
Hamilton & Kedro for modular data pipelines
A feature comparison to choose one or both


Writing data pipelines for data science is challenging whether it’s analytics, forecasting, natural language processing, computer vision, or generative AI. Mainly because:
It’s highly iterative. A project typically starts with a business question: “How to increase customer satisfaction?” or “What’s a fair price to buy/sell this item?”, but it doesn’t tell you what to build nor how to build it. You have to try and evaluate multiple approaches to achieve the best possible solution (e.g., data processing, model selection).
Project requirements change. As you move from a proof-of-concept (“0 to 1”) to a robust production system (“1 to 100”) requirements will change and code will need to be updated. For example, read data from storage instead of local files, or use Spark for compute.
Hamilton and Kedro are two open-source libraries to tackle these challenges. Each tool has its approach and picking either one will greatly improve code structure. But now, the Hamilton Kedro plugin provides the best of both worlds! Kedro pipelines be connected to the Hamilton UI for execution observability and Hamilton pipelines can leverage the Kedro DataCatalog.
This post compares both projects for people considering using either one, and it showcases how they can function together.
NOTE. Hamilton employs the term “dataflow” and Kedro uses the term “pipeline”, but they refer to the same concept. This post will use “pipeline” for consistency
Why modularity matters
The key to efficiently iterating over approaches and handling changing requirements is developing modular pipelines. Your codebase should be a library of components that can be connected, added, removed, and swapped, providing the following benefits:
Improve collaboration by dividing tasks and responsibilities by component
Changes to a component should be isolated from others, limiting breaking changes.
Easier to debug since errors are scoped by component.
Go from local development to production by swapping components
Reuse components to reduce duplication and the total amount of code to maintain.
While it’s hard to disagree with the above, it’s not necessarily easy to achieve modularity. When first tackling a problem, using a notebook or an interactive environment helps get a working solution quickly, but it eventually creates code that’s hard to read or reuse.
Here’s some pandas code for analyzing company data:
import pandas as pd
raw_df = pd.read_json("data/pdl_data.json")
employee_df = pd.json_normalize(raw_df["employee_count_by_month"])
employee_df["ticker"] = raw_df["ticker"]
employee_df = employee_df.melt(
id_vars="ticker",
var_name="year_month",
value_name="employee_count",
)
employee_df["year_month"] = pd.to_datetime(employee_df["year_month"])
df = raw_df[[
"id", "ticker", "website", "name", "display_name", "legal_name",
"founded",
"industry", "type", "summary", "total_funding_raised",
"latest_funding_stage",
"number_funding_rounds", "last_funding_date", "inferred_revenue"
]]
n_companies_funding = df.groupby("latest_funding_stage").count()
print("number of companies per funding state:\n")
n_companies_funding.plot(kind="bar")
print("employee count per month:\n", employee_df)By contrast, the same code rewritten using functions with type annotations and docstrings provides a much clearer story.
import pandas as pd
from matplotlib.figure import Figure
def pdl_data(raw_data_path: str = "data/pdl_data.json") -> pd.DataFrame:
"""Load People Data Labs (PDL) company data from a json file."""
return pd.read_json(raw_data_path)
def company_info(pdl_data: pd.DataFrame) -> pd.DataFrame:
"""Select columns containing general company info"""
column_selection = [
"id", "ticker", "website", "name", "display_name",
"legal_name", "founded",
"industry", "type", "summary", "total_funding_raised",
"latest_funding_stage",
"number_funding_rounds", "last_funding_date",
"inferred_revenue"
]
return pdl_data[columns_selection]
def companies_by_funding_stage(company_info: pd.DataFrame) -> pd.Series:
"""Number of companies by funding stage."""
return company_info.groupby("latest_funding_stage").count()
def companies_by_funding_stage_plot(
companies_by_funding_stage: pd.Series
) -> Figure:
"""Plot the number of companies by funding stage"""
return companies_by_funding_stage.plot(kind="bar")
def employee_count_by_month_df(
pdl_data: pd.DataFrame
) -> pd.DataFrame:
"""Normalized employee count data"""
return (
pd.json_normalize(pdl_data["employee_count_by_month"])
.assign(ticker=pdl_data["ticker"])
.melt(
id_vars="ticker",
var_name="year_month",
value_name="employee_count",
)
.astype({"year_month": "datetime64[ns]"})
)Another challenge for data science teams is the absence of coding standards. There are as many ways to code as there are people. How many people like inheriting someone else’s script or notebook? Even for a solo developer, the lack of standardization makes it difficult to step away and come back to their project.
