


How well-structured should your data code be?
You need more structure than you think but less than you fear.



In this post we discuss the inherent tradeoff between moving quickly and (not) breaking things. While it is geared towards those in the data space, it can be read and enjoyed by anyone who writes code or builds systems, and feels that they are constantly under pressure to move quickly. We use the framing of a Data Scientist as someone that works in a setting where they prototype ML models, data transformations, etc…, then either hand the work off (usually to someone with “engineer” in their title) or ship it themselves to production. If they do the latter, then they could also have the title Machine Learning Engineer…
A Data Scientist’s Dilemma
If you ask most data scientists about the most important aspect of their role, more often than not you’ll get the same answer:
I need to move as quickly as possible, consequences be damned!*
*emotions added for emphasis.
This routinely trumps concerns around software engineering – building reliable code, testing, documentation, etc… Now, if you ask a data scientist about the most frustrating aspect of their role, you’ll get another answer:
All this technical debt is slowing me down!
[Trigger warning for data scientists, read through to the next paragraph] If you are not familiar with the field of data science (or you are prone to the why can’t you just school of thought), you will naturally be reading this with a frown. The problem feels, in some way, of their own making. After all, isn’t moving too quickly and recklessly in the first place the very cause of this technical debt? And, if they only slowed down to design/refactor more, shouldn’t they be able to escape the rut they’re in and move faster in the future?
This, however, is a naive (if not unempathetic) view. A good data scientist is focused solely on maximizing value for their organization, and thus is delicately balancing conducting new analyses, exploring new spaces, managing relationships with multiple product teams, and integrating new datasets. There just isn’t enough time in the day to do all that while also building good code.1 You can view this as the following pick 2 meme:

If they care about their job, adding value is not only a requirement, but also a reward-lever. Thus the trade-off is between “move quickly”, and “build a good system”. Problematically, as discussed above, the failure to build a good system will, over time, cause even the best data scientists/engineers to eventually slow down.
This forms a dilemma that is crucial to the understanding of how and why data teams need platforms to function effectively. We started this post by presenting this dilemma. We will then concretize properties of a “good” ML system, present a mental model to think about the trade-off, talk about how employing a platform mindset can make it less of a trade-off, and share how the open source platform we’re building at DAGWorks attempts to address these concerns.
What makes ML code “good”?
While multiple professionals may disagree on this question, we will answer it in relation to the trade-off above. At a high level, a good system will not make you hate your colleague (or your previous self) when you work on it. OK, that’s nebulous. What do we mean, specifically? Note that these are not addressing the quality of the ML itself, only the quality of the code/infrastructure:
A good system does not break (often). While never breaking is aspirational (and, practically impossible), adequate fallbacks as well as a good story for testing changes make failure a tail risk, rather than a daily event.
A good system is easy to triage/debug. If you’re woken up in the middle of the night due to a broken ETL/web-service, you want to quickly figure out what part of the system is the cause/trigger. When you’ve identified the source, you need to be able to quickly fix it.
A good system is easy to understand. When you want to share what you’ve built with a colleague, determine the scope of a change you’re planning, or brush up on your knowledge of your code for analysis, you want to be able to quickly understand a system. While documentation is important, it is second to inherent readability, which requires simplicity and structure.
A good system is easy to modify. I may have a bridge to sell you if you genuinely believe that any code you write will be shipped to production, used, and never touched again. Not only will you have to routinely identify and fix bugs, iterate on the modeling techniques, and iron out assumptions that you (intentionally or unintentionally) made when building it, but you will also have to make larger changes. With any degree of success, you will likely be required to repurpose your system with new data sources, scale it to new use-cases, or even build a new system that shares elements of the current one.
None of these points are particularly controversial, but it is good to align on what good means so we can really dig into how to think about this trade-off in a productive manner.
Quantifying the Tradeoff
We’re going to leverage a concept from quantitative finance (a passion of mine) to present a mental model for this trade-off. The concept is called the “efficient frontier”. While it was initially developed to determine the optimal portfolio of securities (say, stocks) by balancing risk and reward, it is a useful tool to think about pretty much any trade-off. Trade-offs are represented as a multi-objective optimization problem. X and Y are both objectively good, but the more of X you get, the less of Y you get, and vice-versa. The solution to optimize both X and Y is a curve, (a set of points in {X,Y} space) that represent the optimal Y for a given X.
