions stored in modules to define dataflows, in this case transform.py. At a high level, the steps to use the Ibis defined transformations are:
connect to the DuckDB destination of the dlt pipeline
iterate over channels to collect messages
union all the channels
group messages by thread
generate summaries using the OpenAI API
Hamilton can generate a dataflow visualization directly from the code, helping with documentation. See how it conveys the same story:
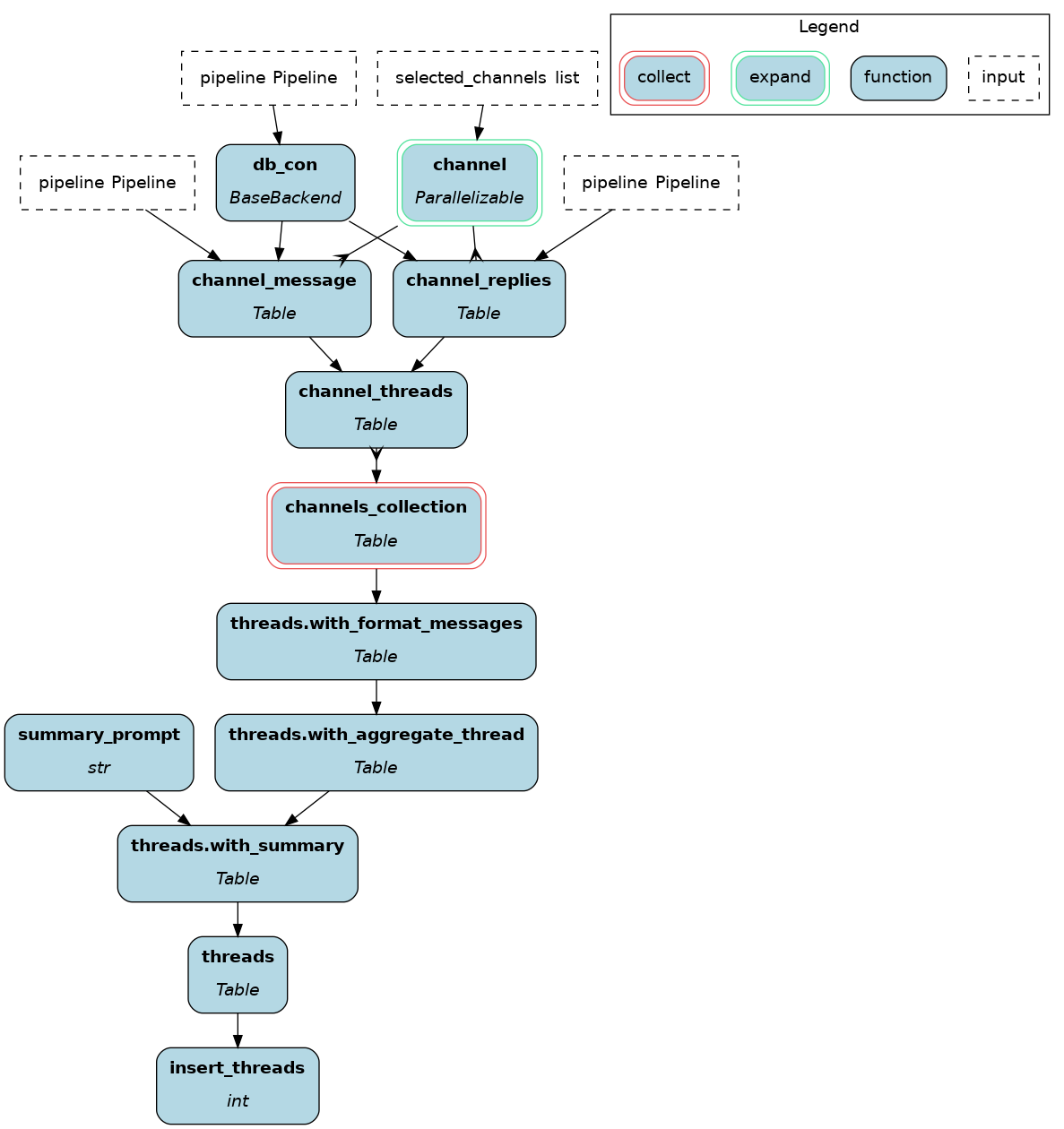
The next sections highlight technical points of interest about each tool and how they interact.
