
Burr + BentoML: LLM agent deployment made easy
How to deploy a web page Q&A bot with Burr and BentoML


You build an LLM agent that works locally, but now you want to deploy it and make it available to users. You need to start thinking about:
Package code + dependencies into a container
Create API endpoints to interact with the agent
Create a client to interact with the endpoints reliably
Manage resources and batch requests for efficient processing
Monitor API usage
Track how your agent behave
Persist data produced by the agent for debugging and create training data
Add hooks and alerts for certain agent behavior
… and more
Burr is an open source framework to build LLM agents and all types of applications that make (or help make) decisions. BentoML is an open source library specialized for deploying LLM, ML, and AI services. Together, they provide the application and serving layers to solve the aforementioned problems.
Find the full example on GitHub
Application layer
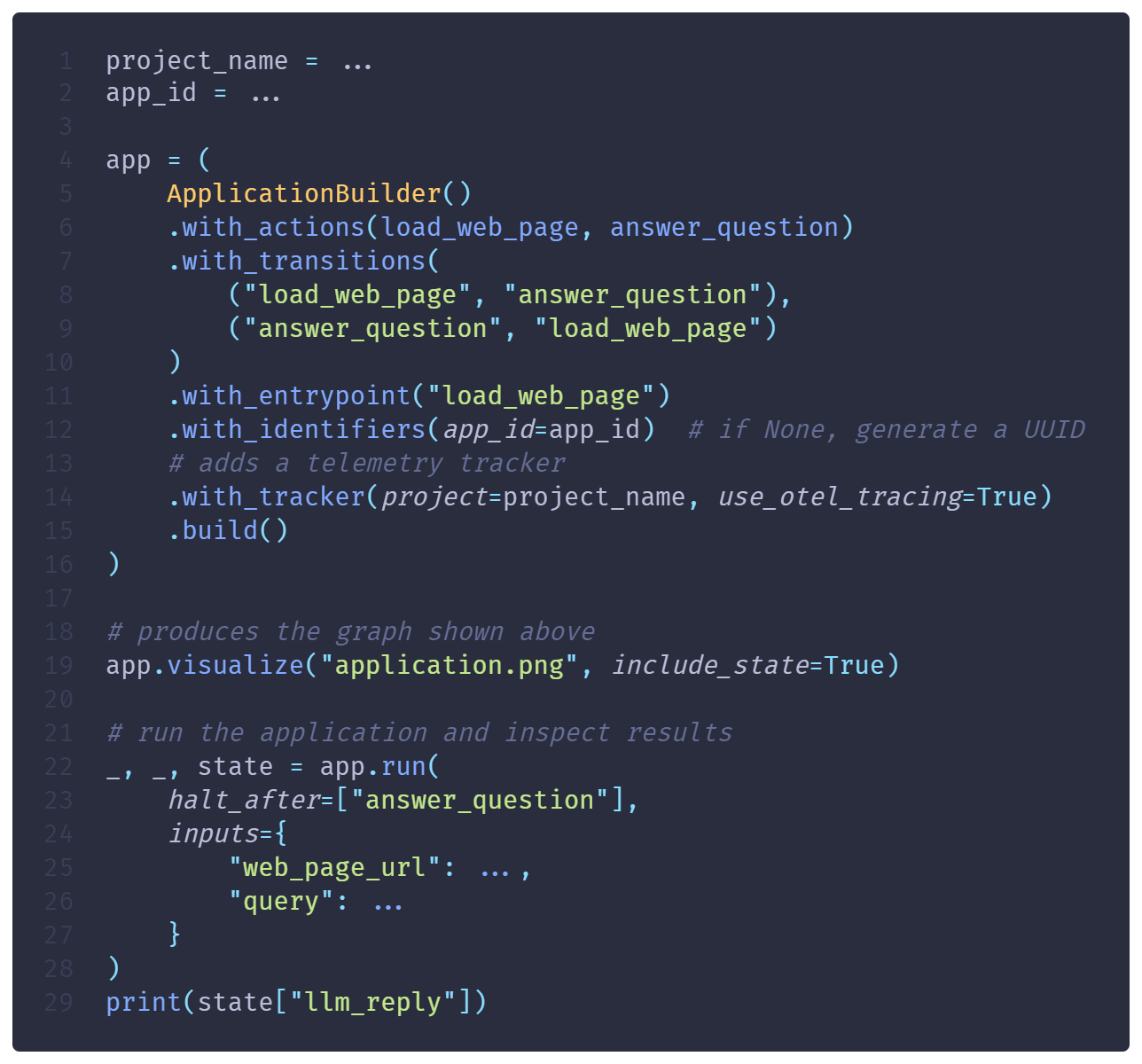
With Burr, you create an Application by defining all the possible actions and the transitions between them. The result is graph that’s easy to reason about, making your application easy to reason about and debug.