To tie this back to the system-quality/quick moving tradeoff, a data scientist’s approach can be modeled something like this:
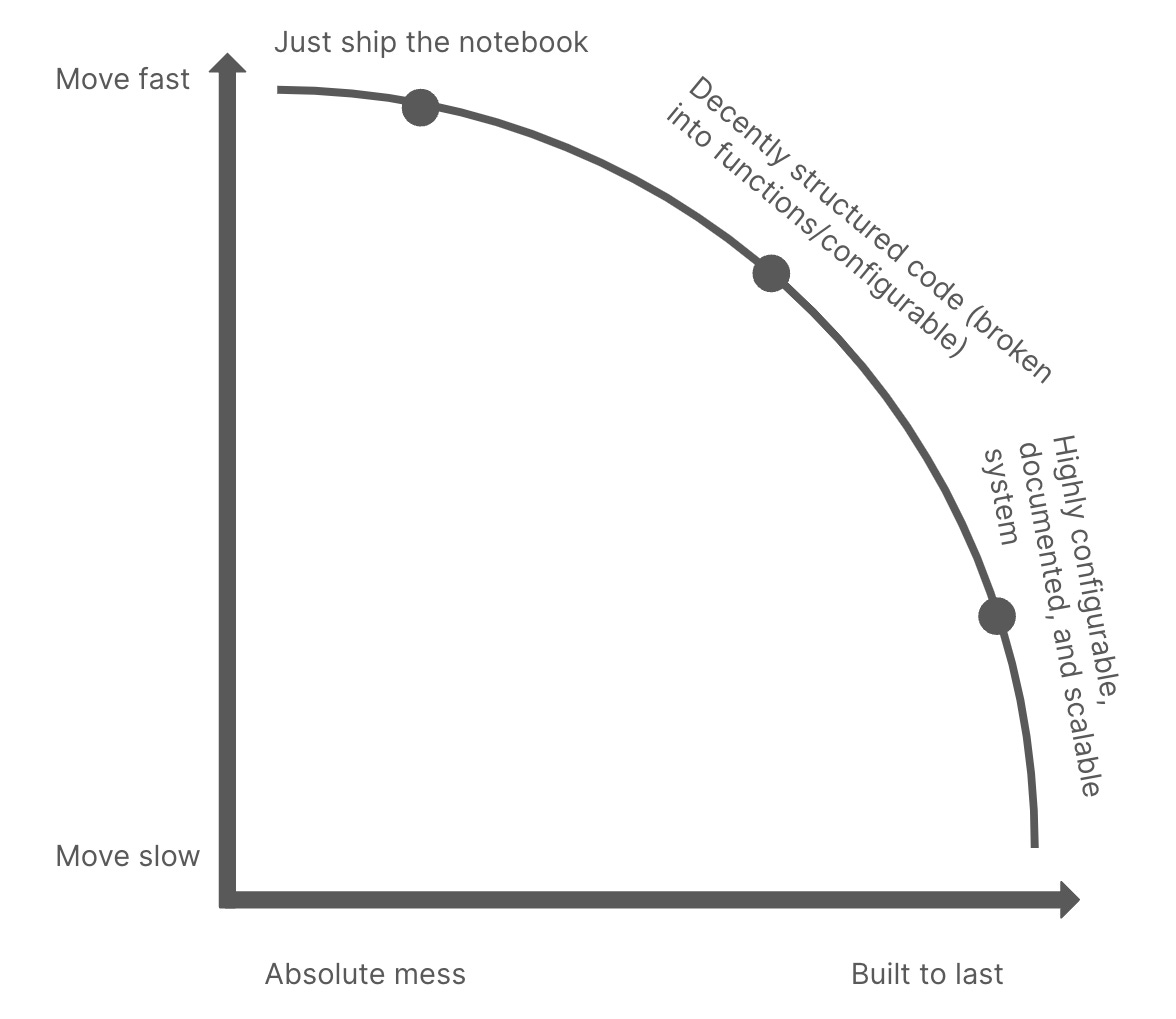
The illustration above demonstrates an optimal curve – the set of working modes that are considered rational. As long as your working mode resides along that curve it is justifiable. Anything inside the curve is suboptimal, and you shouldn’t be there.
So, as a first question when determining how to structure your code for production, you should ask yourself: Am I working along the efficient frontier? Another way of thinking about this is, for the required level of system quality, could I be moving any faster? And for the speed that I’m moving at, could I be building a better system? If the answer is yes, you could be moving faster, or yes, you could be building a better system, then you have no excuse. You should be moving faster.2
A Platform Mindset
Let us put on our platform team hat for a bit. While you may not have a team to build a platform for you, you will inevitably wear the platform engineer hat multiple times in your career, e.g. building tools for yourself and others. How do you approach doing this? A platform mindset is less opinionated about where you reside along the curve (within reason, that is), than (A) concerned about ensuring you have the information you need to build at any point along the efficient frontier (rather than within it) and (B) focused on improving the curve itself to allow for more optimal results that require less of a trade-off.

