
Deep dive on Hamilton Decorators
My journey into the heart of one of Hamilton's most powerful abstractions...

Ho ho ho, tis the Christmas season; when everyone is decorating their Christmas trees, I am excited to talk about decorating Python functions (leave me a present under my abstract syntax tree, please…).
Introduction
Data-driven decision-making is a useful addition to most businesses. However, a common obstacle to adoption is the slow development-to-production lifecycle; while the initial building stage often involves more effort, the ongoing adjustment of dataflows to new demands should not require a full rewrite. Hamilton creates expressive dataflows to keep data pipeline lifecycles short by improving code readability and maintenance ease.
An important challenge in designing Hamilton was to address the trade-off between asset visibility and function cluttering, which makes code unmaintainable and unreadable. We represent the data pipeline as nodes in a Directed Acyclic Graph (DAG) and designed an internal decorator lifecycle framework to perform DAG-level manipulation. Nodes provide the necessary interface layer abstracting away from Python functions and, in conjunction with the decorator lifecycle, reducing code verbosity.
In this post, we talk about a few things:
How Hamilton, can improve your dataflow building capabilities and increase team productivity.
How Hamilton naturally represents the trade-off between explicitness and verbosity.
How Hamilton uses decorators to overcome that trade-off and make everyone more productive.
How Hamilton implements the fine-grained details of the architecture and decorator lifecycle.
If you just want to get a sense of why you want to use Hamilton, read (1) and (2). If you want to understand some of its more advanced features, read (3). If you want to dig into the architecture of those and really want to nerd out (like I do), read (4).
The Power of Explicitness
Working with data is messy; you never know what comes out or which direction you are meant to go. This entails a lot of experimentation, visualization, and hypothesis testing before you arrive at useful business insights. If you need to do this once a year, it may be acceptable to rewrite a previous analysis. Imagine now, that you need to redo the process every day, or better yet, every hour. God forbid, your colleague asks you to share your Jupyter notebook with them.
It would be good to keep track of how things change so that you can retrace your steps and, more importantly, your colleagues know what is happening / can work on the same data pipeline or re-use parts for their needs. This is where some battle-tested principles from software engineering come in handy, such as version control and breaking things apart into single functionality modules.
We can achieve this by making data transformations explicit and modular. This allows us:
to group them conceptually together, for example creating a feature platform
finding a good balance between building fast vs. to last, for example, having enterprise grade data pipelines
incorporating flexibility for future requirements, for example by decoupling the different pipeline stages
The aim is to turn a messy Jupyter notebook used for data analysis into a structured data pipeline (organized in Python modules). This naturally leads to better code readability and to the codebase being better maintained. Hamilton is an opinionated but lightweight framework that enables exactly that.
What is Hamilton?
Hamilton is a standardized way of building dataflows, a.k.a. “pipelines”, in Python. The core concepts are simple – you write each data transformation step as a single Python function with the following rules:
The name of the function corresponds to the output variable it computes.
The parameter names (and types) correspond to inputs. These can be either passed-in parameters or names of other upstream functions.
This approach allows you to represent assets in ways that correspond closely to code, naturally self-documenting, and portable across infrastructure.

After writing your functions, you call a driver to execute them – in most cases this is a simple import/run (specifying the assets you want computed and letting the framework do the rest), but it provides options to customize execution:

Visit tryhamilton.dev for a quick interactive introduction in the browser.
Explicitness/Verbosity Trade-Off
Hamilton's main (initial) selling point is explicitness. For every asset you have a corresponding function -- modifying that asset is an O(1) operation (a simple lookup), which can help iteration/debugging speed. On the other hand, this represents an increase in the verbosity of your code. To demonstrate:
A common use case would be to pull some dates from a database and calculate the date ranges. For simplicity, let us only consider three dates leading to three date ranges that we need to input into a series forecast, and, depending on the region, the date format changes. Here is the code snippet that only uses plain Python functions and Hamilton to build our DAG.


Keeping things explicit lets us have an overview of the different assets used in that data flow. However, the increase in verbosity can actually harm code readability and maintenance.
A simple solution to decrease verbosity would be to move the database calls to “helper functions” (using an underscore prefix in the Python function tells Hamilton to ignore it in the DAG creation process). We can then create a node that takes as input the region, fetches data from the database, and converts it into datetime objects. With this, we are already able to decrease the verbosity a bit.

