
Playing Telephone with ChatGPT and DallE
An exploration of latent space




Note: This project found itself on the front page of HN a while ago. It got enough interesting comments/engagement that we decided to do a more in-depth write-up. Enjoy!
Fun with APIs
A few months ago I had just gained access to the multi-modal ChatGPT API, and promptly went down a rabbit hole.
I wanted to generate pretty pictures with DALL·E 3, but was too lazy to come up with prompts or ideas. So, rather than laboring over crafting prompts, what if I used ChatGPT to do it for me? And, to make up for a lack of creativity, what if I used a stochastic process?
I started playing around with an idea that was inspired by an old childhood pastime – the game of telephone. People gathered in a circle, whispering a secret word from one to another, until it traveled all the way around. To the surprise of seven-year-old me, the word would almost always change, often incomprehensibly so. The goal of this game was two-fold – not only did the observed change provide an abundance of amusement, but as children we were able to learn about how information travels through lossy mediums. This provides a profound view into multiple fundamental concepts, ranging from rumor spreading to lossy compression.
In the world of AI, a plethora of information is both lost and created through generative processes. The goal of image telephone is to capture and observe this, ideally using it to learn something about the way models “think” (in quotes, as thinking is an overly anthropomorphic description of what LLMs/LVMs do).
The rules are simple:
Start with an image
Ask ChatGPT for a {somewhat, very, excessively, obsessively} detailed caption for that image
Ask DALL·E 3 for a picture from that caption
GOTO (2)
I started playing around with this in the web UI, and quickly realized that, while the results were really fun, to scale up we needed automation and rigor. As DAGWorks Inc. builds and maintains Hamilton (a library for building self-documenting, modular, and shareable dataflows), and Burr (a library for building & debugging applications that carry state), I realized that I could both implement this and share best practices, all while helping get Hamilton & Burr into people’s hands.
In this post we’re going to:
Outline how we implemented this
Show how you can get started/customize your own workflows, and contribute them back to the community
Opine a bit on the data we generated through playing the telephone game
Share a few more ideas for those of you who have too much time on your hands or too many OpenAI credits…
If you don’t care much about the specifics (or don’t want to write/read code), and want to look at pretty pictures, we’ve packaged together the results in a streamlit app you can explore https://image-telephone.streamlit.app/.
You can also skip down to “Thinking Deeper” if you’re not interested in the technical design, and just want pretty to see more pretty pictures (no judgement!).
Structuring our workflows
We’re going to break our code into two workflows:
Generate a caption for an image
Generate an image for a caption
These will both be simple – they’ll do some prompt/image manipulation, reach out to the corresponding OpenAI APIs, and return the results.
As we want these to be easy to read/track, we’ll be writing them using Hamilton – a lightweight layer over python functions for building and maintaining dataflows. Hamilton allows you to express computation as a directed acyclic graph (DAG) of python functions that specify their dependencies. Each function corresponds to an output variable, and the parameter names correspond to upstream dependencies (other functions or inputs). You use a “driver” to run the code – it ensures that just the nodes you need (and those upstream) are executed given the output variables you request.

While we’ll be using Hamilton to express individual dataflows, we need to tie them together so we can run them in a loop. To do that, we’ll be using Burr. If you’re familiar with LangChain tooling, you can think of the Hamilton DAGs as chains, and the Burr code encapsulating the “agent” like behavior that is our telephone game.
Let’s start by digging into the dataflows themselves:
Image -> Caption
The code for this is straightforward, but we added a few requirements to make post-hoc analysis easier. The high-level goals are:
Control how descriptive ChatGPT captions the image
Use the multi-modal API to generate a caption
Compute and store embeddings of the caption for later analysis (you’ll see why in a bit)
Load images from and save them to a variety of sources
If you look at the DAG that Hamilton generates, you can see a few things – we do a bit of prompt manipulation, process the image URL to be friendly to the OpenAI API, call out to get embeddings from the generated caption, and join it all together in a simple metadata dict.
The DAG has a variety of inputs with optional parameters – the only required ones are the max_tokens, the model, the embeddings model, and the image URL.