Creating an asset layer
Before we dive into the specifics of Hamilton and Kedro, let’s clarify a common question for either tool: “Where does it fit in my technological stack?”. The excellent white paper on “The Composable Codex” by Voltron Data places modularity at the foundation of the hierarchy of needs for data systems.
It also defines 3 layers for a data system:
Data: the physical representation of data, both inputs and outputs
Execution: perform data transformations
Expression: the language to write data transformations
At DAGWorks, we believe adding two more layers, “Asset” and “Orchestration”, gives a fuller picture of popular data system architectures.
Asset: organizes expressions into meaningful units (e.g., a dataset, a model)
Orchestration: operational system for the creation of assets

The line between the asset and orchestration layers can be blurry. For orchestration, the primary concerns are operational and macro (e.g., scheduling, events, retries). Meanwhile, the asset layer is responsible for structuring code into assets that are meaningful to the business and producing them; the orchestration layer triggers their computation. The asset layer should provide the tooling to validate, test, and manage asset definition changes to foster a complete software development life cycle.
Build your asset layer with Kedro or Hamilton
Creating an asset layer allows data professionals to focus on solving the business problem first and operational concerns later. Defining an asset requires minimally 3 components:
The name of the asset
The transform function to produce the asset
The inputs (other assets) required to compute the asset
In Hamilton and Kedro, the node construct would be assets. Accordingly, a pipeline can be conceived as a directed acyclic graph (DAG) specifying how assets relate and depend on each other.
Hamilton and Kedro provide standardized ways of writing assets and data pipelines. To ground the comparison, we’ll look at the canonical Kedro Spaceflight tutorial and discuss their respective approach to:
Project structure
Asset and pipeline definition
Graphical User Interface (GUI)
See this GitHub repository for the full project comparison
Project structure
Kedro
Kedro brings a principled and opinionated approach to data science projects from beginning to end. Its kedro command line interface (CLI) is the primary way to create projects, create & delete pipelines, or execute pipelines.
You can create a Kedro project with the kedro new command, which will set its foundation by generating files and a directory structure. It should look similar to this:
project-name/
├── conf/
│ ├── base/
│ │ ├── catalog.yml
│ │ └── parameters.yml
│ └── logging.yaml
├── src/
│ └── project_name/
│ ├── pipelines/
│ │ └── pipeline_name/
│ │ ├── __init__.py
│ │ ├── nodes.py
│ │ └── pipeline.py
│ ├── __init__.py
│ ├── __main__.py
│ ├── pipeline_registry.py
│ └── settings.py
└── pyproject.tomlThis structure helps us understand how Kedro separates concerns and brings modularity to a project. Going from top to bottom, we can see:
Data catalog (
conf/base/catalog.yml): Configures how to load and store assets during pipeline executionPipeline parameters (
conf/base/parameters.yml): Values to pass to the pipeline during execution (e.g., ML model hyperparameters)Nodes definition (
src/project_name/pipeline_name/nodes.py): Python functions for the “transform” of your assets. This is where you spend most of your time writing code.Pipelines definition (
src/project_name/pipeline_name/pipeline.py): Define Kedro Nodes from your Python functions and assemble them into a Kedro Pipeline.Pipeline registry (
src/project_name/pipeline_registry): Register the Kedro Pipeline created to make it findable to the CLI and other parts of the framework.Project settings (
src/project_name/settings.py): Set the default configuration and hooks for your pipeline execution.Pipeline execution: Load all of that information and run your pipeline. This is typically done via the CLI command
kedro run, but it can also be done via Python code.

This highly structured approach means all Kedro projects will feel familiar once accustomed to it. This facilitates managing multiple data science projects and onboarding / offboarding team members. On the other hand, it has a lot of moving parts to be aware of. When things break, it might not be obvious where to investigate first. It also means that adopting Kedro for a project (at the beginning or during it) will require a migration period to get set up and familiar.
Hamilton
Hamilton isn’t opinionated about project structure. It aims to be the lightest library in your stack and plays nicely with all of your existing tools and organizational processes. There’s an optional Hamilton CLI with utility functions like creating a visualization of your pipeline or viewing what node changed since your last pipeline version.
For comparison sake, the Kedro project above would look like this in Hamilton:
project-name/
├── src/
│ └── project_name/
│ ├── __init__.py
│ ├── dataflow.py
│ └── run.py
└── requirements.txtHamilton is Python-first and doesn’t rely on YAML (because of its many limitations). The Hamilton approach operates in two layers:
Dataflow definition (
dataflow.py): Python functions that directly define the data transformations and the pipeline. This would be equivalent to both Kedro’s node definition and pipeline definition steps.Dataflow execution (
run.py): Python code to execute your pipeline. This would be roughly equivalent to Kedro’s project settings, pipeline parameters, data catalog, and pipeline execution steps.
Since everything is Python code, you could have pipeline definition and execution within the same Python file or even in a notebook! This low footprint simplifies the deployment of Hamilton projects. However, Hamilton has an opinionated way of writing Python functions (more on that in the next section). It’s easy to adopt when starting a project, and migrating will require you to rename functions which could be trivial or not depending on your existing codebase.
Asset and pipeline definition
The structure of a project doesn’t change too much over its lifetime once decided. A more significant differentiator between Kedro and Hamilton is how they define assets and pipelines. It’s important to consider the pros and cons of each approach since this is where you’ll spend most of your time during a project.
As alluded to previously, Kedro decouples the transformation function (nodes.py) and the nodes (assets) + pipeline definition (pipeline.py) while Hamilton couples these 3 steps in a single place (dataflow.py).
Kedro
For Kedro, nodes.py contains regular Python functions. Function names use verbs and refer to “the action of the function”. They define a task to complete.
# nodes.py
import pandas as pd
def _is_true(x: pd.Series) -> pd.Series:
return x == "t"
def preprocess_companies(companies: pd.DataFrame) -> pd.DataFrame:
"""Preprocesses the data for companies."""
companies["iata_approved"] = _is_true(companies["iata_approved"])
return companies
def preprocess_shuttles(shuttles: pd.DataFrame) -> pd.DataFrame:
"""Preprocesses the data for shuttles."""
shuttles["d_check_complete"] = _is_true(
shuttles["d_check_complete"]
)
shuttles["moon_clearance_complete"] = _is_true(
shuttles["moon_clearance_complete"]
)
return shuttles
def create_model_input_table(
shuttles: pd.DataFrame, companies: pd.DataFrame,
) -> pd.DataFrame:
"""Combines all data to create a model input table."""
shuttles = shuttles.drop("id", axis=1)
model_input_table = shuttles.merge(
companies, left_on="company_id", right_on="id"
)
model_input_table = model_input_table.dropna()
return model_input_tableThen, in pipeline.py, we start by importing functions from nodes.py. We create Node objects (assets) and a create_pipeline() function that returns a Kedro Pipeline. For each node (asset), we need to manually specify its transformation function, node name, input(s), and output(s). The key part is matching the output names to the input names of other nodes to allow the Pipeline to properly connect them.
from kedro.pipeline import Pipeline, node, pipeline
from nodes import (
create_model_input_table,
preprocess_companies,
preprocess_shuttles
)
def create_pipeline(**kwargs) -> Pipeline:
return pipeline(
[
node(
func=preprocess_companies,
inputs="companies",
outputs="preprocessed_companies",
name="preprocess_companies_node",
),
node(
func=preprocess_shuttles,
inputs="shuttles",
outputs="preprocessed_shuttles",
name="preprocess_shuttles_node",
),
node(
func=create_model_input_table,
inputs=[
"preprocessed_shuttles",
"preprocessed_companies"
],
outputs="model_input_table",
name="create_model_input_table_node",
),
]
)Benefits
Transform functions are reusable outside of Kedro projects since functions in
nodes.pydon’t depend on Kedro.A transform function can be reused in multiple Kedro nodes (assets) to ensure they use the same implementation.