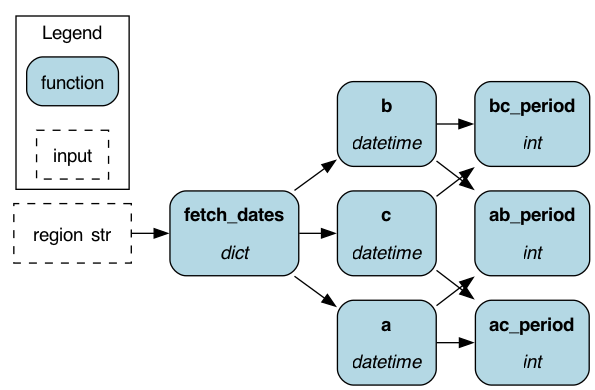
This improves the readability a lot! As a first pass at building your dataflow, this can be “good enough” and just using these basic functionalities can serve you for a long time.
Two points to note here; firstly, we reduced code verbosity at the expense of reducing explicitness since we hid the database calls. Secondly, we still have a lot of “empty functions” for the three dates each just returning a single value of a dictionary – imagine we have a dictionary with 20 entries!
It is time to ask: Can we refine the code further by moving core programming concepts such as loops and conditionals to the explicit DAG level?
Overcoming the Trade-Off: Using Decorators to Perform DAG Operations
We are looking for a solution that remains explicit (easy to read/plain English/easy to debug), but it is also much easier to develop/iterate on. It should both cut down on verbosity and allow for abstractions.
Hamilton does this with Python decorators. We are aware that decorators are an advanced concept in Python, but at the same time, we believe we made using them quite simple and provide lots of documentation.
In case you are not familiar with decorators in Python, they are functions that take as an argument an existing function, modify it in some way, and output a new function. See: https://realpython.com/primer-on-python-decorators/ for a detailed explanation. Hamilton uses decorators to attach instructions on how the local subgraph arising from the decorated function should be modified and has its own compiler that uses this data in the DAG creation process (see (4) for a more detailed explanation).
Let’s continue iterating on the same example and refactor the “empty functions” using @extract_fields. This directly corresponds to having a loop on the DAG level (for other concepts such as if/else conditionals and re-using nodes, check out the BONUS section at the end where we use multiple decorators at the same time). We get the following code:


Great, with a single decorator we cut down on verbosity by eliminating three functions while maintaining the DAG structure. Several things happen in the background that we will dive into later, but for now, notice how adding a new date for example involves only adding an entry to the attached decorator that creates a node out of it.
Likewise, the module is less cluttered which makes it easier to understand. It also allows us to quickly add or remove assets based on our needs, which accelerates the development-to-production cycle. Lastly, with fewer functions, we have a smaller code area to cover and our testing process is simplified.
While Hamilton provides you with a powerful, high-level language to build dataflows, you don't have to (and probably shouldn't) jump straight into the deep end. Rather, you can start like above with plain Python and helper functions. Once you see the code getting verbose/messy, you can refactor by creating conditional branches or making the code DRY) by defining common data transformations and decorating the corresponding asset functions - Hamilton will do the rest and construct the correct DAG for you. If you are interested in what happens in the background, we will be digging into Hamilton’s decorator framework for the rest of this post -- buckle in! We're going to go very low-level.
The Nitty-Gritty Details
Before we look at decorators in detail, let us take a step back and understand Hamilton under the hood. In the background, Hamilton abstracts away from user-defined functions and associates them to an object class Nodes, which in turn connect based on names and types, forming a graph. Based on the requested outputs, Hamilton only selects necessary nodes connecting the two endpoints and runs the minimal DAG. This abstraction layer provides the necessary interface we need to use decorators for graph operations.
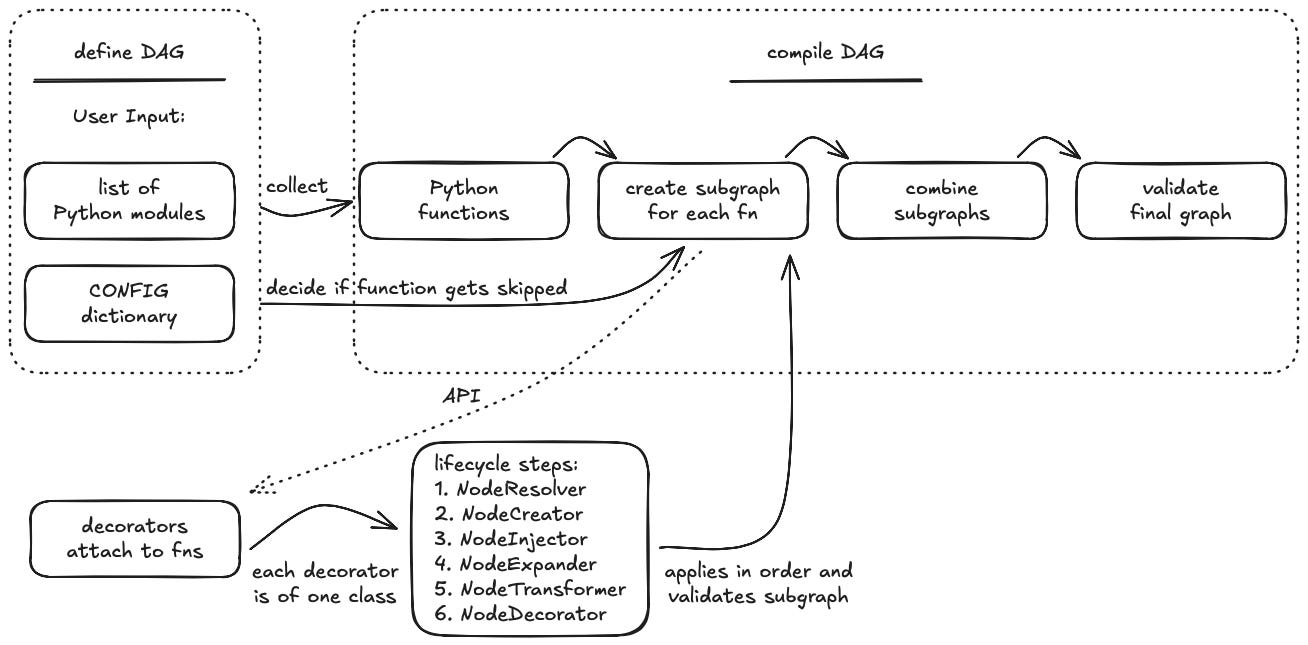
Let us first go through the high-level overview of how Hamilton creates a DAG (see Figure 1). We start with defining the DAG (user input):
Create a Python module and define functions inside.
Use Hamilton decorators on some of the functions.
Specify the Python module and optional config file for the Hamilton Driver that creates the DAG.
In the last step Hamilton does the following:
Collect all functions from the provided module. Skip functions that start with an underscore (i.e., helper functions).
Loop through the collected functions and for each function determine which decorators were used.
Go through the list of used decorator classes in order of priority and transform the subgraph of that function.
Return the subgraph (can be empty).
Connect all the subgraphs together into a DAG and validate it.
Great, now that we have the big picture let us explore how Hamilton creates subgraphs and, in particular, how the decorator framework is implemented. At the heart of the decorator lifecycle is the NodeTransformLifecycle abstract class. The class defines the high-level interface/functionality all child classes need as well as implements the call method of the decorator, which watermarks the decorated function with the specific decorator.1
This implementation, where we attach the decorator to the function and delay its execution, allows us to decouple the concrete user instance and subgraph transformations. In other words, the user first gets to define what subgraph transformation he wants to perform before the DAG even exists and delays the execution until we build that part of the DAG and the operations make sense to execute.
If there are no decorators attached to the function, a simple subgraph consisting of a single node corresponding to the underlying function gets created.
Otherwise, for a function with decorators, the decorators get executed in order of subgraph transformation relevance each taking in the output of the prior subgraph transformation:
NodeResolver: determine if the subgraph should be present.
NodeCreator: construct subgraph node(s) out of the underlying function.
NodeInjector: inject a subgraph before the current node.
NodeExpander: expand the current node into multiple new nodes.
NodeTransformer: transform the output of the current node.
NodeDecorator: add metadata to the current node.
This precedence order is critical for chaining together multiple subgraph transformations (stacking decorators) or informing the user that certain operations are incompatible with one another. For example, we can hardly expand the current node into many others if no current node exists.
In the following, we describe each subgraph transformation class and provide a use case. To view all supported subgraph transformations please see the decorators reference.
NodeResolver
The first decorator class resolves whether nodes should be created or not. It is the first decorator class called in the lifecycle since it determines the if/else conditionals for the whole subgraph arising from other decorators on that function.
A prime example is to decorate a function with @config.when, which creates a key-value pair that is used at DAG creation runtime to determine if we short-circuit the lifecycle and output an empty list (no nodes associated with this function).
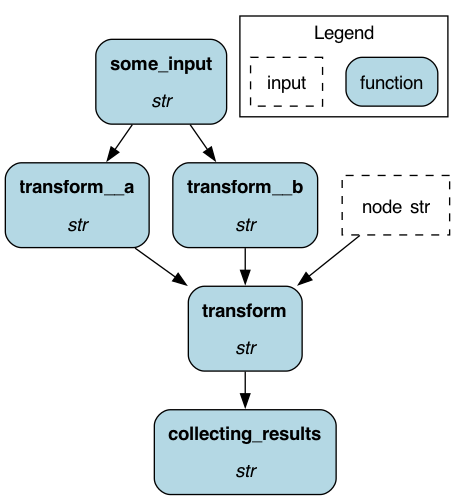
In this case, we have two different transforms: “transform__a” and “transform__b”. For “transform__a”, the NodeResolver gets called with the provided config and returns the node associated with it. Since Python does not allow two functions to have the same name (and we access all functions in a module by inspecting it) we differentiate the two functions by appending a double underscore namespace that will get stripped when resolved. For the “transform__b”, the NodeResolver returns an empty list (no node is created) since the condition is not fulfilled. We can select which transform (either a or b) gets executed by providing the correct config to the driver at runtime.
In case we do not use the decorator, we would need to define an additional node collecting “transform__a” and “transform__b” with the body performing an if/else statement based on the additional config input.