You can find the code here.
Caption -> Image
The code for this is far simpler – all we have to do is:
Create some prompt for image generation (“generate an image based on this prompt”)
Use DALL·E 3 to generate the image
Save the results
The DAG echoes the additional simplicity – all you need to do is pass the image prompt (if you look at the code you’ll see the others have defaults).
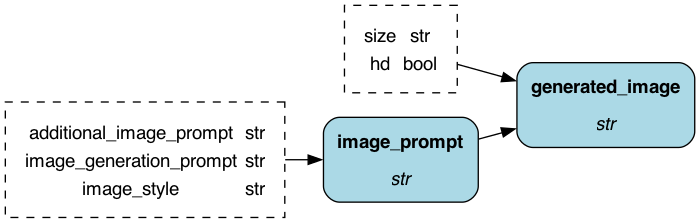
You can find the code here.
Tying it together
Finally, we want to run this all in a loop. This is where we use Burr. Burr is a Python micro-framework for easily expressing and debugging applications where application state drives what should happen next. Burr was built to complement Hamilton precisely to easily enable applications such as this telephone application.
To use Burr we just need to define a few functions that constitute the actions we want to take, and then how they are linked together and when to terminate.
Actions:
(1) Caption: Caption the image
(2) Analyze: Generate analysis of the caption
(3) Generate: Generate a new image based on the caption generated
(4) Terminal: Final action we go to to end things.
Edges:
Caption → Analysis
Analyze → Terminal: if max number of iterations reached.
Analyze → Generate
Generate → Caption
Each of the “Caption”, “Analyze”, ”Generate” actions will use our Hamilton DAGs. Note: we could generate the caption analysis during the Caption action, but split it out for visibility. For the Analyze action we’ll use Hamilton’s overrides functionality to run different portions of the DAG to enable this. Hamilton allows you to only compute the things that you want, and then easily override portions of the DAG with prior computed values.
We then define the Burr application using these actions, specifying how we transition between them, and when we want to terminate. For the actual application we need to save the data to S3 and there are several avenues to do so (via materializers in Hamilton, in a Burr action, via Burr hooks, or outside the application) but we omit discussion of that in this post for brevity.
Here’s the outline of the Burr actions & application that will run locally, or within a notebook (open this one or this one for a working example):
| """ | |
| This module demonstrates a telephone application | |
| using Burr that: | |
| - captions an image | |
| - creates caption embeddings (for analysis) | |
| - creates a new image based on the created caption | |
| """ | |
| import os | |
| import uuid | |
| from hamilton import dataflows, driver | |
| import requests | |
| from burr.core import Action, ApplicationBuilder, State, default, expr | |
| from burr.core.action import action | |
| from burr.lifecycle import PostRunStepHook | |
| # import hamilton modules | |
| caption_images = dataflows.import_module("caption_images", "elijahbenizzy") | |
| generate_images = dataflows.import_module("generate_images", "elijahbenizzy") | |
| @action( | |
| reads=["current_image_location"], | |
| writes=["current_image_caption", "image_location_history"], | |
| ) | |
| def image_caption(state: State, caption_image_driver: driver.Driver) -> tuple[dict, State]: | |
| """Action to caption an image.""" | |
| current_image = state["current_image_location"] | |
| result = caption_image_driver.execute( | |
| ["generated_caption"], inputs={"image_url": current_image} | |
| ) | |
| updates = { | |
| "current_image_caption": result["generated_caption"], | |