(A) in the image is largely the job of evangelizing technology and bringing yourself and others up to speed (documentation, presentation, and socialization are all critical skills – see our post on the ADKAR method for change management for a detailed guide). (B) in the image involves building new capabilities/toolsets, as well as understanding workflows/*which* tool sets to build. Also, note the shape of the new curve – it is intentionally less of a curve, and more of a right angle. This means that the trade-offs are less considerable. In a world with an ideal platform, building code to last requires far less of a sacrifice in speed-to-production, or perhaps none at all.
Before we dig into the core example of this post, let’s go over a few examples you might have encountered in your professional life to make (A) & (B) more concrete:
Learn to use spark to make data scientists more efficient. Make spark easier to use/make compute provisioning simple to make it easy to build systems that interact with spark in a standard, scalable way that leverages best practices.
Learn to use AWS so data scientists can provision a database to use for feature engineering. Build/integrate a feature store to make it easier to manage features and thus, possible to be more efficient and build systems with fewer moving pieces.
Learn to use Sphinx/ReST for documentation management. Build out (or buy) a self-hosted documentation platform to make it so that every project has automatically generated documentation that is easy to expand/fill out.
… and so on, the possibilities are endless. The exciting thing is that justifying new investments can all be done by quantifying the efficiency/quality trade-off.
Hamilton
Now that we’ve discussed the natural trade-offs and how to ameliorate them, let’s go over a platform that we believe models this “trade-off reduction” for which a platform mindset is generally responsible.
Overview
Hamilton is a standardized way to build dataflows (any code that processes data) in python. The core concepts are simple – you write each data transformation step as a single python function, with the following rules:
The name of the function corresponds to the output variable it computes
The parameter names (and types) correspond to inputs. These can be either external inputs or the names of other upstream functions
The code below represents a simple (3-node) DAG for training and executing a model to run predictions on a dataset.
# simple_pipeline.py
def digits_df() -> pd.DataFrame:
"""Load the digits dataset."""
digits = datasets.load_digits()
_digits_df = pd.DataFrame(digits.data)
_digits_df["target"] = digits.target
return _digits_df
def digits_model(digits_df: pd.DataFrame) -> svm.SVC:
"""Train a model on the digits dataset."""
clf = svm.SVC(gamma=0.001, C=100.)
_digits_model = clf.fit(
digits_df.drop('target', axis=1),
digits_df.target
)
return _digits_model
def predicted_digits(
digits_model: svm.SVC,
input_digits: pd.DataFrame) -> pd.Series:
"""Predict the digits."""
return pd.Series(digits_model.predict(input_digits))
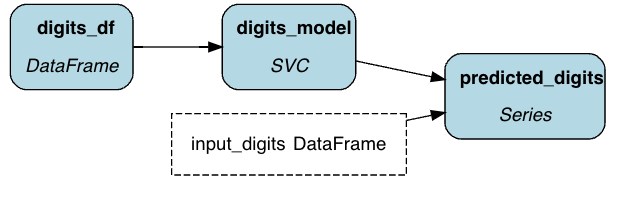
You then run these using a “driver”, which specifies how/where to run the code.
from hamilton import driver
import simple_pipeline
dr = driver.Driver({}, simple_pipeline)
result = dr.execute(
[
"predicted_digits", # this is what we're requesting to be computed
],
inputs={"input_digits": load_some_digits()}
)You can represent any set of data transformations with relative ease – we’ve seen people building ML pipelines, expressing feature engineering workflows, representing RAG workflows, constructing microservices, etc…
A Good System
We open-sourced Hamilton with the lofty goal of reshaping that trade-off curve for the entirety of the data industry. Specifically, we aim to make it so there is little to no trade-off between quickly getting a data pipeline/model to production and allowing it to consist of “good” code. As we defined above, Hamilton makes it easy to adhere to our set of principles:
A good system does not break (often). As dataflows in Hamilton consist of python functions, it is easy to build unit tests for simple logic. Furthermore, it is easy to build integration tests for more complex logic/chains of functions. Mocking is done by data injection, rather than complex mocking libraries.
A good system is easy to triage/debug. Any error can be traced to an individual function, which is named according to its role in the final result. If data looks weird, Hamilton functions provide easy introspection on output data/dependencies, so you can trace the source of the data up the DAG scientifically. Hamilton also supports runtime data quality checks that are extensible, so you can fail quickly if data assumptions are invalidated. In most other systems, figuring out why data is weird is a near-herculean task.
A good system is easy to understand. Hamilton provides multiple benefits here – functions are self-documenting so you can understand the inputs to any output variable simply by looking at the code. Furthermore, Hamilton has a sophisticated visualization capability that allows you to track lineage and understand execution plans. As more individuals in an organization adopt Hamilton, the effects of standardization naturally result in a network effect that makes each subsequent pipeline easier to read and manage.