Actions can read from / write to a centralized state. By storing the state, you create checkpoints you can resume from. This enables “time-travel” debugging where you move backwards through states to see where things went wrong.
When building the Application, you can directly add the persistence, hooks, and telemetry necessary for production via the ApplicationBuilder. Then, you can run your application step, iterate over actions, or run until a halting condition, synchronously or asynchronously.
Burr comes with the open source Burr UI, which allows you to track live execution, inspect past runs, annotate data, create tests fixtures, and more.
Serving layer
BentoML allows you to define a service using a Python class. Its methods, sync or async, will automatically be converted to API endpoints. You can also specify the number of workers and the resources (e.g., CPU, RAM, GPU) required for your service. It also offers autoscaling based on service traffic.
AI, LLM, and ML inference is challenging because preprocessing inputs and making predictions is often an expensive operation. The main way to improve throughput and reduce latency is to batch requests. You could do this manually, but BentoML provides adaptive batching out of the box!


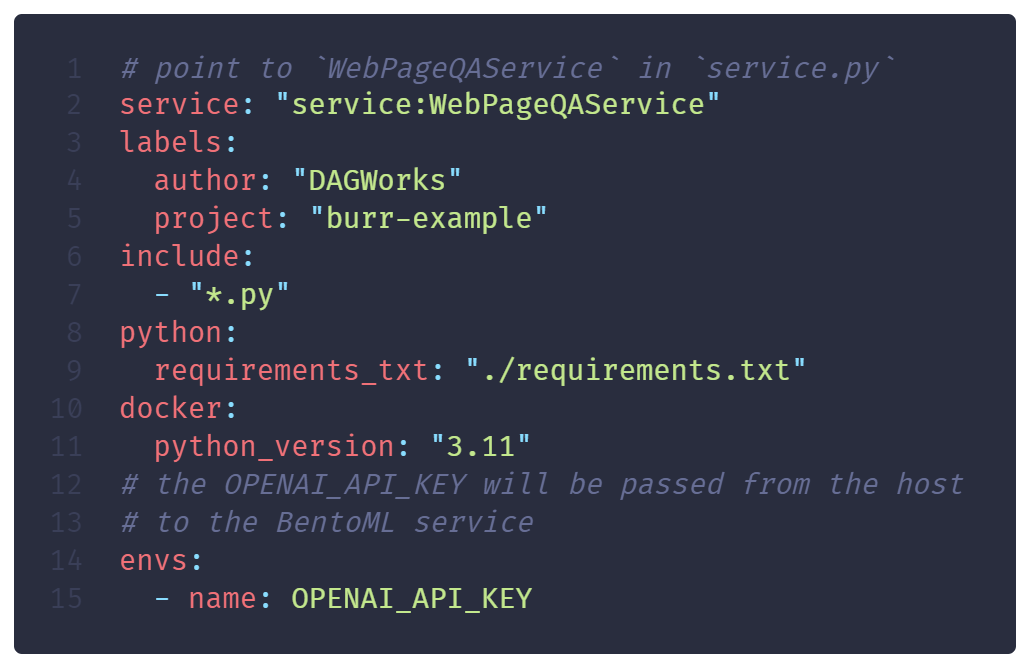
After defining your service class, you want to configure how to package your service. You need to specify the files to include, the Python requirements, and environment variables to read from the host. BentoML uses this configuration to efficiently build a Docker image, and it will automatically update it when required.
Now, run this command to launch your service:
bentoml serve .BentoML is also capable of automatically generating a client for your service. By creating a SyncHTTPClient object pointed to the service URL, you get a client object with methods that matches the service definition.

With the same deployment and client, you can query the API asynchronously by using a task queue. For instance, instead of calling .run(), you would submit a task via .run.submit() and wait for the task status to be completed and get the result.
Deployment options
Burr and BentoML are two open-source projects that you’re free to self-host. Alternatively, BentoCloud can host your deployment and provide an interface with permissions, secret management, logs and status, and service versioning. When deploying in the cloud, Burr will need a destination to persist state and send telemetry. Here’s the details for setting up Burr’s UI on AWS S3.
Conclusion
The path to deploying LLM agents is paved with engineering challenges. Good tools should minimize the number of engineering problems to solve and let you focus on the aspect unique to your business that generate value. With Burr for the application layer and BentoML for serving, many challenges are solved before you encounter them yourself.
We want to hear from you!
If you’re excited by any of this, or have strong opinions:
🍱 BentoML Slack (GitHub)
🤖 Burr Discord (GitHub)