Nodes can return multiple values specified by an
outputslist or dictionary
Limitations
When making changes to transform functions in
nodes.pyone needs to make sure the corresponding changes are made inpipeline.pyto prevent a broken pipeline.The pipeline definition becomes more complex and harder to maintain as you add nodes over time. This encourages adding logic to existing nodes over time to avoid having to redefine the pipeline, ultimately degrading modularity.
Readability can become challenging when having to jump between
nodes.pyandpipelines.pyto understand how transform functions relate to nodes (assets), remember their assignedoutputs, and search where they are used asinputs.
Hamilton
For Hamilton, each Python function defines an asset:
function name == asset name
function body == transform function
parameter names == dependencies name
All functions inside the file are considered part of the same pipeline. Function names are generally nouns because they are “assets that can be computed”.
# dataflow.py
import pandas as pd
# the `_` prefix means it isn't a node
def _is_true(x: pd.Series) -> pd.Series:
return x == "t"
# this defines the node `companies_preprocessed`
# with input `companies`
# and output `companies_preprocessed` (the name of the function)
def companies_preprocessed(companies: pd.DataFrame) -> pd.DataFrame:
"""Companies with added column `iata_approved`"""
companies["iata_approved"] = _is_true(companies["iata_approved"])
return companies
def shuttles_preprocessed(shuttles: pd.DataFrame) -> pd.DataFrame:
"""Shuttles with added columns `d_check_complete`
and `moon_clearance_complete`."""
shuttles["d_check_complete"] = _is_true(
shuttles["d_check_complete"]
)
shuttles["moon_clearance_complete"] = _is_true(
shuttles["moon_clearance_complete"]
)
return shuttles
def model_input_table(
shuttles_preprocessed: pd.DataFrame,
companies_preprocessed: pd.DataFrame,
) -> pd.DataFrame:
"""Table containing shuttles and companies data."""
shuttles_preprocessed = shuttles_preprocessed.drop("id", axis=1)
model_input_table = shuttles_preprocessed.merge(
companies_preprocessed, left_on="company_id", right_on="id"
)
model_input_table = model_input_table.dropna()
return model_input_tableBenefits
Transform functions can be reused outside Hamilton since
dataflow.pyhas no Hamilton dependenciesCoupling function, node, and pipeline definitions improves readability by presenting clearly how functions relate in a single file. It also facilitates maintenance since changes to functions are necessarily reflected in the nodes and pipeline.
Avoiding manual pipeline definition means building a pipeline with 10 or 1000 nodes has the same complexity. This scalability encourages writing smaller functions that will be easy to debug and maintain.
Limitations
Migrating to Hamilton means having to rename some functions and add type annotations to all of them to create a valid pipeline definition. This can be daunting at first, but is required to power many Hamilton features.
To output multiple values from a node or have multiple nodes share an implementation, you need to use Hamilton function modifiers. They allow for expressive pipeline definition but require importing Hamilton inside
dataflow.pythus introducing a dependency. You can still use these functions regularly outside Hamilton though.
