
The graduation problem: avoid frameworks getting in the way
Use the 2-layer approach to build a maintainable system


Ready-made solutions and large language model (LLM) frameworks can get you started quickly with GenAI, but two years after ChatGPT’s release, teams are feeling the limitations of these tools. The reality is that retrieval augmented generation (RAG) or LLM agents are broad approaches rather than a single thing.
From proof-of-concept to deployment and maintenance, your technical needs will evolve. To build a reliable product, you will inevitably need custom code and some frameworks may get in the way more than others.
This post will show how a RAG feature typically evolves using three versions of the same project. We will use the 2-layer approach to handle the growing complexity and ensure that we create a maintainable solution without ready-made components.
Follow along on GitHub or Google Colab
The 2-layer approach
The 2-layer approach separates the low-level implementation (layer 1) from the high-level application logic (layer 2). Layer 2 encodes “how the system should make decisions and behave” and Layer 1 processes the data to make these decisions possible.
Burr is a Python framework specifically focused on Layer 2. It structures an Application as a set of actions, transitions & conditions between actions, and state shared between actions. It comes with useful features for deployment such as state persistence, telemetry, annotations, and more. Then, Layer 1 is encapsulated in individual actions (for another example of these concepts in action see our Burr + Haystack post).
Version 1: a simple LLM pipeline
It may be counterintuitive, but you should start with the high-level logic and determine the intended behavior of your application. Skipping these initial questions usually leads to refactoring and slows down development.
Layer 2: Define the Application logic
In the next snippet, we outline the logic to ingest a blog post and ask questions over its content. Note that we haven’t implemented @actions yet, but we get the ability to build and view the graph.

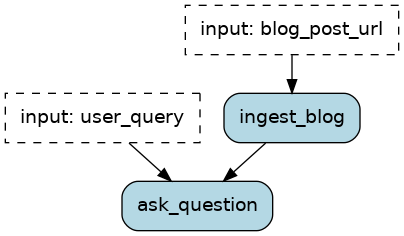
Layer 1: Implement individual @action
The previous outline sets “contracts” for each actions:
ingest_blogdownloads an HTML page, parses it into a plain text.ask_questionprompts an OpenAI LLM with the full blog in the prompt and the user query.
It allows us to build simple implementations for each to get a functional prototype. Notice that @action functions (Layer 1) can use any Python library and don’t hide implementation behind complex objects. This makes it easier to adapt to evolving product requirements.

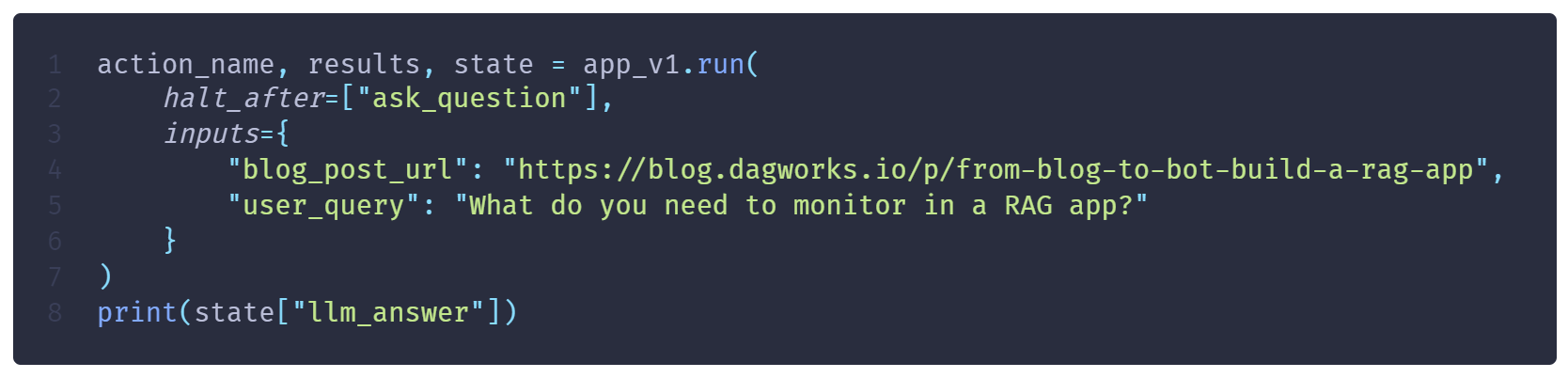
We can reuse the previous ApplicationBuilder, but we will pass the new _v1 functions instead

