
Parallel Fault-Tolerant Agents with Burr/Ray
Leverage Burr's new parallelism capabilities to build fault-tolerant, distributed multi-agent systems


Note: This is a continuation of our previous post on parallel agents. While we conduct a brief overview, we recommend reading it for more context. If you have read it, skip to the Parallelism Improvements section.
Introduction
Many AI applications start off simple – you query some hosted model, do a little bit of prompt engineering, process/store/index the result, and stream it back to the user. You model this as a simple ping-pong application – (AI → Human → AI, etc…). Inevitably, as you hit some success, you will need more from your application. The natural next step is to enable it to call tools, or dive into a more complicated research question (E.G. with chain of thought prompting). This is when it turns into an agent – an AI system that dynamically directs their own processes and tool-usage, either with or without human input. An agent is often modeled by a graph with state – it has a set of capabilities and needs to dynamically decide the order.
As your agent’s capabilities grow in complexity, you likely start to realize that it needs to execute multiple tasks at once – generate several candidates for user/LLM selection, leverage various tools simultaneously, etc… While you will still model this as a graph, you end up being in multiple states at once, and have to worry about distributing the computation and coordinating state between tasks. Furthermore, you have to now deal with a host of additional challenges — what happens if one or more of your agents fails, or disconnects from the parent processes? How do you provision specific resources and orchestrate execution in a distributed system?
In this post we show how the Burr library helps you solve these problems. In particular, we will be executing parallel sub-agents/workflows on Ray and persisting the state to enable easy restart from failure. We will:
Dig into Burr/why we built it
Briefly walk through one of Burr’s Parallelism APIs and show an example of generating poems
Show how to improve the implementation of parallelism in two ways
Improve reliability through checkpointing
Distributed agent calls on Ray
Wrap up – talk through other applications/directions for future work.
Burr
Burr is a lightweight Python library you use to build applications as state machines. You construct your application out of a series of actions (these can be either decorated functions or objects), which declare inputs from state, as well as inputs from the user. These specify custom logic (delegating to any framework), as well as instructions on how to update state. State is immutable, which allows you to inspect it at any given point. Burr handles orchestration, monitoring, persistence, etc…).

You run your Burr actions as part of an application – this allows you to string them together with a series of (optionally) conditional transitions from action to action.

Burr comes with a user-interface that enables monitoring/telemetry, as well as hooks to persist state/execute arbitrary code during execution.
You can visualize this as a flow chart, i.e. graph / state machine:

And monitor it using the local telemetry debugger:

While the above example is a simple illustration, Burr is commonly used for AI assistants (like in this example), RAG applications, and human-in-the-loop AI interfaces. See the repository examples for a (more exhaustive) set of use-cases.
A multilayered API for parallelism
To allow for agent-level parallelism, burr uses recursion as a core primitive. No matter how small the sub-application is, each parallel branch gets run in its entirety under the context of a parent action, as a set of separate, simultaneous burr applications. Conceptually, parallelism in Burr uses a simple map reduce pattern.

While there are many ways to specify the sub-actions (see the docs on parallelism), we will be showing an example of the MapStates API. The user implements a class that takes the state in as an input, splits it out into multiple separate states (one for each task), runs each of those, and joins the results.
To demonstrate, let’s write an agent that takes a prompt and generates a poem in multiple styles from that prompt. To generate the poem, it will delegate to a write/edit loop that does a few iterations to improve the poem.
Our overall structure will look like this – note that this graph does not include the details of the sub-applications:
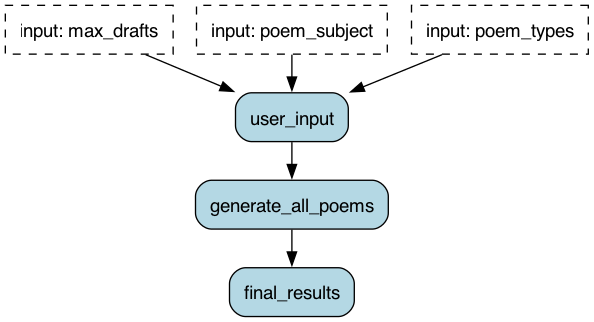

The user provides workflow-level parameters (poem_types, poem_subject, and max_drafts). From these, we manipulate the state, and generate a sub-application from each step. The most interesting part is the distribution — E.G. the use of MapStates. The code looks like this:

To tie this together, we’ll include this action as part of our overall application:

Now we’ve got all we need to run! We execute as we would any normal application – by default, the sub-applications will be spawned in threads, which will be joined when they are done. This is easy to follow in the UI – you can see an application with multiple child applications.