Graphical User Interface (GUI)
Kedro

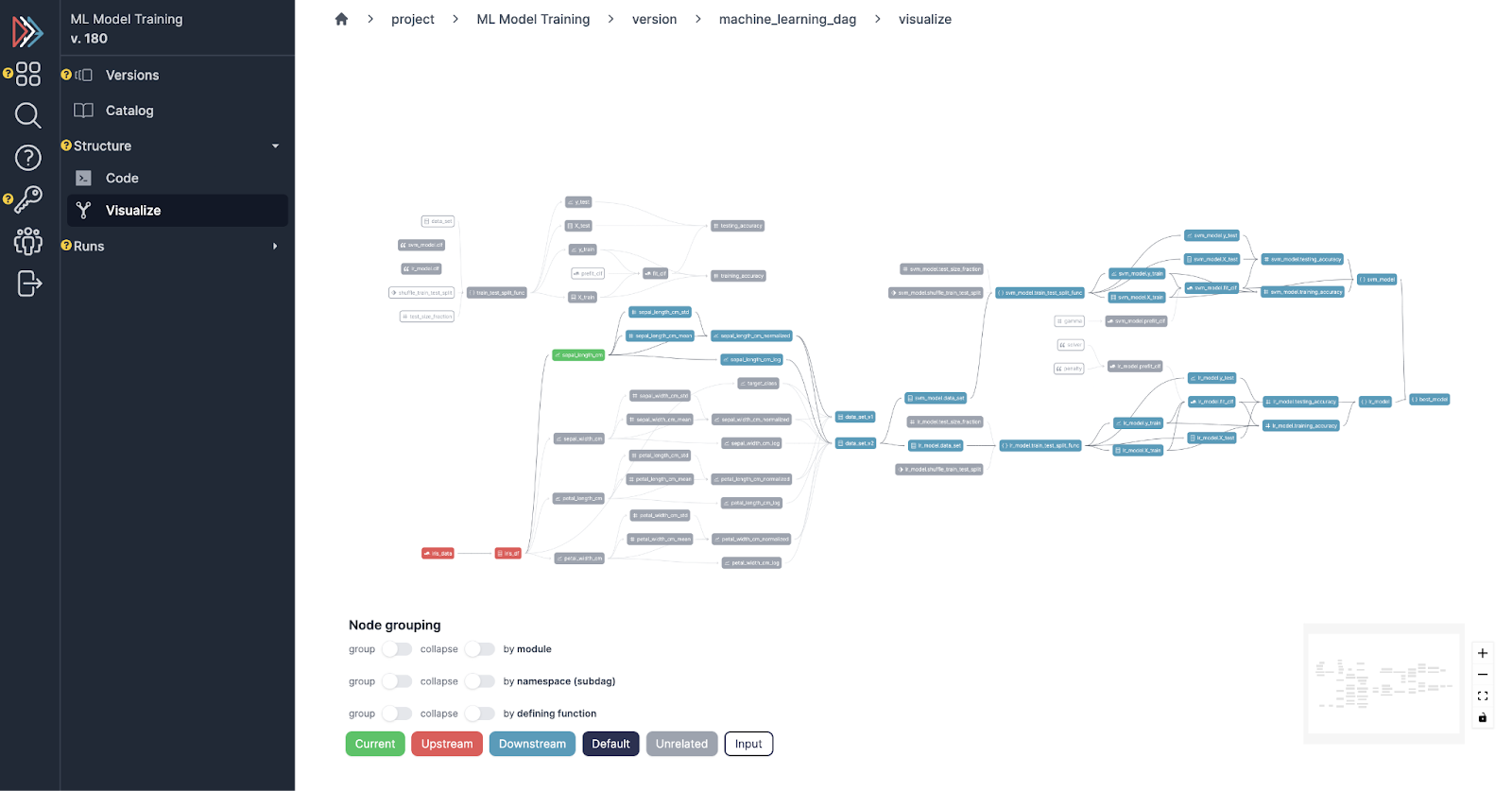
Kedro pairs with Kedro Viz a lightweight application to visualize your pipeline (video). It allows you to view its structure, but also the code of the transform functions, the dataset definitions, and the pipeline parameters. Its standardized format allows you to share and export visualizations with colleagues without hassle.
It can also connect to your datasets to provide previews of data tables or view stored figures (matplotlib, plotly). If you adopt the experiment tracking plugin, you can view stored artifacts and basic metadata of your runs.
