
Parallel Multi Agent Workflows with Burr
Leverage Burr's new parallelism capabilities to build concurrent multi-agent workflows


Introduction
Many AI applications start off simple – you query some hosted model, do a little bit of prompt engineering, process/store/index the result, and stream it back to the user. You model this as a simple ping-pong application – (AI → Human → AI, etc…). Inevitably, as you hit some success, you will need more from your application. The natural next step is to enable it to call tools, or dive into a more complicated research question (E.G. with chain of thought prompting). This is when it turns into an agent – an AI system that dynamically directs their own processes and tool-usage, either with or without human input. An agent is often modeled by a graph with state – it has a set of capabilities and needs to dynamically decide the order.
As your agent’s capabilities grow in complexity, you likely start to realize that it needs to execute multiple tasks at once – generate several candidates for user/LLM selection, leverage various tools simultaneously, etc… While you will still model this as a graph, you end up being in multiple states at once, and have to worry about distributing the computation and coordinating state between tasks.
In this post we show how the Burr library helps you solve these problems. We will:
Dig into Burr/why we built it
Walk through the API layers burr exposes for parallelism
Show a simple example of generating multiple poems in different styles and presenting them to the user
Wrap up – talk through other applications/directions for future work
Burr
Burr is a lightweight Python library you use to build applications as state machines. You construct your application out of a series of actions (these can be either decorated functions or objects), which declare inputs from state, as well as inputs from the user. These specify custom logic (delegating to any framework), as well as instructions on how to update state. State is immutable, which allows you to inspect it at any given point. Burr handles orchestration, monitoring, persistence, etc…).

You run your Burr actions as part of an application – this allows you to string them together with a series of (optionally) conditional transitions from action to action.

Burr comes with a user-interface that enables monitoring/telemetry, as well as hooks to persist state/execute arbitrary code during execution.
You can visualize this as a flow chart, i.e. graph / state machine:

And monitor it using the local telemetry debugger:

While the above example is a simple illustration, Burr is commonly used for AI assistants (like in this example), RAG applications, and human-in-the-loop AI interfaces. See the repository examples for a (more exhaustive) set of use-cases.
A multilayered API for parallelism
To allow for agent-level parallelism, burr uses recursion as a core primitive. No matter how small the sub-application is, each parallel branch gets run in its entirety under the context of a parent action, as a set of separate, simultaneous burr applications. Conceptually, parallelism in Burr uses a simple map reduce pattern.

The parent action broadcasts the state to multiple sub-applications (run/controlled by the parent action), each of which has their own state – a transformation of the parent’s state. These are run, waited for, and the result is merged to form a final state for the parent action, which downstream actions consume. While the spawning application and the sub-applications it spawns are largely decoupled, Burr framework provides two features to make this process easier:
An API allows for cascading of telemetry from the parent to the child application – the UI is aware of the parent-child relationships, and provides bidirectional links + inline expansions in the trace view
Burr provides tooling to make the process of launching tasks, joining/merging state, and tracking linkage automatic.
For (2), Burr has three different API layers – the implementation of each leverages those below. They are:
1. Full control
With the lowest-level API layer, you launch and manage your own tasks, linking them together with the tracker. You are responsible for forking/joining processes, wiring persistence/tracking, etc… to the child applications, and setting up sub-applications. While we won’t go over this in the blog post, you can read about it in the docs.
2. Task-based map/reduce
You can also specify a series of tasks. You did this by implementing the TaskBasedParallelAction class, which produces a generator of SubGraphTasks, each of which specifies the state/application ID for an input. While you still have to wire through some application-level concerns (tracking/persistence), it handles execution. You then specify how to reduce/join the state with a simple reduce function. Again, we will not cover this in the post. Read more in the docs.
3. State/action-based map/reduce
You can specify either a set of actions or a set of states to map over. If you specify both, it will take the cartesian product of the actions/states. There are three different classes to implement – MapActions, MapStates, and MapActionsAndStates (cartesian product). We will be showing an example of the MapStates implementation during the rest of this – hold tight!
Which to choose?
It all depends on how much control you need, but you should choose the greatest layer of abstraction that effectively models your problem. Many agentic shapes we’ve found can be represented as a simple map over either actions/states, which is why we made it the top-level interface. Otherwise, if you want a full set of executions for an experiment/comparison, you’ll likely leverage the cartesian product, and if you have specific logic that doesn’t boil down to actions/states, you’ll use the task-based approach. The fully-controlled API is reserved for odd cases in which the map/reduce pattern does not effectively fit. E.G. if you’re streaming parallel results out, have a few longer-running tasks and want to leverage task inter-communication, etc… For the latter two interfaces, you can customize execution approach, tracking behavior, persistence behavior, and more.
Generating Poems in Parallel
Let’s go over a fairly simple example of the MapStates API – we will be writing an agent that takes a prompt and generates a poem in multiple styles from that prompt. To generate the poem, it will delegate to a write/edit loop that does a few iterations to improve the poem.
Our overall structure will look like this – note that this graph does not include the details of the sub-application:
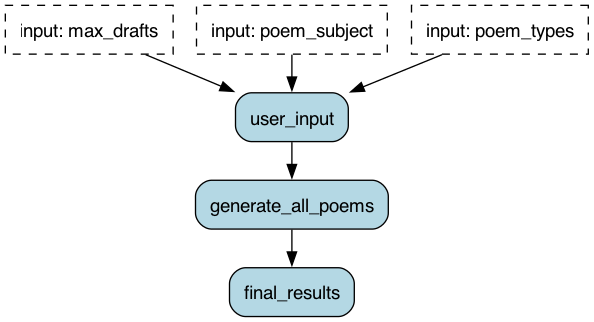

The user provides workflow-level parameters (poem_types, poem_subject, and max_drafts). From these, we manipulate the state, and generate a sub-application from each step. The most interesting part is the distribution — E.G. the use of MapStates. The code looks like this:

To tie this together, we’ll include this action as part of our overall application:

Now we’ve got all we need to run! We execute as we would any normal application – by default, the sub-applications will be spawned in threads, which will be joined when they are done. This is easy to follow in the UI – you can see an application with multiple child applications.