| } | |
| # could save to S3 here. | |
| return result, state.update(**updates).append(image_location_history=current_image) | |
| @action( | |
| reads=["current_image_caption"], | |
| writes=["caption_analysis"], | |
| ) | |
| def caption_embeddings(state: State, caption_image_driver: driver.Driver) -> tuple[dict, State]: | |
| result = caption_image_driver.execute( | |
| ["metadata"], | |
| overrides={"generated_caption": state["current_image_caption"]} | |
| ) | |
| # could save to S3 here. | |
| return result, state.append(caption_analysis=result["metadata"]) | |
| @action( | |
| reads=["current_image_caption"], | |
| writes=["current_image_location", "image_caption_history"], | |
| ) | |
| def image_generation(state: State, generate_image_driver: driver.Driver) -> tuple[dict, State]: | |
| """Action to create an image.""" | |
| current_caption = state["current_image_caption"] | |
| result = generate_image_driver.execute( | |
| ["generated_image"], inputs={"image_generation_prompt": current_caption} | |
| ) | |
| updates = { | |
| "current_image_location": result["generated_image"], | |
| } | |
| # could save to S3 here. | |
| return result, state.update(**updates).append(image_caption_history=current_caption) | |
| @action( | |
| reads=["image_location_history", "image_caption_history", "caption_analysis"], | |
| writes=[] | |
| ) | |
| def terminal_step(state: State) -> tuple[dict, State]: | |
| result = {"image_location_history": state["image_location_history"], | |
| "image_caption_history": state["image_caption_history"], | |
| "caption_analysis": state["caption_analysis"]} | |
| # could save to S3 here. | |
| return result, state | |
| def build_application(starting_image: str = "statemachine.png", | |
| number_of_images_to_caption: int = 4): | |
| """This shows how one might define functions to be nodes.""" | |
| # instantiate hamilton drivers and then bind them to the actions. | |
| caption_image_driver = ( | |
| driver.Builder() | |
| .with_config({"include_embeddings": True}) | |
| .with_modules(caption_images) | |
| .build() | |
| ) | |
| generate_image_driver = ( | |
| driver.Builder() | |
| .with_config({}) | |
| .with_modules(generate_images) | |
| .build() | |
| ) | |
| app = ( | |
| ApplicationBuilder() | |
| .with_state( | |
| current_image_location=starting_image, | |
| current_image_caption="", | |
| image_location_history=[], | |
| image_caption_history=[], | |
| caption_analysis=[], | |
| ) | |
| .with_actions( | |
| caption=image_caption.bind(caption_image_driver=caption_image_driver), | |
| analysis=caption_embeddings.bind(caption_image_driver=caption_image_driver), | |
| generate=image_generation.bind(generate_image_driver=generate_image_driver), | |
| terminal=terminal_step, | |
| ) | |
| .with_transitions( | |
| ("caption", "analysis", default), | |
| ("analysis", "terminal", | |
| expr(f"len(image_caption_history) == {number_of_images_to_caption}")), | |
| ("analysis", "generate", default), | |
| ("generate", "caption", default), | |
| ) | |
| .with_entrypoint("caption") | |
| .with_tracker(project="image-telephone") | |
| .build() | |
| ) | |
| return app | |
| if __name__ == "__main__": | |
| app = build_application() | |
| app.visualize( | |
| output_file_path="statemachine", include_conditions=True, view=True, format="png" | |
| ) | |
| last_action, result, state = app.run(halt_after=["terminal"]) | |
| # save to S3 / download images etc. | |
| print(state) |