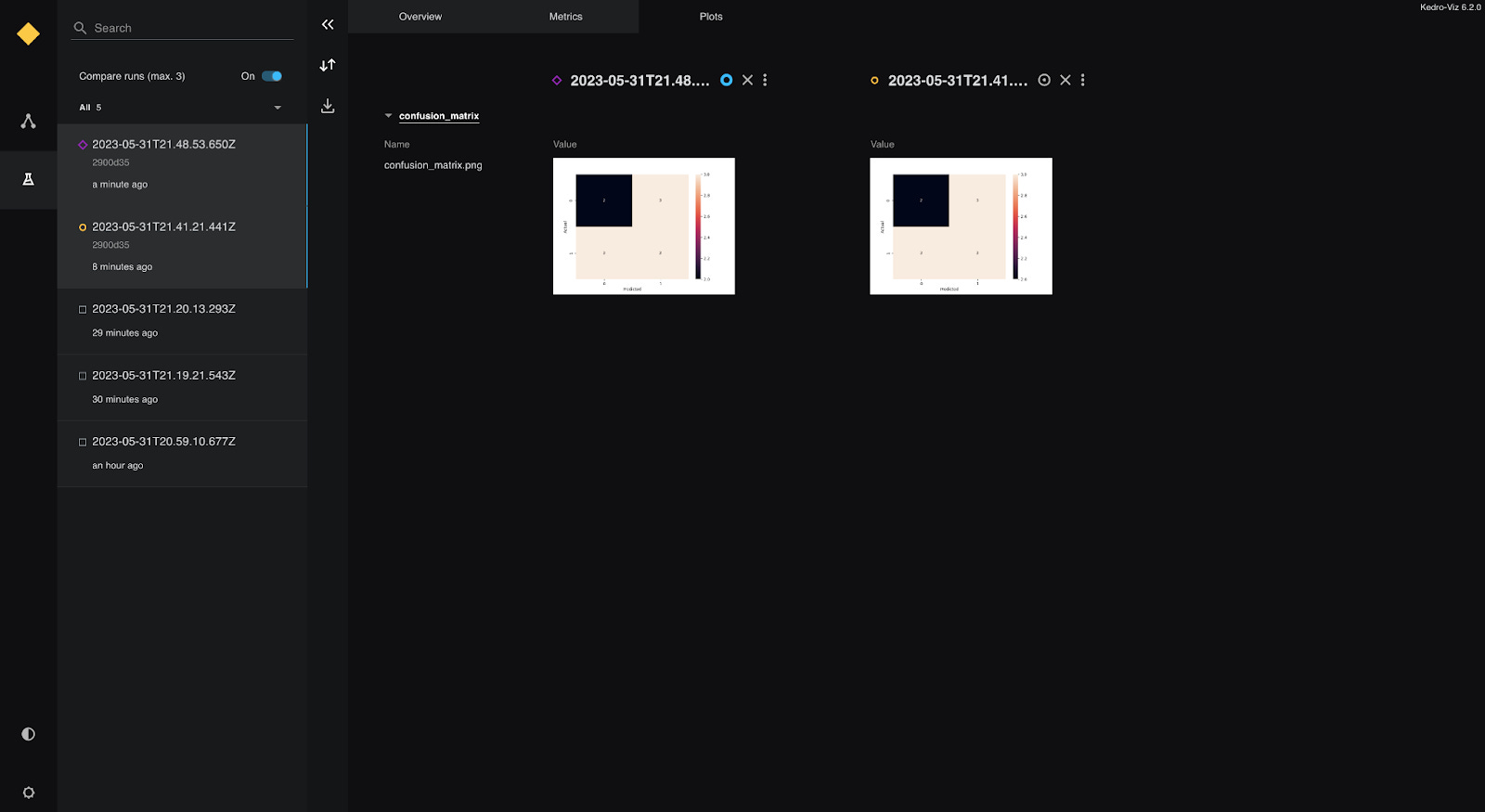
Hamilton
Hamilton offers Hamilton UI (video), a hosted or self-hosted application with versioning, lineage, experiment tracking, execution observability, and metadata catalog features. It effectively captures information about all “assets” produced by your pipelines. In addition to interactively viewing your pipeline, you gain:
Node and pipeline-level code versioning (much more reliable than a git SHA)
Execution monitoring to know what runs and when, and catch failures
Compare runs and see how code, configuration, or inputs might have changed
Data viewer with automatic profiling for dataframe and other datatypes


A Hamilton — Kedro bridge
Hamilton and Kedro share concepts of nodes and pipelines but provide different developer experiences. For example, you could benefit from Kedro’s clear and opinionated project structure while enjoying Hamilton’s unique notebook experience for pipeline definition. The new Hamilton Kedro plugin allows you to connect your Kedro Pipeline to the Hamilton UI for execution observability and metadata capture. It also enables Hamilton users to use a Kedro data catalog to load and save data!
Defining pipelines with the Hamilton notebook extension
The Hamilton notebook extension allows to define and execute a pipeline iteratively. In short, you define node functions in a cell starting with %%cell_to_module and executing the cell automatically builds the pipeline for you (tutorial). Since Hamilton uses regular Python functions, Kedro users can use it to author their nodes.py and later manually define their Kedro nodes and pipeline.
Your notebook would look like the following. The first cell loads the extension from the Hamilton library. The second cell creates the pipeline. The argument --display outputs a visualization and --write_to_file nodes.py will copy your code. No more copy-pasting! All you have to do now is create pipeline.py when you’re set.
# %% cell 1
# load the notebook extension
%load_ext hamilton.plugins.jupyter_magic
# %% cell 2
%%cell_to_module joke --display --write_to_file nodes.py
import pandas as pd
def joke_prompt() -> str:
return f"Knock, knock. Who's there? Cowsay"
def reply(joke_prompt: str) -> str:
_, _, right = joke_prompt.partition("? ")
return f"{right} who?"
def punchline(reply: str) -> str:
left, _, _ = reply.partition(" ")
return f"No, {left} MooOOooo"
As you add code and re-execute the cell, the visualization will be updated. Make sure to read the tutorial to find out about all of its features!
Kedro plugin
From Kedro Pipeline to Hamilton Driver
In Hamilton, the Driver object is responsible for creating and executing your pipeline. In 1 line of code, the function kedro_pipeline_to_driver() does exactly what you’d expect.
from hamilton.plugins import h_kedro
from kedro_project.pipelines import data_processing
kedro_pipeline = data_processing.create_pipeline()
hamilton_driver = h_kedro.kedro_pipeline_to_driver(kedro_pipeline)
hamilton_driver.display_all_functions()
It’s output gives you a regular Driver supporting all Hamilton features:
Generate pipeline visualizations for documentation
Monitor execution with the Hamilton UI
Scale your pipeline on Spark, Ray, Dask
and more!
You can even pass multiple Kedro Pipeline objects and Hamilton will resolve them into a single pipeline.
from hamilton.plugins import h_kedro
from kedro_project.pipelines import data_processing
from kedro_project.pipelines import model_training
processing_pipe = data_processing.create_pipeline()
training_pipe = model_training.create_pipeline()
hamilton_driver = h_kedro.kedro_pipeline_to_driver(
processing_pipe,
training_pipe,
)
You execute the pipeline by calling Driver.execute(), where you can pass data inputs. The next snippet loads CSV and Excel files for companies, reviews, and shuttles, and requests the node model_input_table:
import pandas as pd
from kedro_project.pipelines import data_processing
dr = h_kedro.kedro_pipeline_to_driver(data_processing.create_pipeline())
# loading stored data
inputs=dict(
companies=pd.read_csv("../kedro-code/data/01_raw/companies.csv"),
reviews=pd.read_csv("../kedro-code/data/01_raw/reviews.csv"),
shuttles=pd.read_excel("../kedro-code/data/01_raw/shuttles.xlsx"),
)
results = dr.execute(["model_input_table"], inputs=inputs)This greatly reduces the bar of trying Hamilton if you are curious to try it!
Use a Kedro DataCatalog with Hamilton
The concept of materialization in Hamilton closely resembles Dataset objects in Kedro. The from_ object defines DataLoader and to defines DataSaver objects, and they're collectively called materializers.