Connect to the DuckDB destination
Since many backends are supported by both dlt and Ibis, it isn’t too difficult to pass the backend connection from one framework to the other. In fact, an upcoming update should make it even easier!
def backend_connection(pipeline: dlt.Pipeline) -> ibis.BaseBackend:
"""Connect to the Ibis backend"""
backend = ibis.connect(f"{pipeline.pipeline_name}.duckdb")
ibis.set_backend(backend)
return backendIterate over channels dynamically
By using Hamilton’s Parallelizable and Collect types for type annotations, a “for each” loop is created to retrieve Slack messages. Instead of looping over channels in each nodes, we write a series of transforms for a single channel and apply it over each Parallelizable branch. In addition to creating simpler code, these branches can easily be parallelized using your preferred approach (Ray, Dask, multithreading, and more, see documentation) without any refactoring!
def channel(selected_channels: list[str]) -> Parallelizable[str]:
"""Iterate over channels for which to load messages and replies"""
for channel in selected_channels:
yield channel
...
def channels_collection(channel_threads: Collect[ir.Table]) -> ir.Table:
"""Collect `channel_threads` for all channels"""
return ibis.union(*channel_threads)
Ibis user-defined functions (UDF)
Ibis allows you to register backend-specific operations using @ibis.udf.agg.builtin (see documentation). For instance, we register DuckDB aggregation operations to concatenate strings and collect values in an array.
@ibis.udf.agg.builtin(name="string_agg")
def _string_agg(arg, sep: str = "\n ") -> str:
raise NotImplementedError(
"This registers an ibis UDF. It shouldn't be called directly."
)
@ibis.udf.agg.builtin(name="array_agg")
def _array_agg(arg) -> str:
raise NotImplementedError(
"This registers an ibis UDF. It shouldn't be called directly."
)
def _aggregate_thread(threads: ir.Table) -> ir.Table:
"""Create threads as a single string by concatenating messages"""
return threads.group_by("thread_ts").agg(
thread=_string_agg(ibis._.message), # use `string_agg`
users=_array_agg(ibis._.user).unique(), # use `array_agg`
)You can even execute arbitrary Python code directly from the backend with @ibis.udf.scalar.python. In this case, we call the OpenAI API to generate a summary of the column “thread” for each row (Ibis + DuckDB for RAG). This will run within the same Python process that DuckDB is running in. DuckDB does a good job of ensuring we’re only pulling in the data needed.
@ibis.udf.scalar.python
def _openai_completion_udf(text: str, prompt_template: str) -> str:
"""Fill `prompt` with `text` and use OpenAI chat completion."""
client = openai.OpenAI()
content = prompt_template.format(text=text)
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": content}],
)
return response.choices[0].message.content
def _summary(threads: ir.Table, prompt: str) -> ir.Table:
"""Generate a summary for each thread.
Uses a scalar Python UDF executed by the backend.
"""
return threads.mutate(
summary=_openai_completion_udf(threads.thread, prompt)
)Prompts as code with Hamilton
Hamilton adopts a function-centric approach and limits the need for class hierarchies and config files. For LLM workflows, storing prompts in functions allows one to provide context via the docstrings and inspect lineage when composing complex prompts. For more on this topic see:

Adopting a lightweight Python stack
By now, we’ve created a Python pipeline to load data from Slack into DuckDB and generate thread summaries. This achieves our goal of storing Slack messages at much lower cost than a premium subscription, and gaining the ability to catalog threads by topic and identify unresolved issues. Next steps include setting our data warehouse as the dlt destination and scheduling the pipeline for free using GitHub actions.
If you’re interested to run this pipeline on your own Slack server the code is available on GitHub. If instead of Slack messages you're interested in moving GitHub issues, CRM data or Google Analytics, the dlt, Ibis and Hamilton stack is something you should consider!
Simply load data from a dlt source, write Ibis transformations, tweak the execution for dlt and Hamilton, schedule this with your preferred orchestration framework, and you’re good to go!
⭐ Make sure to star the projects on GitHub
We want to hear from you!
If you’re excited by any of this, or have strong opinions, drop by our Slack channel / leave some comments here! Some resources to help you get started:
📣 join our Hamilton community on Slack — need help with Hamilton? Ask here.
📝 leave us an issue if you find something
📈 check out the DAGWorks platform and sign up for a free trial
We recently launched Burr to create LLM agents and applications