For full code we direct you to:
Hamilton repository with full code to replicate the streamlit application.
Burr repository for a simplified version of this game.
Sharing Code with the Hamilton Hub
The exciting thing about writing this code is that anyone can use it – not only is it open-source, but it also lives on the Hamilton hub, where it is documented and displayed, along with a variety of other user-contributed dataflows. You can see the two dataflows we’ve drawn above in the hub:
It is easy to get started with these – you can (as we’ve shown in our script above) download and run them without installing a new library.
| caption_images = dataflows.import_module("caption_images", "elijahbenizzy") | |
| generate_images = dataflows.import_module("generate_images", "elijahbenizzy") | |
| dr = driver.Driver({"include_embeddings" : True}, caption_images, generate_images) |
You can easily contribute your own as well – see the guidelines to get started!
Thinking Deeper
Now that we’ve shown you how to build and run these workflows yourself, it should be straightforward to get started. We ran quite a few iterations of this algorithm, and found some really interesting results…
If you want to go ahead and explore before reading our musings, you can play with the results here – I recommend cycling through that to get a sense before digging in.
A Method for Exploring
When we captioned the image, we fired off a secondary request to the OpenAI API to get embeddings for the generated caption, using the text-embeddings-ada-002 model. While this is suboptimal compared to gathering image embeddings, it was an easy way to gather some interesting data.
As embeddings are very high dimensional (1500 dimensions for OpenAI!), the data itself means nothing at first glance. Thus we use a tool called TSNE (t-distributed stochastic neighbor embedding) to project these onto 2 dimensions. There’s some complex math/tuning that goes into it, but you want to think of it as roughly distance-preserving – if two points in high-dimensional space are close to each other, they’ll likely be close together in low-dimensional space when TSNE is applied.
Using this allows us to plot the progression over time. Let’s take a look at what happens when we feed Salvador Dali’s timeless painting, The Persistence of Memory, through our algorithm:
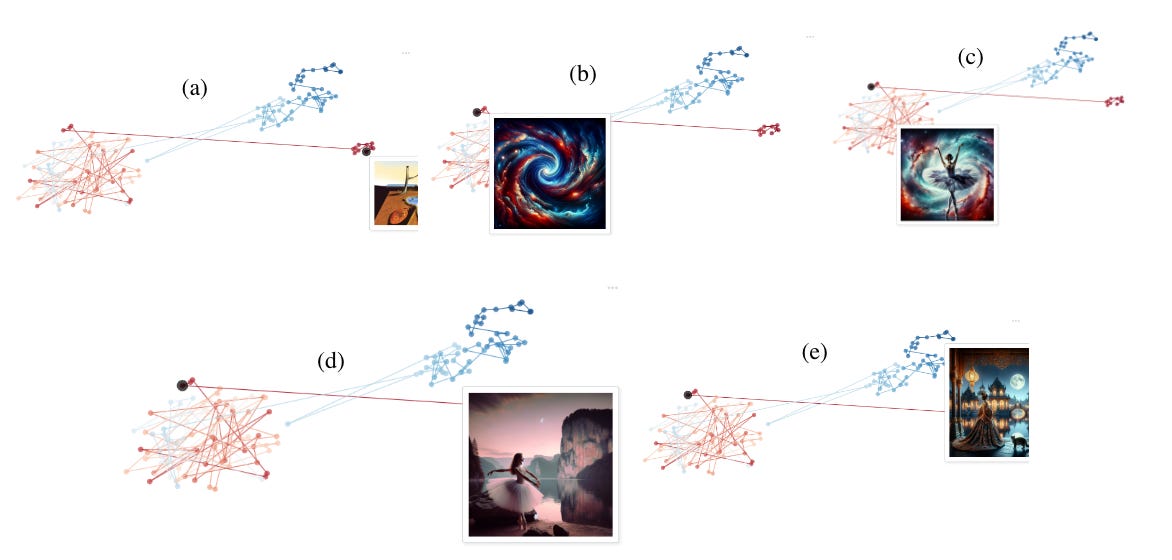
Note that this is far from a perfect science – just as embeddings are a projection from extremely high dimensional space to a simple array of vectors, TSNE is yet another dimensionality reduction, and almost all information is lost. That said, it does provide some interesting insights.

