
A command line tool to improve your development workflow
Introducing the Hamilton CLI Tool



We just released the hamilton command line tool, which can be installed via pip install sf-hamilton[cli]! It empowers users to interact with Hamilton code from the terminal, enabling continuous integration (CI) tasks such as validating dataflow definitions, updating visualizations, and getting dataflow diffs between versions.
In this post, we’ll detail the motivation for building a command line interface (CLI), its current features, example use cases, and its internal components. This post assumes familiarity with the basics of Hamilton.
Why build a CLI tool?
A core design aspect of Hamilton is the separation between the dataflow logic, which is defined using regular Python functions, and the Driver responsible for loading and executing the dataflow. This way, the dataflow can be developed and versioned without having to care about where the Driver runs it, which could be in any Python environment (script, notebook, orchestrated pipeline, server, web browser, etc.).
Despite its many benefits, this separation can introduce development friction because you need to access a Driver to answer questions about the dataflow. For instance, while editing the dataflow in a Python module, you need to rerun the “driver code” to validate your changes. To improve iterative development, we recently released an IPython / Jupyter magic to help define and execute dataflows in the same place using a notebook:

Over time, we’ve built multiple proof-of-concepts for developer utilities including:
Hamilton Dataflow Hub to load and share dataflows
Pre-commit hooks to ensure your dataflow visualizations used for documentation are up to date
VSCode extension for live updates of dataflow visualization and results on file edit
Language server (LSP) for IDE completion suggestions
Even though these tools served different purposes, we realized they all shared some logic to import modules from user-specified file paths, build a Hamilton Driver, and do something with it.
Building the CLI was an effort to centralize this logic to trim redundant code and ensure a set of well-tested functionalities. Not only will this improve our ability to ship new developer tools, this is also an opportunity to create yours and own your platform!
How does it work?
To install the CLI, use pip install sf-hamilton[cli]. This introduces only a few Python dependencies with a small footprint (typer, click). Now, run hamilton --help to access the documentation and learn about the available commands.
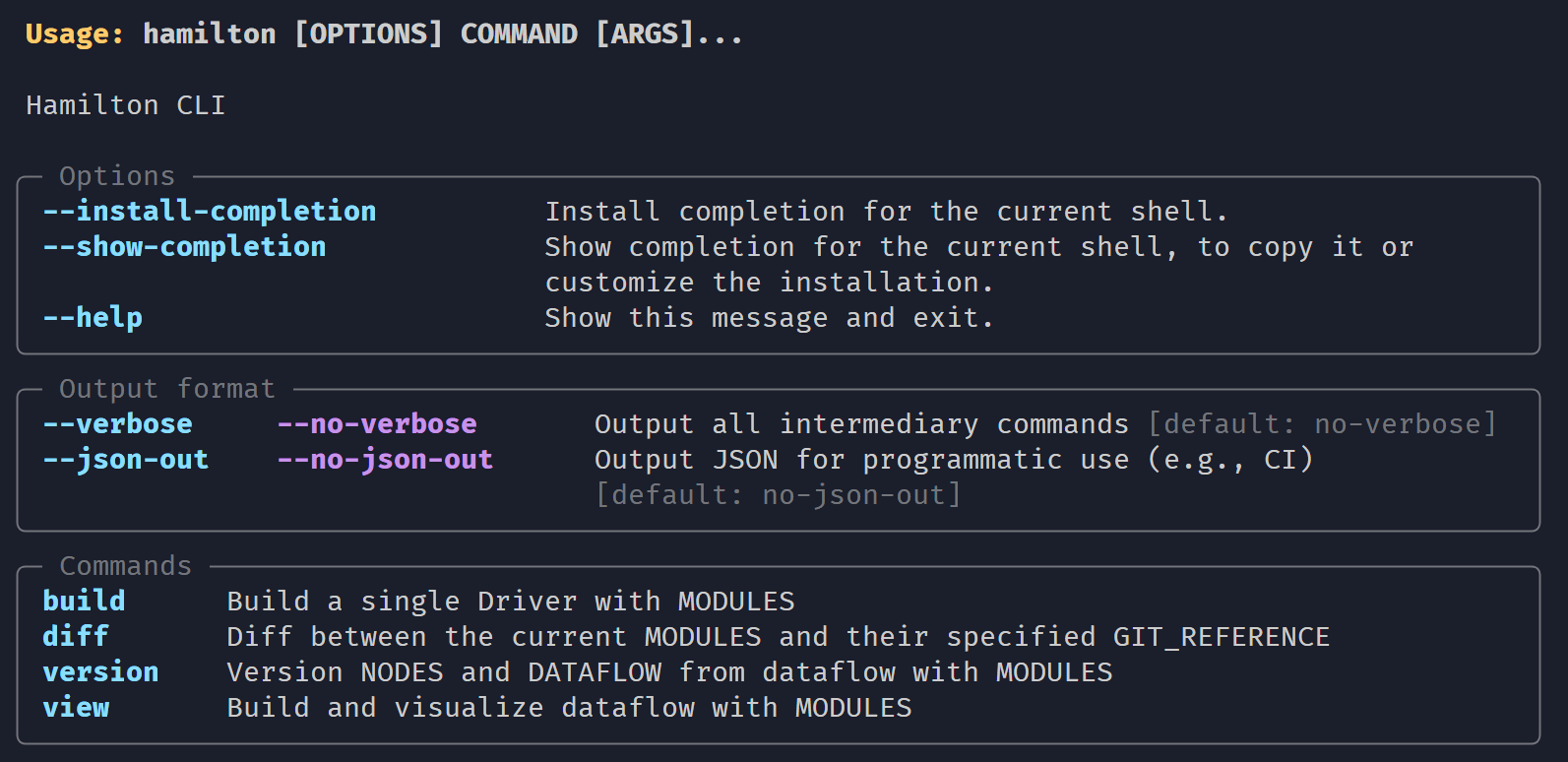
There are currently four commands and two output formats available. All commands accept as arguments a list of module file paths to build a Driver from + a set of options.