NodeCreator
The decorator class creates a subgraph consisting of at least one node out of the current function. It is the first decorator class creating a subgraph that all the consequent decorator classes apply transformations on. In case the function has no additional decorators, this class still gets called to create a node out of the function.
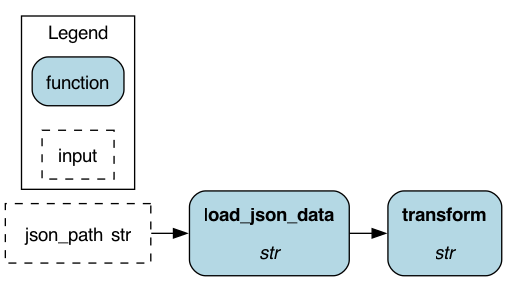
For example @dataloader allows us to specify that a certain function is meant to be an I/O interface.
Below we have a node loading JSON data and an additional node created for its metadata (materializer). In case we do not use the decorator, the additional node disappears.

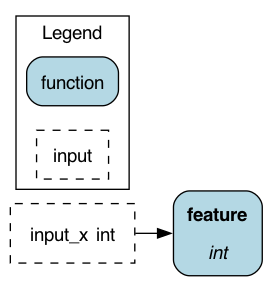
NodeInjector
The decorator class creates a subgraph and prepends it to the existing node via a specific function argument 1-to-1 map. This allows us to pre-process that argument before using it in the function. The preprocessing can be a complicated subDAG, like @with_columns, or a straightforward linear chain of nodes created by @pipe_input.
We take the argument “input_x” as an input argument for “_add_1”, which in turn is input into “_add_2”. We have injected a chain of 2 nodes that modify “input_x” and the result gets injected into “feature” in place of the original “input_x” argument.
In case we do not use the decorator, we could add the transformation as helper functions, but we lose lineage information or connect the nodes the conventional way forsaking the ability to reuse them.

NodeExpander
The decorator class creates a subgraph out of the existing nodes in a 1-to-many fashion. This operation allows us to avoid “empty functions” and can be thought of as a for-loop.
For example, when we have elements of a dictionary, it is cumbersome to manually create a function for each column. Instead, we can use [@extract_fields](https://hamilton.dagworks.io/en/latest/reference/decorators/extract_fields/) to create nodes out of the individual entries.
We created the three nodes “a”, “b”, and “c” and only need to specify their type to have them represented as nodes and avoid the necessity to define individual functions for each of the nodes.
In case we do not use the decorator, we are forced to manually define the three functions and do the extraction in each of them.


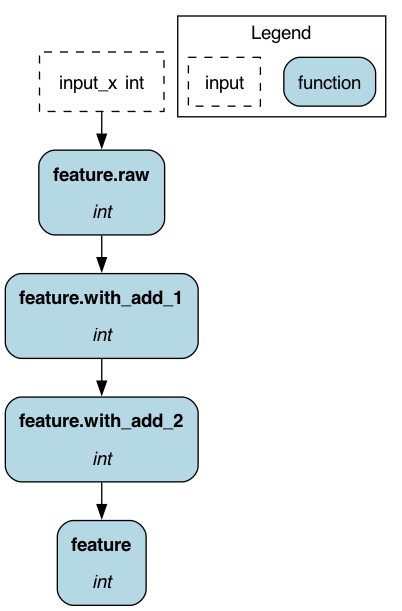
NodeTransformer
This decorator class also creates a subgraph and appends it to the existing nodes. It allows us to post-process a node output. For example, @pipe_output takes the output of the function and appends a linear chain of nodes to it, which is the dual behavior of @pipe_input.
We have the same example as with @pipe_input; in contrast, the execution order with @pipe_output is first executing “feature”, which in this case is an identity function, then we apply “_add_1” and afterward “_add_2”.
In case we do not use the decorator, we could similarly use helper functions inside the existing function or connect the nodes the conventional way forsaking the ability to reuse them.