Some Head Scratchers
A few of the decisions ChatGPT made in captioning (and DALL·E 3 made in generating) were somewhat bizarre:



These are just a few of the examples of strange augmentations, misinterpretations, and removals – please look through and leave a comment if they interest you!
Local Minima
Interestingly, DALL·E 3 would get stuck in a few patterns – these would occasionally run across series as well…



While there was no one-size-fits-all explanation for these, similar patterns kept cropping up. Digging in more would require quite a bit of analysis, but we’ve theorized that:
DALL·E 3 gives preference to its training data and tends to sit around that (space-images, pagodas, etc…)
DALL·E 3 works with reduced information – in the embeddings space in which DallE operates, tea sets, gothic mansions, and galaxies are all closer to a basis vector than the more transient subjects
The way we prompted it (often, describe this image “obsessively”) was associated with a certain style that promoted dramatic flourishes. These are often unstable when projected between GPT-4 and DALL·E 3’s vector space, but the clusters + the description combine, in these cases, to form a more invertible projection, due to the topology of the space.
Symmetry, Reflections, Fractals, and Repetition
We found a few interesting meta-patterns present throughout the groups of images. Symmetry and reflections played a large role in multiple images:

To take symmetry multiple steps further, we have fractals (self-symmetric shapes). While it is not particularly novel to claim that fractals can describe most of the world around us, they do feel particularly well-suited to DALL·E 3’s artistic style

The emergence and evolution of a fractal from an amphibious cathedral (abridged and selected from a separate, offline series)
We also found that DALL·E 3 was very dramatic (in no small part due to our prompting approach) – it often just happily added *more* of anything interesting.

These basic compositional properties – symmetry, reflections, fractals, and repetition (among more) likely show up for a variety of reasons:
They are common in the training data
They are visually interesting and pleasing to the eye – the RLHF approach has suggested these to be stronger
They contain less information (due to symmetry), and are thus easier to draw
Without a deeper dive into DALL·E 3’s architecture, these are all just conjectures. And, by no means, an exhaustive set. If you have insights, predictions, or wish to generate more data, please reach out/post in the comments! Happy to discuss.
In Summation
We did a lot in this post – with the aim of having something for everyone.
For the builders among us:
We demonstrated how you can use Hamilton to build and adapt well-organized dataflows.
We demonstrated how you can build a simple application using Burr to orchestrate Hamilton DAGs.
We walked through the code, at a high level, that we used to caption and generate images.
We shared the Hamilton Hub – making it easier for you to get started and share your own dataflows.
For the philosophers among us:
We walked through a simple framework to analyze the transition of photographs through this process.
We highlighted and dug into a few of the stranger transitions we saw through the image telephone game.
We hypothesized about why DALL·E 3/ChatGPT made the decisions it did.
Perhaps the strangest and most profound learning, however, came from the laziness that prompted this dive into the rabbit hole in the first place. While crafting prompts is a lot of work, getting ChatGPT to do it for you is quite easy. When you allow a basic stochastic process (such as projecting between the two models) to guide the way, you’ll find that DALL·E 3 has preferences. Perhaps these preferences represent its best self – the images that it wants to draw, of which it can seamlessly create variation upon variation.
The exciting thing is that there are a lot more things you can do with this approach and this tooling. Using Hamilton to build, the Hamilton hub to share, the OpenAI APIs to compute, and a stochastic method to iterate, you can build a lot! Two apps we’ve thought of but have not yet built:
Make it more – start with an image of a “hard-working-cat” (generically, an Xing Y). Then, make it more Xing, and more Xing, and continue until the results look absurd. This was a popular meme on twitter recently. The way to really make this easy would be to ask ChatGPT for the next caption.
Craft a story – start with an image of your choice, and ask ChatGPT to caption it as panel N of a 20-panel cartoon, and to give the next panel. Ask DALL·E 3 to generate that, and continually pass back. You should find some interesting things
I’m sure you can come up with even more innovative ideas – the world is your oyster here.
We want to hear from you!
If you’re excited by any of this, or have strong opinions, drop by our Slack channel / leave some comments here! Some resources to help you get started:
📣 join our Hamilton community on Slack — need help with Hamilton? Ask here.
📣 join our Burr community on Discord — need help with Burr? Ask here.
⭐️ Hamilton on GitHub
⭐️ Burr on GitHub
📝 leave us an issue if you find something
📈 check out the DAGWorks platform and sign up for a free trial
📈 sign up for Burr Cloud.
Other Hamilton posts you might be interested in:
tryhamilton.dev – an interactive tutorial in your browser!