The current commands are:
build: builds a Driver to check if the dataflow definition is validview: output a visualization file of the dataflowversion: prints a hash for each Hamilton node based on its origin function. A unique hash for the dataflow is produced from the collection of node hashesdiff: compares a Driver to the Driver from another git reference (default: last commit) and outputs a diff of nodes that were added/deleted/edited. It can produce a custom diff visualization as well.
The output modes are:
verbose: provides a better execution trace by outputting all intermediary commandsjson-out: formats the CLI output as a JSON string on a single line, allowing you to pipe CLI results and use the JSON data with another programming language for instance
Learn more about the CLI by viewing our example on GitHub
For example, see the results of calling
hamilton view --help 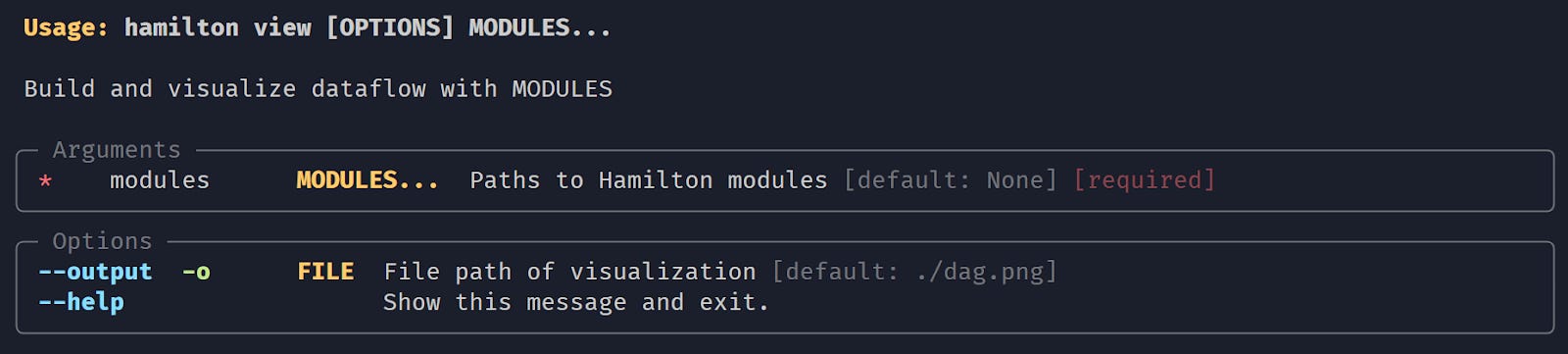
Here’s a response example from
hamilton diff --view MODULES{
"current_only": {"orders_per_distributor": "orders_per_distributor"},
"edit": {
"average_order_by_customer": "average_order_by_customer",
"customer_summary_table": "customer_summary_table",
},
"reference_only": {"orders_per_customer": "orders_per_customer"}
}The JSON returned here has three top-level keys: “current_only”, “reference_only”, and “edit”, and under each, we have a mapping {node name: function name} allowing you to quickly understand at a high level what the differences are in the dataflow.
The above command will also produce this custom visualization in the file ./diff.png, which visually represents the JSON response.

Use cases
With this small set of commands, we can improve our development workflows. Below we’ll showcase and sketch a few of them. Note that we plan to expand the CLI features over time (we’ll also take contributions!).
Pre-commit hooks
Pre-commit hooks are scripts/commands that help development by conducting checks on files before committing them to git (e.g., linting formatting, type checking). Hamilton has very few syntactic constraints, but the code should at least:
have every parameter and function return type annotated
have parameters and functions with matching names also have matching types
Instead of reimplementing these checks, we can simply attempt to build a Driver from the module, which will fail if the dataflow definition is invalid.
The pre-commit hook code would look something like this. We use subprocess to use a command from Python then we get the result’s stdout and parse it using JSON to inspect if build succeeded or failed. This could be written in your preferred scripting language (e.g., bash), but we used Python for convenience. In all cases, that you’ll need Python installed to run the hamilton CLI commands.