You can also click to expand them individually:
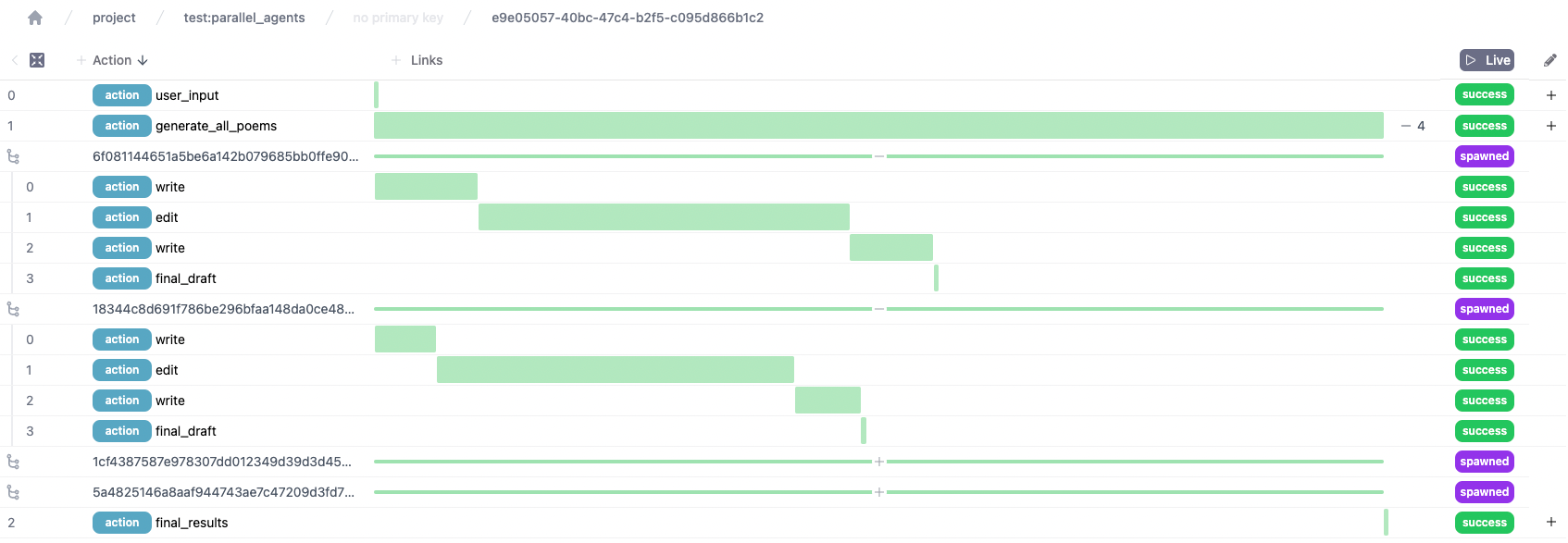
And view state for the sub-applications inline (in case you wanted an in-depth analysis of a limerick based on a state machine…).

When you click on one of the child applications, you will see a link back to the spawning parent:

You can also annotate the workflow, and track additional data with opentelemetry, giving you full visibility into the way your sub-applications function.
Wrapping Up
Comparison
Burr’s approach towards parallelism differs from other libraries, largely due to the design goals. While langgraph took a heavier-handed pregel-based approach to orchestrate running actions over state, Burr aims towards simplification. The core philosophy is central management and execution – launching tasks, delegating to a single node, and joining the results. While talking to our users, we found that the vast majority prioritized clear control flow primitives that enabled them to reason about what their agents are doing and where. By not taking a state-convergence based pregel approach and then breaking its assumptions to allow a human-in-the-loop control flow, we think our implementation is simpler to understand top to bottom. You could already roll your own parallelism in a Burr action manually, so with this new functionality we focused on simplifying that and integrating parallelism deeply within the Burr UI for a better observability and user experience.
Next steps
Although we covered the basics of parallelism, there is still quite a bit more to cover. In particular – what happens when you lose track of your execution halfway through (E.G. accidentally hit ctrl-c during execution)? Can you ensure all tasks will restart where they left off? Furthermore, multithreading won’t always work – especially if you have anything that requires specialized compute. In the next post, we will talk about how to make this truly distributed with Ray, and ensure that it is fault-tolerant – upon failure, it can resume where it left off.
Further Reading
If you’re interested in learning more about Burr:
Find the code for this example here (note this is the same as the next post)
Join our Discord for help or if you have questions!
Subscribe to our youtube to watch some in-depth tutorials/overviews
Star our Github repository if you like what you see
Check out the recent OpenTelemetry integration for additional observability