A good system is easy to modify. Making and understanding changes is trivial. Changes in Hamilton are inherently targeted to specific functions, allowing you to isolate and test the desired effect. Furthermore, functions are naturally broken into modules, which encourage reuse and composition.
A New Curve
You might be wondering I like all these benefits, but don’t I have to learn a new system? And won’t that make me slower? Yes, you do have to learn a new system, but as we showed above, it’s just python functions! Furthermore, there’s a trick – you don’t always have to use Hamilton to its fullest extent. Hamilton supports multiple points along the efficient frontier between good code and quick development, and makes it easier to move along that curve. Let’s make this more concrete by looking at some different goals for getting data projects to production:
[30 mins] You just want to get something to production for an A/B test. After writing in a jupyter notebook:
[15 mins] Copy your code from a jupyter notebook to a few Hamilton functions
[15 mins] Slap on some check_output annotations to ensure schemas are what you expect
[2 hr] You want to get something to production that you think will last a year before rewriting, and maybe one other data scientist will touch. Do the above, and:
[40 mins] Add a development versus production mode with `@config.when`
[40 mins] Add a few other output validations to form a self-documenting set of tests
[40 mins] Ensure your function docstrings are well-written/suggest caveats
[5 days] You want to build a highly robust ML pipeline that you expect to have multiple important downstream consumers and will form the basis of your projects moving forward. Do most of the above, and:
[1 day] Utilize the materializer framework with a set of platform-built data adapters to decouple execution, perhaps contribute back to Hamilton or add to a custom your-company-specific library for adapters.
[1 day] Add pre/post node execution hooks to trace execution in a distributed tracing system (or use DAGWorks’s telemetry capabilities!).
[1 day] Add configurations to run the same inference code in online and batch context, with optional business logic implementations (blog).
[1 day] Squash the ifs/elses in your code to use `@config.when` for different configurations in which you’ll run your model.
[1 day] Add unit tests/integration tests.
[10 days] You want to build a feature engineering pipeline in which you iterate on the implementation and track versions of a variety of individual features
[3 days] Refactor your pipeline to include one function per feature
[3 days] Refactor your online/offline implementation to be able to generate features in batch and streaming/real-time mode
[4 days] Build out a custom documentation tool (or use DAGWorks’s feature catalog!).
While not exhaustive, the capabilities we outlined demonstrate how you can use Hamilton to quickly and easily write good quality production code, while moving seamlessly along the trade-off space. To visualize in terms of our efficient frontier, we have the following:

Combining Hamilton with a platform mindset affords plenty of opportunity to move the curve more. Between data adapters, tagging schemas, and plugging into your specific orchestration system (e.g. airflow, prefect), you should be able to make this even less of a trade-off.
Wrapping up and Getting Started
In this post, we went over a catch-22 data scientists often encounter, in which their incentives are aligned to favor moving quickly over building good systems, which are required to move quickly in the long run. We drew from quantitative finance to talk about the efficient frontier, a model for quantifying that trade-off. We then discussed how leveraging a platform mindset can make it less of a trade-off, and how Hamilton can be that platform, giving you and your team the choice to “pick three”, and not just two.
As Hamilton is a simple framework, getting started is as well. We suggest you out tryhamilton.dev then skim through the ML reference architecture post, or look through the examples.
We Want to Hear from You
If you’re excited by any of this, or have strong opinions, drop by our Slack channel / or leave some comments here! Some resources to get you help:
📣 join our community on Slack — we’re more than happy to help answer questions you might have or get you started.
⭐️ us on GitHub
📝 leave us an issue if you find something
Other Hamilton posts you might be interested in:
While you may claim that this is the case for everyone (we all have to add value), if you do not feel the pressure to perform trade-offs then your job sounds like a walk in the park. If you *do* feel the pressure, then it is likely that you, too, have to sacrifice something in exchange for building value and can empathize. What you have to sacrifice is a matter of incentives – for data scientists the incentives are often clearly aligned with revenue optimization and risk reduction, and thus can be known to supersede other needs…
If you want to really nerd out, I’ve made an implicit assumption that this is a convex, smooth, and well-defined/understood function. E.G. that if you *can* move faster/build a better system, then it requires just a little bit of change, and that will always be doable/you’ll always know whether its a good idea. In reality this is not the case – moving faster requires learning frameworks/thinking in new ways, which is often why people don’t want to do it. Furthermore, you can’t always know whether a framework or new approach will solve your problem unless you put in some time. That said, I argue that this is approximately convex/smooth, and this gets truer as you get more experienced. Learning new frameworks/knowing *when* to learn new frameworks should be much easier for a stronger engineer – meta patterns emerge and experience provides valuable intuition.