NodeDecorator
The last decorator class in the lifecycle allows us to attach metadata to the subgraph. For example, we can use @tag to add tags to nodes providing code ownership within a team and can filter the nodes that have the specific tag “team=Platform”.

Bonus
Before we wrap up, we just want to have fun and share a more exotic use of decorators. Remember the initial mini-pipeline example of fetching dates and calculating periods between them?
We can STACK decorators to encapsulate all of the above ddmmyy functions as a single function? Practically, we can:
Set an if/else conditional for creating a node using @config.when.
Create a separate node for each of the dates by using @extract_fields.
Convert the string from the database into Python’s datetime format by post-processing all three “a”, “b”, and “c” nodes at once using @pipe_output.
Here is the code that does exactly that:

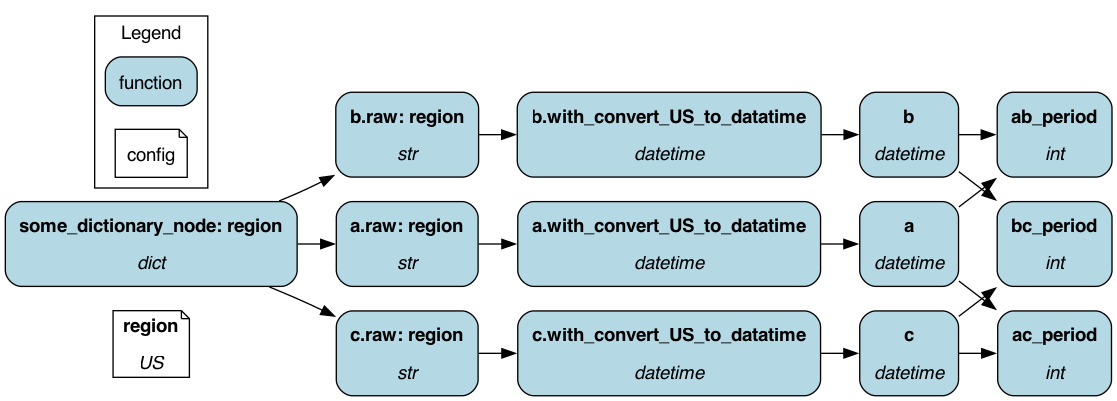
Selecting the correct region at DAG creation eliminates the unnecessary nodes leaving us with a single region DAG. We have achieved full explicitness with a minimal increase in verbosity!
Adding a new date format involves only adding a Python function for that asset and giving it the appropriate decorators. We managed to further localize the data transformations and shorten the development-to-production cycle. The functions are concise and not cluttered with if/else statements which makes the Python module clean and easy to understand. Lastly, by keeping truly essential functions that describe our dataflow and being able to re-use some of the transformations, we can test for dataflow coherence and do not need to unit test every single node.
Summary
We have shown how Hamilton utilizes decorators to cut down on code verbosity while keeping explicitness intact. Hamilton strikes a balance that lets you maintain a neat codebase that can be shared across users, while at the same time offering the ability to quickly iterate on dataflows. Although Hamilton’s approach requires basic familiarity with Python decorators, it abstracts away the complicated bits and lets you enjoy the full power in a straightforward application.
While the decorator lifecycle framework addresses an important trade-off, we have identified some limitations that warrant a revision of the initial design ideas.
For example, decorators only operate on the current function and keep things very local. While creating new nodes, the decorator does not get any information from other nodes in the DAG, which makes it harder to define a global operation. First attempts at something like that are made with the @mutate decorator.
Another emerging issue is the choice to create new nodes for actions arising from decorators. This can quickly lead to the original DAG being cluttered with additional nodes, which complicates the overview.
If you have not yet used Hamilton, hopefully this post shows that the bar to entry is set very low (you need to use Python in your data pipelines) and once you are comfortable with the basics, have fun exploring the rich and continuously expanding decorator ecosystem. If you are already a seasoned Hamilton user, give us a shout about your experience using decorators and we will incorporate your feedback in our next major overhaul of the decorator lifecycle framework!
The watermarking does the following: the user defines a decorator instance, where the call method attaches the same instance to the decorated function as an attribute. During the graph building procedure, we can then collect for each function all the decorators and call on their internal methods that predefine subgraph operations based on the user-provided input at instance creation.
 | A guest post by
|