Here’s the code to launch your Burr application
Version 2: Let’s use RAG
While Version 1 simply ingested the blog and prompted the LLM, Version 2 will add RAG capabilities. We have to ask ourselves:
Are we making changes to layer 1 or 2?
In this case, we’re focusing on Layer 1. With Burr, we can keep the same “contracts” and simply upgrade the action implementation. As you make changes, you might decide to merge/split actions, modify state variables, etc. Then, you can revisit and update your application outline.
Layer 1: Adding RAG
In the next snippet, you'll notice:
we define a
TextDocumentmodel to create the schema of our LanceDB table. It specifies to embed thetextfield using the OpenAI model.because text chunks are stored on disk, we don't need to pass them via the
Applicationstate.

Layer 2: Tracking and observing your application
When developing AI systems, it’s essential to track how your application behave across versions. It’s not uncommon that new exciting techniques don’t fully deliver on promises and it’s important to assess if your earlier and simpler versions perform as well. This is a Layer 2 concern and should be decoupled from your Layer 1 implementation.
Burr makes tracking easy. Simply add a tracker to the ApplicationBuilder. This is compatible with OpenTelemetry! The next snippet will enabling tracking for our RAG application and gather telemetry events from OpenAI and LanceDB.

Now, running your application will emit events that you can see in the Burr UI

Burr UI has many other useful features:
view token usage
annotate state values and logged attributes
create test fixtures from application state
and more
Version 3: Keeping your code modular
You probably noticed that functions in Version 2 started to be lengthy and do several things. It’s a good occasion to refactor to smaller functions that will facilitate development, testing, and maintenance.
Layer 1: Modular actions
In the next snippets, we refactor actions using Hamilton, a lightweight library to structure data transformations as directed acyclic graphs (DAGs). Hamilton uses the function and parameter names to infer the dependencies between functions and the graph structure.
action: ingest_blog
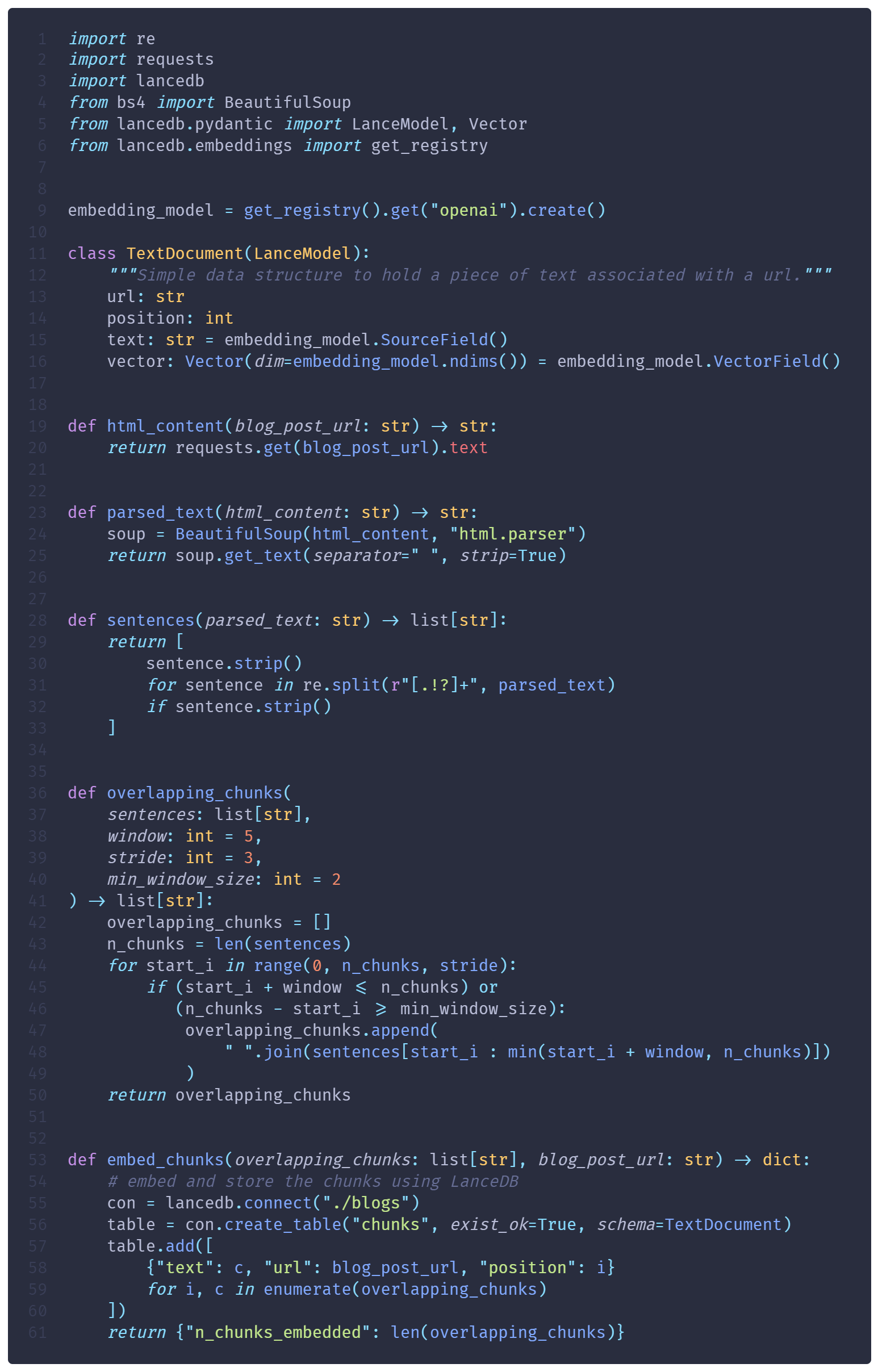

While this may seem trivial, these simple functions are easier to test, debug, and modify. It also allows us to develop and test actions outside of Burr. Hamilton has a great caching feature that can speed up development significantly when iterating over your application.
action: answer_question


We encourage considering prompt as code, which allows us to commit and version our prompt with the rest of our code. For instance, the function `system_prompt()` helps understand what information goes into the prompt and an additional docstring can add context to it.

Layer 2: Using Burr + Hamilton
Since Burr is not opinionated about the implementation of `@action` functions, you can simply call Hamilton from it. We add the `OpenTelemetryTracer` to the Hamilton `Driver` to get tracing in Burr UI.
You'll see that the Layer 2 becomes much lighter and only the high-level logic remains.

Find more simplifications in the full example notebook
The biggest benefit of Burr + Hamilton is the unbeatable observability you get. The Burr UI will show a granular breakdown of the operations.

Hamilton even has its dedicated Hamilton UI that tracks execution, catalogs data transformations, and provides in-depth introspection. We're looking to integrate the two further together!

Conclusion
We presented the 2-layer approach to building a RAG application, which separates high-level logic from the implementation of individual actions.
The key lesson is that you should adopt frameworks incrementally. A tool shouldn't lock you in and limit the evolution of your application. Adopting Burr from the start helps you develop in a principled way, and adding Hamilton as the complexity increases helps with maintainability and observability.
We want to hear from you!
If you’re excited by any of this, or have strong opinions
📣 Join our Discord
⭐️ us on GitHub