Here’s how you would use Hamilton materializers with the previous pipeline to load node companies and reviews from CSV and shuttles from Excel, and store the result of model_input_table to parquet.
from kedro_project.pipelines import data_processing
from hamilton.io.materialization import from_, to
dr = h_kedro.kedro_pipeline_to_driver(data_processing.create_pipeline())
# contains both DataSavers and DataLoaders
materializers = [
# `target` is the name of the Hamilton node receiving data
from_.csv(
target="companies",
path="../kedro-code/data/01_raw/companies.csv",
),
from_.csv(
target="reviews",
path="../kedro-code/data/01_raw/reviews.csv",
),
from_.excel(
target="shuttles",
path="../kedro-code/data/01_raw/shuttles.xlsx",
),
# `id` is the name of the generated "saver" node
to.parquet(
id="model_input_table__parquet",
dependencies=["model_input_table"],
path="../kedro-code/data/03_primary/model_input_table.pq",
)
]
# `.materialize()` will load data using `from_` objects and store results of `to` objects
dr.materialize(*materializers)Hamilton provides plenty of materializers for common formats and libraries (parquet, CSV, JSON, pickle, XGBoost, scikit-learn, dlt, etc.) However, if you already have a Kedro project with a DataCatalog defined (likely in YAML), you can use it with your Hamilton Driver through the from_.kedro() and to.kedro() materializers!
The next snippet uses the Kedro plugin to load an existing data catalog instead of using Hamilton materializers as above. First, you load the catalog from the Kedro project with bootstrap_project() and KedroSession. Then, you pass the data catalog and dataset name to the Hamilton materializers.
from kedro.framework.session import KedroSession
from kedro.framework.startup import bootstrap_project
from hamilton.io.materialization import from_, to
from kedro_project.pipelines import data_processing
dr = h_kedro.kedro_pipeline_to_driver(data_processing.create_pipeline())
project_path = "../kedro-code"
bootstrap_project(project_path)
with KedroSession.create(project_path) as session:
context = session.load_context()
catalog = context.catalog
# pass the `DataCatalog` to the `catalog` parameter
materializers = [
from_.kedro(
target="companies",
dataset_name="companies",
catalog=catalog,
),
from_.kedro(
target="shuttles",
dataset_name="shuttles",
catalog=catalog,
),
from_.kedro(
target="reviews",
dataset_name="reviews",
catalog=catalog,
),
to.kedro(
id="model_input_table__parquet",
dependencies=["model_input_table"],
dataset_name="model_input_table",
catalog=catalog,
),
]
dr.materialize(*materializers)Connect to the Hamilton UI
To connect to the Hamilton UI, you first need to install and start the application (instructions). Then, we need to create a HamiltonTracker, pass it to a Builder, and use this builder to convert the Kedro Pipeline to a Hamilton Driver. This is only a few lines of code.
from hamilton_sdk.adapters import HamiltonTracker
from hamilton import driver
from hamilton.plugins import h_kedro
from kedro_code.pipelines import data_processing, data_science
# create the HamiltonTracker; modify this as needed
tracker = HamiltonTracker(
project_id=3,
username="abc@my_domain.com",
dag_name="spaceflight",
)
# create the Builder
builder = driver.Builder().with_adapters(tracker)
dr = h_kedro.kedro_pipeline_to_driver(
data_processing.create_pipeline(),
data_science.create_pipeline(),
builder=builder # pass the Builder
)
# … define materializers
dr.materialize(*materializers)See the Kedro plugin tutorial for details.
In short
Writing data science code is particularly challenging because of its iterative nature and changing requirements. Thinking in terms of “asset layer” and distinguishing it from “orchestration” helps build a modular codebase. Whether it’s Hamilton or Kedro, adopting a tool to help structure your data science projects and greatly improve collaboration.
Kedro adopts a more opinionated and structured approach to projects and provides modularity by decoupling everything (data, transforms, nodes, pipelines, configurations, parameters).
Hamilton aims to give you all the flexibility regarding how you develop your project and tries to minimize the amount of manual pipeline wiring by collapsing pipeline development into two layers: definition and execution.
The good news is you don’t necessarily have to choose anymore! Our brand new Hamilton Kedro plugin allows you to run your Kedro Pipeline with Hamilton and connect to the Hamilton UI for your production needs.
We want to hear from you!
If you’re excited by any of this, or have strong opinions, drop by our Slack channel / leave some comments here! Some resources to help you get started:
📣 join our Hamilton community on Slack — need help with Hamilton? Ask here.
📝 leave us an issue if you find something
We recently launched Burr to create LLM agents and applications


