
Agentic Design Pattern #1: Tool Calling
The first in our series of agentic design patterns with Burr



Agentic Design Patterns
LLMs have people’s heads spinning. The sheer freedom afforded by an API call is intoxicating – not only can you now *talk* to a computer, but you can use that computer to execute (and even write) code for you!
This has led to an influx of Burr users, many of whom want help modeling their systems. After building a successful chatbot, they inevitably migrate towards building agents. While the word agent is buzzy, we define it as follows: an agent is anything that uses the output of an LLM to do something on a users behalf (rather than just parroting it back to the user).
Although agents are generally seen as new-fangled and chaotic, we’ve noticed the emergence of a few common patterns that enable reliable usage of them in a production setting. In this series of posts, we will explore those – walk through basic dos/don’t's of agent development, and show how to implement them with Burr!
In this post we’ll be talking about how to use “tool-calling” to build an agent that responds to a query by selecting a “tool” to call from a list of “prebuilt tools”, then “using” it. We’ll go over some sample code, then talk about how Burr can help bring this system to production. We assume OpenAI as our LLM, but this example is straightforward to extend to other LLMs.
Note: you can see the code for the demo here and run it yourself/copy+paste to get started!
Before we start, let’s just get some grounding around language…
“Tools” vs “functions” (vs “structured outputs”)
It can be somewhat confusing what these mean. Do agents physically use tools? or do they call functions? or? Are they interchangeable? Are they not? What do they actually mean?
TL;DR: a “tool” and a “function” are synonyms.
We think people make this sound more complex than it really is. For the vast majority of purposes, a “tool” maps to a “function”, where function is the software engineering concept of function. That’s because we’re talking agents that are built via code, and so the simplest way to do something on a user’s behalf, is to invoke (i.e. call/ execute) a function. However, since agents are a higher level concept, we’ll also use a higher level concept, i.e. “tool”, to describe what they can do / use. So in short they’re synonyms and is why you’ll hear a phrase like “tool call” instead of “tool use” because it’s merging “function call” with “tool use”.
To make this more confusing, OpenAI recently deprecated its function-calling API in favor of its tool-calling API (really…) while Anthropic’s documentation refers to it as the entirely unambiguous Tool use (function calling) feature… So the industry has yet to align.
To simplify for the rest of this post, we’ll generally use “tool” to describe the general agent pattern. But where appropriate use the term “function” to actually explain what’s going on (we’ll also drop the quotes).
But what are “structured outputs” then?
When asking an LLM to pick or choose a tool to use, what is returned in the response is usually a JSON representation of the name of the tool and what should be provided to the tool to make it work. Because it is JSON versus free text, it is structured. What people have figured out is that you can co-opt this behavior (e.g. OpenAI’s structured outputs) to make the LLM provide a response that is entirely JSON based, without having an actual tool to use. This can help you generalize outside of specific tool-calling APIs.
While we elect to directly use the tool-calling APIs in this post, adding a library like instructor can help abstract this distinction from you. We leave this as an exercise for the reader…
Burr
First, let’s go over the framework. Burr is a lightweight Python library you use to build applications as state machines. You construct your application out of a series of actions (these can be either decorated functions or objects), which declare inputs from state, as well as inputs from the user. These specify custom logic (delegating to any framework), as well as instructions on how to update state. State is immutable, which allows you to inspect it at any given point. Burr handles orchestration, monitoring, persistence, etc…).

You run your Burr actions as part of an application – this allows you to string them together with a series of (optionally) conditional transitions from action to action.

Burr comes with a user-interface that enables monitoring/telemetry, as well as hooks to persist state/execute arbitrary code during execution.
You can visualize this as a flow chart, i.e. graph / state machine:

And monitor it using the local telemetry debugger:

While the above example is a simple illustration, Burr is commonly used for AI assistants (like in this example), RAG applications, and human-in-the-loop AI interfaces. See the repository examples for a (more exhaustive) set of use-cases.
Knowing which tool to use
LLMs have emerged as a way to determine a user’s intent and also carry that intent out. For instance, say you have a query as simple as:
What is the weather in San Francisco?
Aside from hardcoding the response foggy, this used to be a hard problem. Nowadays, this seems fairly easy – you can just ask an LLM!
State of the art models, however, do not have the capability to answer a question like this as they are largely closed off from the internet (although some tooling has begun to bridge that gap). Instead, their superpower is determining the user’s intent and telling you how to figure it out yourself (LLMs can’t run code, but they can tell you what you should do). So, rather than asking the LLM what the weather is in San Francisco and expecting a result, you should ask the LLM how do I determine the weather in San Francisco, given that I can do X, Y, and Z. X, Y, and Z could be whatever preset tools (i.e. functions) you have. If you’re lucky, X could be “use a simple weather API, given JSON parameters”, and the LLM would know about it – providing the JSON parameters so you can do the call. Providers such as Anthropic and OpenAI have sophisticated APIs to make this easy — they select from a list of tools and generate the parameters.

Zooming in on the “Ask LLM for tool parameters” part of the flow chart above. For the LLM to know that a tool exists, you need to explain the tool to the LLM as part of the context that is sent. Different LLM providers can do this differently, but in general you are going to be doing the following:

Let’s now dive into how you’d set up an agent written in Burr to use an LLM to determine what tool to use and submit a response to the user.
A Straightforward Tool Calling Pattern with Burr
Implementing tool-calling with Burr is just a thin layer on top of any provided LLM API that supports tool/function calling a.k.a. “structured outputs”.
Let’s generalize our use case slightly and move from answering a specific “what the weather is question” to answering any question in general. To set this up, we need to provide the LLM the set of tools that you use to get an answer with. E.G. you have functions that wrap APIs to query the weather, order coffee, text your wife that you love her, etc… And all you want to do is convert natural language (i.e. user queries) to input parameters to use one of those tools.
We will also add a fallback tool that allows the LLM to attempt to answer using its own knowledge (you don’t need a tool to know what 10 x 10 is…).
First, let’s define some functions, i.e. tools. For brevity here we only show our weather_tool.

Not shown but we can also have _text_wife_tool, _order_coffee_tool, and any others we want. We will also have a _fallback function that gives out a simple statement in case we can’t answer using the desired tools or the LLM fails to answer otherwise.
Let’s gather these into a prebuilt list. What we’re doing here is simple — we’re formatting function signatures as the OpenAI compatible type; we’re doing a clever trick of using Python’s inspect module to tell us about the function itself. This means that it’s easy to add new functions, i.e. tools, for the LLM to know about. Alternatively, you could use pydantic here to define the tools. Note: there is additional validation of signatures that we have not shown in the code below.

We now call OpenAI to choose the tool. We model this as specific Burr action. The input is state with the user question, and the output will be the details of what tools should be run and with what values. Note the LLM call was finicky — it didn’t always want to choose a tool, and sometimes got lost in the instructions… But, with a little bit of prompt engineering (experimented on with Burr’s UI), we were able to get reasonable behavior:

The next step is to create a Burr action to exercise the chosen tool. We could model this as a single Burr action that would execute whatever the tool call was. Or, we can use a cool trick to make specific Burr actions for each tool, but still keep the code concise. We can do that with Burr’s .bind() feature, that allows you to define a single action with a parameter and turn that into multiple actions, by “binding” different values for that parameter. In this case, we can parameterize the tool-calling function, binding the tool (i.e. function) to create a Burr action for each tool we have defined (skip to the application builder code to see how). Each of these will take in the tool parameters provided by OpenAI, and output the raw response in some raw (dictionary) format:

We could also have this be a single action that chooses between tools (given the tool set in state), but the nice thing about the one-tool-per-node approach is that we can view all the tools in the graph (see below).
Finally, we’ll have an action that formats the results using OpenAI — this just takes the raw result and puts it in a format the user might like. Note you will likely want to restrict this to some structured object to make it friendly for web rendering, e.g. with a tool like instructor. Below we just return the output straight from OpenAI.

Finally, we tie this all together to create the Burr Application. In this case we’re hardcoding tool names for simplicity, but we could easily use a single dictionary throughout this and the above code to make this code DRYer:

This creates a very reasonable looking graph — we loop back to the input when we’re done so the user can ask another question:

Let’s test this out…

And the result is:
The current weather in San Francisco is clear with no cloud cover, a temperature around 24.81°C (76.66°F), and a humidity of approximately 51%. Wind speeds are mild at about 5.13 km/h, with gusts up to 6.31 km/h. Visibility is excellent at 16 km. There is no precipitation expected, and the UV index is at 0, indicating no immediate health concerns from UV exposure.Yeah, not foggy. Hmm, not sure I trust this whole AI thing…
Is Burr more than I need?
While the API calls are simple, and the code above could be written without Burr, the orchestration + capabilities Burr provides add significant benefits to both development and production.
Modeling with Extensibility
As everything is represented by a graph, the workflow is self-documenting. You can view the graph, read through the application builder and get a good sense of how your LLM is thinking. Furthermore, as you inevitably add more tools (and adjust prompts), you have the guarantee that changes are located in specific Burr actions, and compare code across runs.
Furthermore, should you want to add additional graph-level concerns (error conditions, etc…) you can do so simply by adding actions & edges without touching any of your other code.
Monitoring + Visibility
In addition to ensuring your graph is more readable, Burr comes with a one-line change to add observability that is paired with an open-source user interface. This allows you to debug as you progress. With tool-calling (LLMs can be fickle and occasionally have a tough time matching intent with the tool to use), this is debugging insight is very useful. Should the LLM not give what you desire, you can:
Examine the state
Look through the opentelemetry data for chat completions
Recreate with specific test-cases to iterate and fix the issue
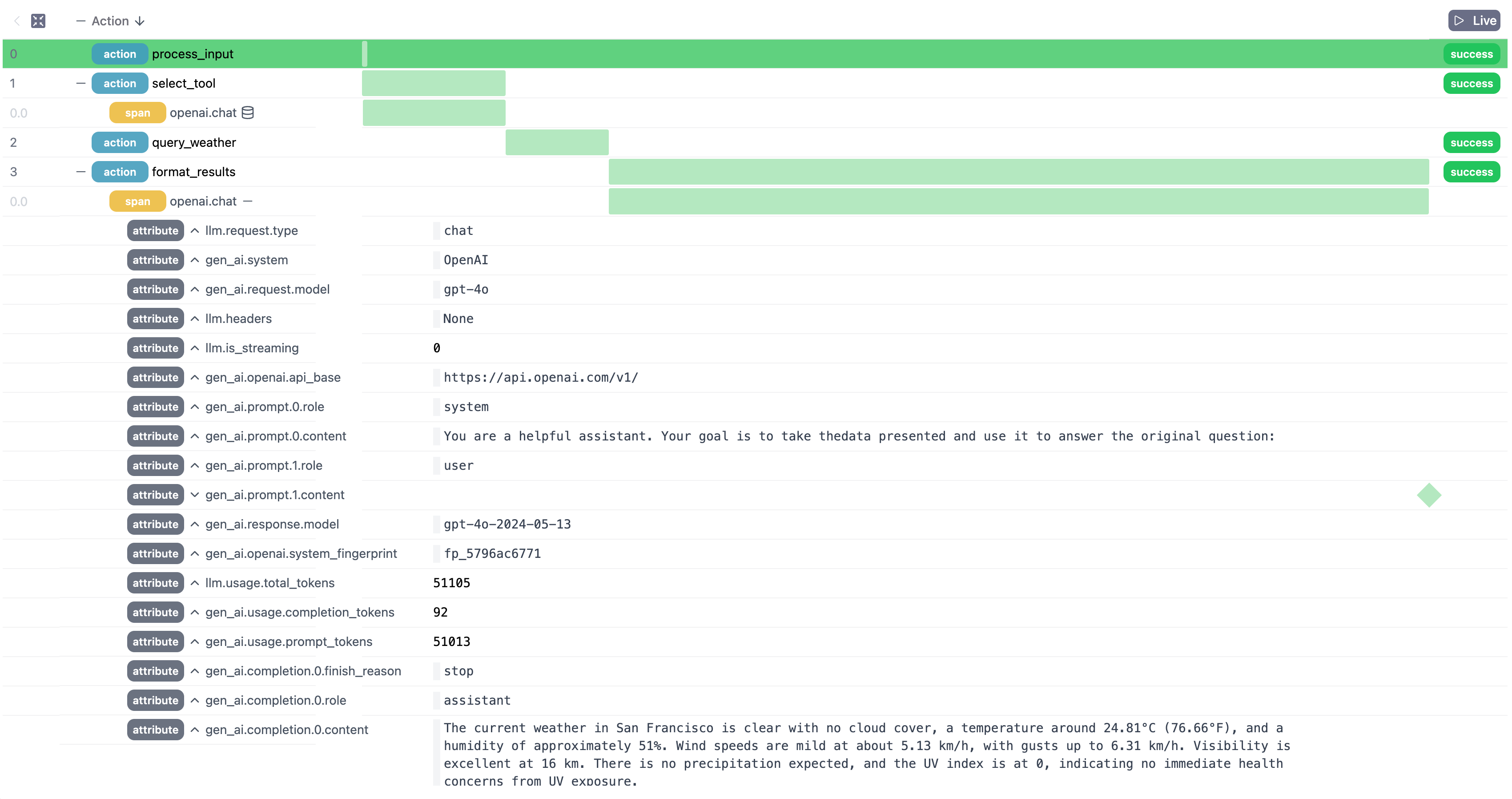

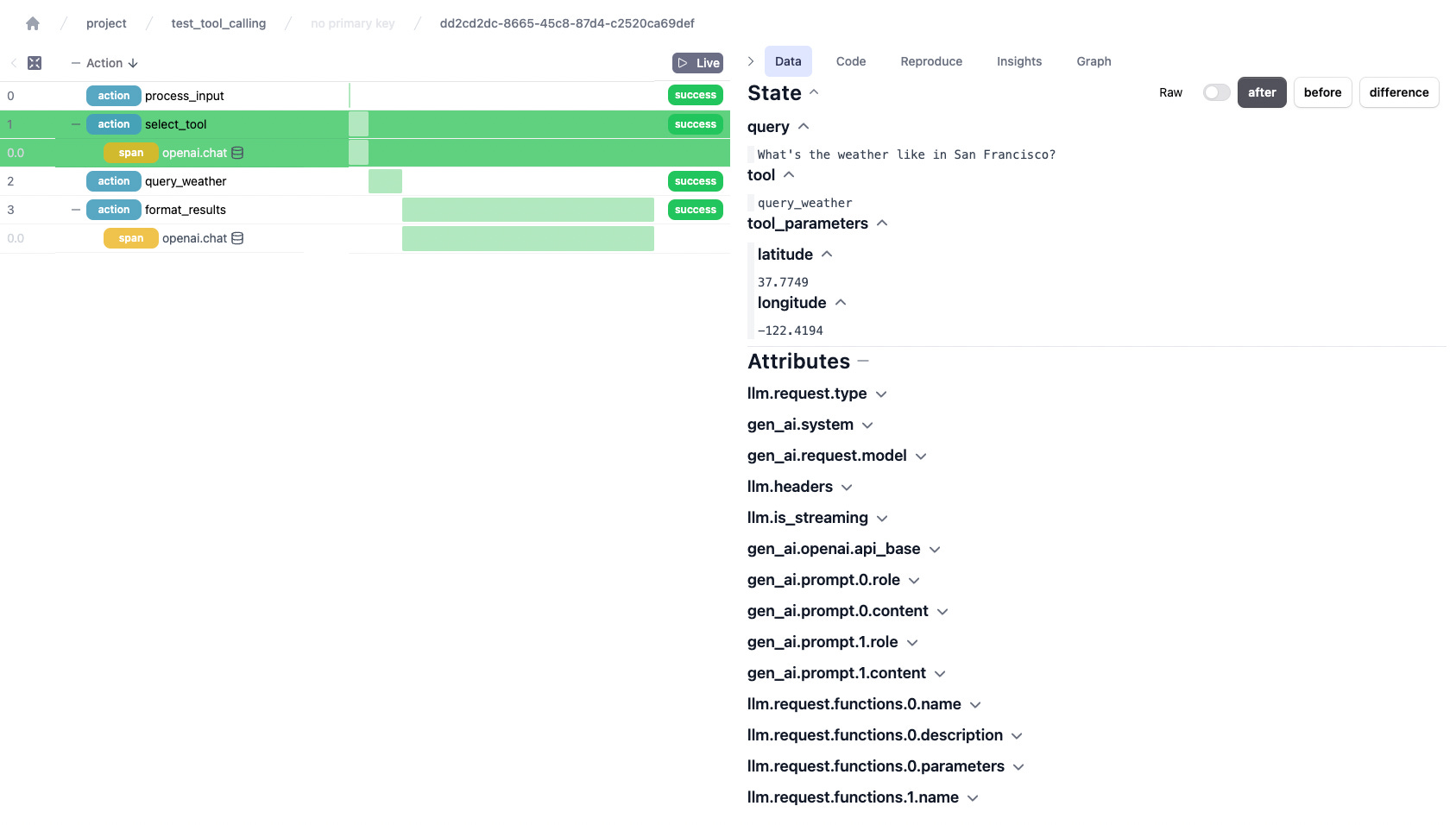
Should your actual tool, i.e. function call, be giving you errors, you can also annotate these tools with the `@trace()` decorator (and even the code inside those functions). What this will do is have those function invocations also logged to the Burr UI!
Additional Production Concerns
Using Burr also makes it easier to ship to/manage your app in production. You can:
Add persistence/track sessions with Burr’s persistence API – another one-line change to hook into the database of your choice
Deploy in a FastAPI server using Burr’s state-typing capabilities
Gather data for evaluation datasets (more documentation on this coming soon…)
Wrapping up/Further Reading
In this post we talked about how to build a simple tool-calling app with Burr + OpenAI.
While this is more of a toy application, we’ve found a lot more profound/powerful agentic patterns that we’ll be talking about in the coming weeks/months. Up next:
How to string together a chain of tools to answer a question/carry out an action
How to query and call a set tools in parallel (E.G. for research)
How to leverage multiple agents to answer a question
How to have agents that work together constructively to answer a question/complete a task
And more! We’re always looking for new use-cases, so if you have one you’re curious about, reach out and we can show you how it would work with Burr!
In the meanwhile,
Join our Discord for help or if you have questions!
Star our Github repository if you like what you see
Check out the recent OpenTelemetry integration for additional observability
See the code for this post among our examples
Fantastic article Elijah 🙌