You can also click to expand them individually:
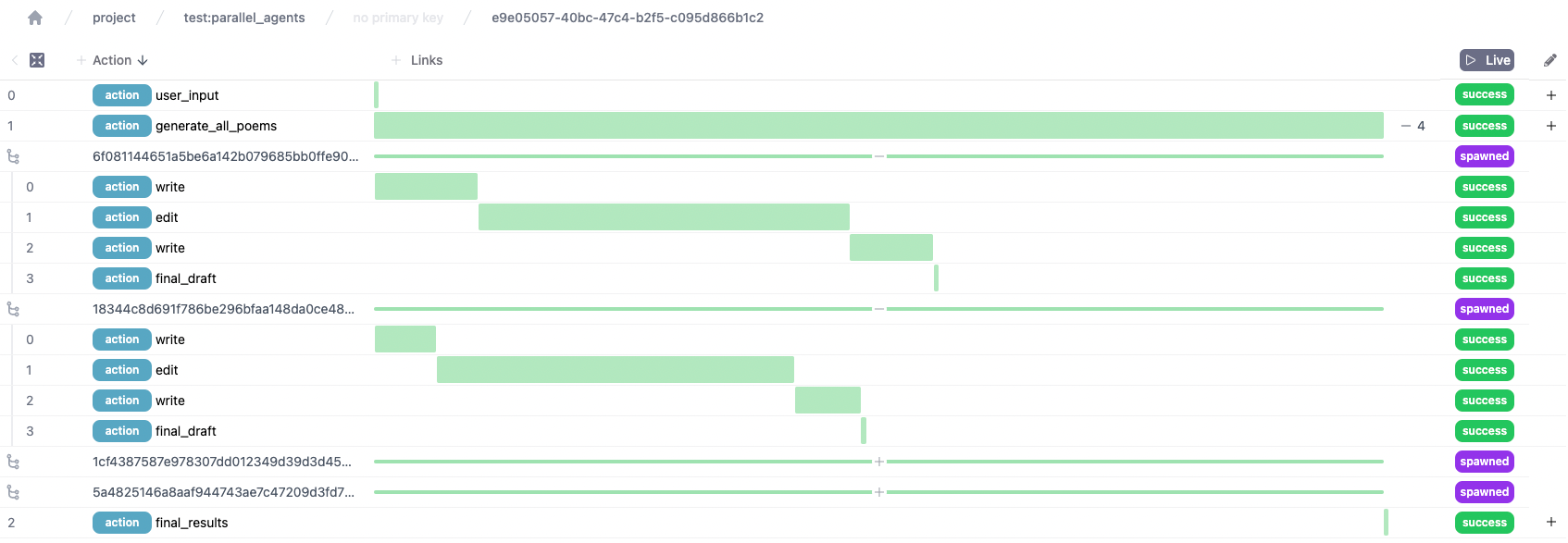
And view state for the sub-applications inline (in case you wanted an in-depth analysis of a limerick based on a state machine…).

When you click on one of the child applications, you will see a link back to the spawning parent:

You can also annotate the workflow, and track additional data with opentelemetry, giving you full visibility into the way your sub-applications function.
Parallelism improvements
While Burr has capabilities to make launching, waiting for, and joining tasks easy, it additionally provides two advanced APIs to make parallelizing more powerful.
Persistence of sub-agents/workflows for fault-tolerance with checkpointing
Customization of execution to run on a task orchestrator (such as Ray)
Fault-tolerance with inherited persisters
If the sub-applications fail, we will need to start where it left off – either for a retry or a manual adjustment (of state/code). To enable this, Burr leverages the persister framework. Specifically, it allows child agents/workflows to inherit their parent’s persisters. This is enabled by default in the MapActions, MapStates, and MapActionsAndStates interfaces. It works as follows:
The parent task instantiates a set of sub-applications, with a stable ID (this is currently dependent on the task order, but will be customizable in the future)
Each sub-application clones the parent application, creating a new application ID with a stable hash of the parent ID and the unique child ID
These clones also copy the persister object that the parent has – ensuring that the configuration matches
When sub-applications are executed, they persist state according to the persister they instantiated
Thus when an application fails – either when the parent task exits early, when a child fails randomly, or when the connection is lost, it can pick up from where it left off on the next instantiation with the same state. All tasks that are complete will effectively be no-ops (relaunched from a final state), and those that are in progress or have not started will resume at the latest state they persisted.
To ensure that this works, you need to add persistence to your parent application with the initialize_from API – the settings will cascade to the child apps, so that if a parent knows to start from where it left off, the child will as well.
Practically, this looks like this (using the SQLite persister for simplicity — if you’re doing true concurrent systems you’ll likely want a more multi-tennant database):
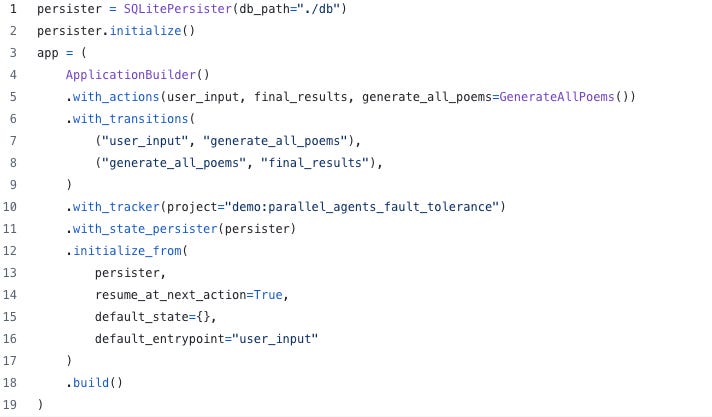
Note that you can further customize the persistence of child apps by overriding the state_initializer or state_persister implementation in your subclasses.
If you run a regularly failing application in the UI you will see it start from where it left off and eventually complete! In this case we’ve just stuck something flaky in a while loop…

You can also use the Burr UI to dig into the failure reasons with the full stack trace:

Custom Execution with Ray
Subtasks in Burr are, by default, managed with a simple concurrent threadpool (using concurrent.futures.ThreadPoolExecutor). That said, you can actually customize execution with any implementation of concurrent.futures.Executor. To run in Ray, Burr provides an implementation that submits Ray tasks on the user’s behalf, as part of the ray plugin.
To enable, all you need to do is call with_parallel_executor on the application builder, passing it a factory function that instantiates the executor (in this case, the constructor will suffice):
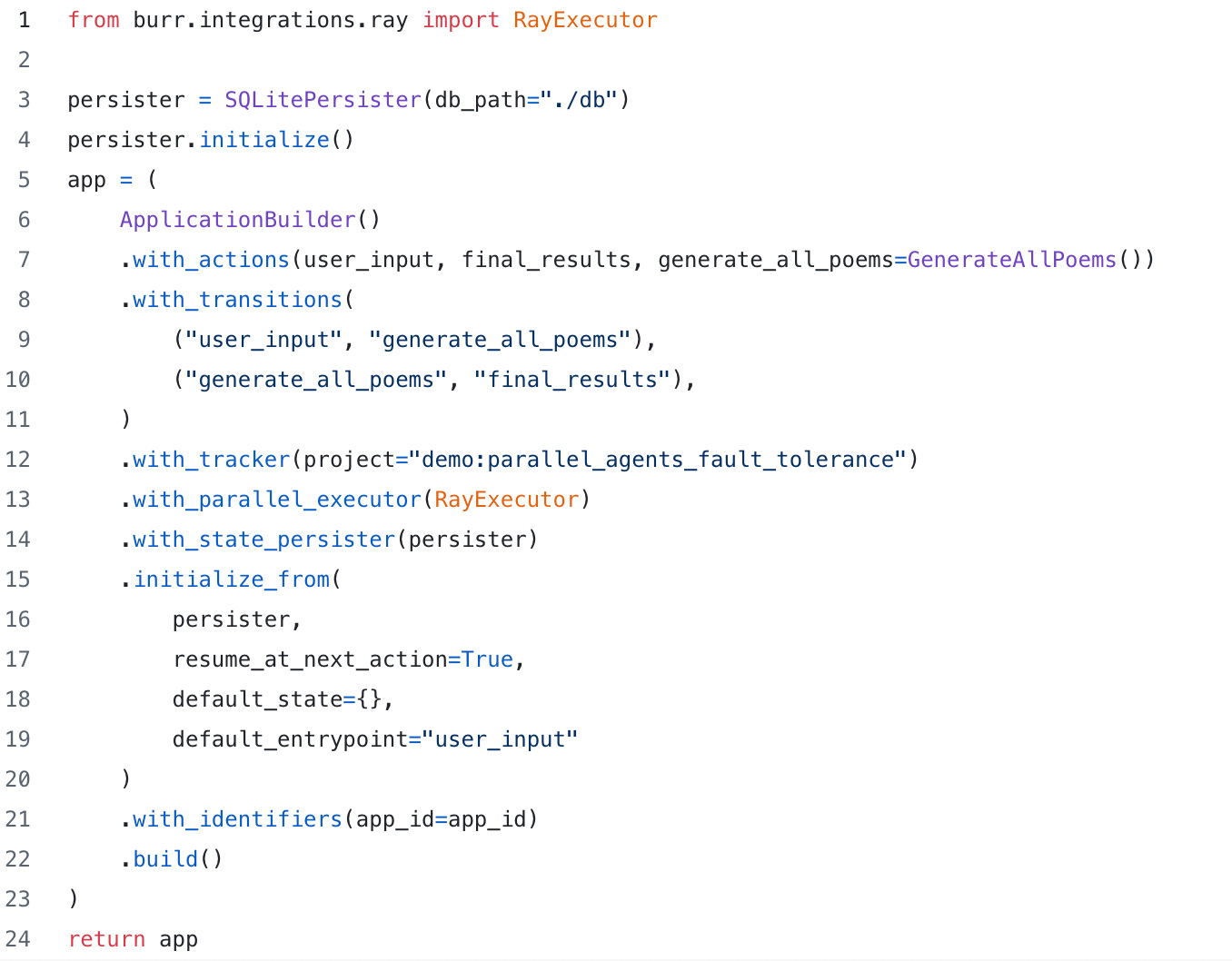
When you run your application, all sub-applications will be tasks on ray! They will write back to the same persister configuration (copied on a per-task basis), so ensure that if you’re doing more than the local testing we’re doing here, you use a truly distributed persister (redis, postgres, mongodb, etc…). Note you will also want to use the s3 based tracking client, or leverage a distributed filesystem, as your local filesystem will likely be unavailable on remote hosts.
Wrapping Up
In the prior post, we outlined Burr’s approach to building parallel agents – demonstrating a few of the APIs to make specifying tasks and joining the results easy. In this post we dug into two more advanced features – ensuring your agent is fault tolerant with checkpointing, and distributing out execution with Ray. While we did not demonstrate further extensions, Burr enables you to build your own concurrent.futures.Executor to run on whatever distributed system you want (dask, runhouse, etc…), or build your own custom persister to match the schema in your DB (please contribute these back if you think they might be general purpose!)
Next steps
While the API is stable and production-ready, we have a host of improvements we are planning. In particular, we want to:
Add customizable IDs for sub-applications, both so you can specify equivalence between runs and observe in the UI
Add additional asynchronous-based parallelism capabilities – while we handle parallelism with asyncio.gather, we will extend customizable execution capabilities to async as well (E.G. allow async execution on Ray).
Consider providing a higher-level execution API (than concurrent.futures) to specify more burr-specific concerns (maximum workers, serialization concerns, messages passed between actions using event-driven/actor model, etc…)
Add the ability to execute any task (not just parallel sub-actions) on a remote host using the same executor
And we’re building quickly! If you have a need for these (or other ideas), please reach out. We’re happy to chat.
Further Reading
If you’re interested in learning more about Burr:
Join our Discord for help or if you have questions!
Subscribe to our youtube to watch some in-depth tutorials/overviews
Star our Github repository if you like what you see
Check out the recent OpenTelemetry integration for additional observability