# precommit.py
import argparse
import json
import subprocess
from pathlib import Path
from typing import Optional, Sequence
PASS = 0
FAIL = 1
def main(argv: Optional[Sequence[str]] = None) -> int:
"""Builds a Driver to validate the module is syntactically valid."""
parser = argparse.ArgumentParser()
parser.add_argument("module_paths", nargs="+", help="Hamilton modules to validate.")
args = parser.parse_args(argv)
exit_code = PASS
for module_path in args.module_paths:
result = subprocess.run(
[“hamilton”, “--json-out”, “build”, module_path]
)
response = json.loads(result.stdout)
if response[“success”] == False:
print(SyntaxError(f“failed to build: {module_path}”))
exit_code |= 1
return exit_code
if __name__ == "__main__":
raise SystemExit(main())To learn more about pre-commit hooks, we point you to pre-commit.com. We'll soon publish a post detailing the full development and installation process of custom hooks. Subscribe to be notified!
File watcher for faster feedback loops
In a few lines of code, we can use a similar logic to the pre-commit example to generate visualizations. This time, we will use the watchdog Python library to create a background thread that will watch for file edits. Concretely, this will output a PNG of the dataflow of the file we’re working on, and continually update it as we make progress. This can help us to more quickly understand and grok the changes that we’re making; this is particularly useful for people who develop in an IDE.
# watcher.py
import sys
from watchdog.events import FileModifiedEvent
from watchdog.observers import Observer
from watchdog.tricks import ShellCommandTrick
if __name__ == "__main__":
cmd = sys.argv[1:]
event_handler = ShellCommandTrick(
shell_command=" ".join(cmd),
patterns=["*.py"],
)
observer = Observer()
observer.schedule(
event_handler,
path=".",
event_filter=[FileModifiedEvent],
)
observer.start()
print(f"Watching with {cmd}")
try:
while observer.is_alive():
observer.join(1)
finally:
observer.stop()
observer.join()Here are the steps to use it in your project:
Install the dependencies
pip install sf-hamilton[cli] watchdogCopy the above code in
watcher.pyCall
python watcher.py $HAMILTON_COMMAND. For example, this will rebuild the visualization from module_v1.pypython watcher.py hamilton view ./examples/cli/module_v1.pyWork on your files. Saving your file (or using autosave) will trigger the file watcher
See the CLI outputs in your terminal and the generated PNG at ./dag.png (default)
Continuous integration with GitHub actions
Continuous integration (CI) refers to the broad topic of automatically validating code changes and detecting integration issues, allowing for faster development. When working in a team and your codebase is growing, it’s essential to know how your work impacts others. While git is awesome, the scope of diffs is local to just code. In contrast, Hamilton’s dataflow construct is uniquely positioned to provide visibility on the downstream impacts of code changes.
For example, it wouldn’t be too difficult to build a GitHub action that outputs the response of hamilton diff (JSON and visualization) to a pull request whenever changes are made to a Hamilton module. This would better communicate how code changes map to business operations, and make it faster to review pull requests. Also, the diff could be automatically updated on further commits.
The basic recipe would be:
1. Write Hamilton code & submit a pull request (PR).
2. The PR kicks off a CI job, it uses `hamilton diff`.
3. The diff is posted back to the PR.
4. The diff is used to exercise lineage features that are then posted back to the PR as well. We’ll write more about this in the future, so stay tuned by subscribing! If you can’t wait, feel free to visit the official GitHub API reference to Create PR comment and Update PR comment to get started with your own implementation.
CLI architecture
For the curious, here are some details about the CLI’s architecture and internals. It is designed via a three-layer approach: CLI, Commands, and Logic.

On top is the CLI layer, which is user-facing. It is responsible for parsing user inputs, executing commands, and outputting responses. It only depends on the Commands layer. It also manages the state. For example, the hamilton diff command is a chain of build, version, and diff over the same set of passed modules. This makes it easy to reuse their inputs and outputs. Since the CLI layer outputs JSON strings, it is interoperable with languages other than Python!
In the middle is the Commands layer, which defines a relevant unit of action. They are meant to be reusable across developer utilities, without having to go through the CLI interface. However, it requires writing Python code and directly interacting with Hamilton and the Logical layer. It is not directly concerned with users.
The Logic layer is considered internal and consists of smaller united-tested chunks of code. These components are meant to be reusable across commands but offer no API guarantees. It becomes easy to add commands once you have a few well-tested building blocks.
Recap
To close out this post, the key points are:
The
hamiltonCLI is now available after installingpip install sf-hamilton[cli]You have access to commands to
build, view, version, anddiffHamilton dataflows.The CLI gives you the flexibility to build integrations with your workflow such as pre-commit hooks, file watchers, and continuous integration.
Stay tuned for more detailed tutorials on the pre-commit hooks and GitHub actions.
Lastly, we’re eager to receive feedback and suggestions for improvements and adding features! So please join slack, or start up a discussion.
Links
📣 join our community on Slack — we’re more than happy to help answer questions you might have or get you started.
⭐️ us on GitHub
📝 leave us an issue if you find something
Other Hamilton posts you might be interested in:


