
Async Dataflows in Hamilton
How to build well-structured, lightweight, and performant DAGs using Hamilton



Wren AI + Hamilton
At DAGWorks, we were recently blown away by Wren AI’s post on how they rewrote their service to leverage Hamilton, supporting 1500+ (!!!) concurrent users.
Wren AI is a text-to-SQL solution for data teams to get results and insights faster by asking business questions without writing SQL. It is open source, can run anywhere you like (on your own data, LLM APIs, and environments), and built to be easy to get started with and use.
We highly recommend reading their post — they use Hamilton along with Haystack, and include code, benchmarks, and more. The TL;DR is that they leverage Hamilton’s async integration to build a well-organized, highly traceable orchestration mechanism for LLM interaction.
Coincidentally, the same day that was released, we made a host of improvements to Hamilton, including:
Moving the driver from experimental to fully supported mode
Adding an async builder pattern to make graph construction easier
Adding support for lifecycle adapters
Adding support for the Hamilton tracker for UI integration
In this post we’ll be going over the why/how of async in python, talking about Hamilton and how to leverage the async integration + tracker, then give a brief overview/link out to Wren AI’s code.
Python Async
While asynchronous programming using coroutines has been around for quite a while, the modern async/await keywords were first introduced in 2007 (with F#)1, and adopted into Python in 20152. It is now present in a wide array of languages.
The concept of async in python is simple. Your program only ever runs on one central thread, which is managed by the “event loop”. Rather than blocking at a slow running task (say an HTTP request or file load), the event loop can hand control over to another task, enabling a long-running task to work in the background until it is ready to continue.
In python, you can specify non-blocking code with the async and await keywords. The async keyword declares a function as a “coroutine”, a special function that can pause its execution and yield control back to the event loop. The await keyword is used within these coroutines specify the point at which execution can be suspended execution and control should be handed back to the event loop. Note that await must be used within an async-declared function (you will get a syntax error otherwise).
In this case above, the program will:
await the result of dont_block_control_flow
which will first await complex_http_call
then await complex_system_call
then return to the caller
Between (2) and (3) and (3) and (4), the event loop is allowed to work on other aspects of the program. Thus there’s no while true/if done loop, no burning through compute waiting for something to be done, and no thread management. It just runs until it can’t anymore, then switches contexts.
This only makes sense for I/O bound programs, in which the majority of work does not happen inside the event loop. For those systems (data loading/saving, API calls, etc..) asynchronous implementations can significantly improve scalability. Why? If you have code in which the majority of the latency comes from external calls (E.G. to LLMs, querying a database, etc…), it will spend very little of its time coordinating those, and the vast majority of its time waiting on them. For instance, say it takes 10 microseconds to format an HTTP query (serialize JSON, etc…), and 100ms for that HTTP query to make a roundtrip call, that’s a factor of 10,000! Meaning that, if you don’t have to do anything while you’re waiting, you could (in theory) up your throughput by 10000x (assuming you’re not bottlenecked on network, memory, gamma rays, etc…).
To interact with async, you have a host of tooling available:
Asyncio in python — a standard library that contains utility functions
asyncio.gather — run and await multiple coroutines
asyncio.create_task — keep a reference to a task to avoid GC and ensure a background task gets run
asyncio.timeout — error when a function takes too long
A host of popular libraries — aiohttp, aiobotocore, fastAPI, etc… that provide useful features leveraging async
Async generators and context managers as well as more stdlib features
Jupyter notebook has builtin
async/await
Aside from being less helpful for true (CPU/GPU-bound) parallelism (which, hey, the GIL makes harder in python anyway), there are a few more trade-offs to be aware of:
Async and sync don’t mix well. You can call synchronous routines (standard functions) from within the event loop, but they will block. God help you if you want to run an async function inside a synchronous function (it is actually very hard to do right, if even possible, and will almost always break something upstream).
Async *can* mix with multithreading but its difficult, and rarely a good idea
Frameworks often lag behind their synchronous counterparts in terms of async capabilities (django, for instance, added async recently but it does not support all aspects of the framework — the ORM implementation is still lacking certain capabilities).
For these reasons, it is widely used in I/O bound web services, allowing them to scale up and save compute power.
Hamilton Async
Overview
Hamilton is a standardized way of building data pipelines in Python. The core concepts are simple – you write each data transformation step as a single Python function with the following rules:
The name of the function corresponds to the output variable it computes.
The parameter names (and types) correspond to inputs. These can be either passed-in parameters or names of other upstream functions.
This approach allows you to represent assets in ways that correspond closely to code, naturally self-documenting, and portable across infrastructure.
While Hamilton is widely used for offline contexts such as ML pipelines, RAG ingestion, etc… it is also often leveraged to structure the logic of prompt manipulation/API calling within a request body. Let’s take a look at a simple example of an application that tells us a joke.

This creates a directed acyclic graph (DAG) that looks like this — note topic is the input that the user/caller puts in, and joke_response is what they get out.

To run this, you use the AsyncDriver. This is a wrapper that takes in the module we defined above and executes just the desired output and the upstream dependencies. In this case, when queried for joke_response, it will execute joke_prompt, llm_client, joke_messages, then joke_response (or perhaps a slightly different, valid topologically-sorted order…), tracking the results in memory and feeding them to the functions that depend on them.
In this case, let’s ask it to make a joke about the federal reserve (Alexander Hamilton, after all, founded the federal reserve…):

Which gives us the classic:
Why don't people trust the Federal Reserve?
Because too much interest is never a good thing!Hamilton UI/Async
With a recent Hamilton release, we made a sizable set of upgrades to the async implementation, including moving it out of experimental mode, and adding integration with the lifecycle adapter framework, enabling full customization of DAG execution (run before/after nodes, before/after workflows, etc…).
See the release notes here.
Due to the upgrades, we were able to add integration with the Hamilton UI, enabling users to track any information they need about their asynchronous DAG executions. Adding tracking is simple, all you have to do is add the right adapter, and create a project in the UI.
To get started with the UI, you can run:
pip install "sf-hamilton[ui,sdk]"
hamilton uiThis will open up a browser at localhost:8241, which will prompt you for a username. Once you enter a username and create a project (remembering the ID), you’ll be able to add the tracker back to the code above.

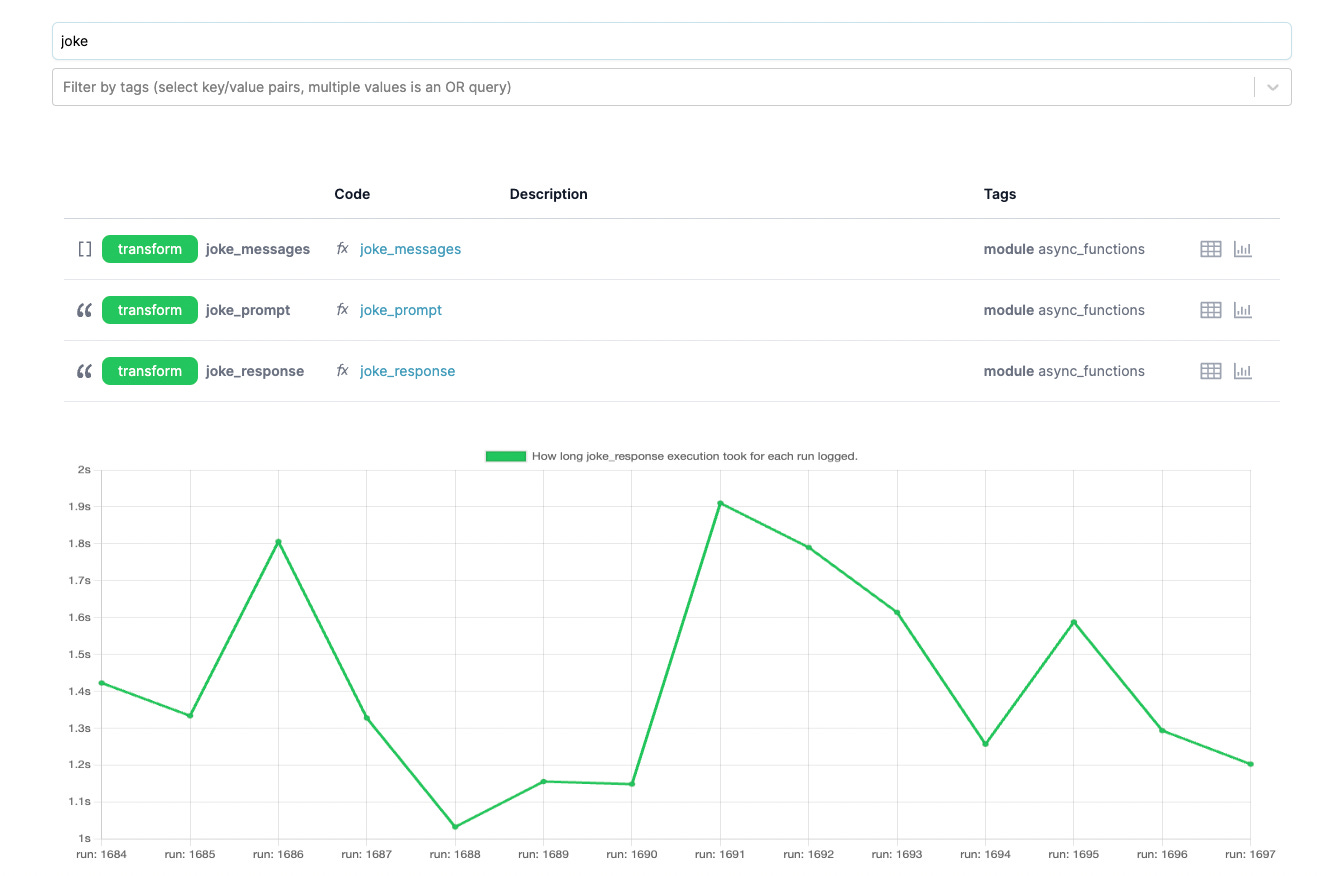
When you navigate to the UI, you’ll be able to see the DAG representation (there are a few aggregation approaches, feel free to play around).

You’ll also be able to see a waterfall chart of performance (by node):

And inspect the results:

Why don't Alexander Hamilton and Aaron Burr ever play hide and seek?
Because Hamilton always knows where Burr is...hiding in his shadow!Finally, you can view an asset catalog/link back to prior executions, results, and timed executions:

Wren’s Implementation
As we mentioned earlier, Wren AI wrote a spectacular blog post on leveraging Hamilton with Python’s async to help optimize their throughput. The TL;DR is that a Hamilton pipeline delegates to individual Haystack components, as well as their own internal constructs. With their example, the DAG looks like this:

As well as the code view:

By using async Hamilton, they were able to get more out of their Haystack components, scaling to up to 1500 simultaneous users.
Wrapping up
We’re thrilled to work more closely with Wren AI — helping them leverage all the new async features. We’ll be continually building more async features, planning on:
Automatic telemetry integration using hooks (OpenTelemetry, DataDog, etc…)
Dynamic DAG execution with async
Continual performance tuning/optimization
Getting started with Hamilton is easy — we recommend visiting tryhamilton.dev to test it out in the browser, then reading through the introduction in the docs. it’s meant to be versatile — we’ve seen OS users leveraging Hamilton to manage orchestration logic for LLMs, build feature engineering workflows in batch/online, and ingest/embed documents for RAG.
Learn more
If you’re excited by any of this, or have strong opinions, drop by our Slack channel / leave some comments here! Some resources to help you get started:
📣 join our Hamilton community on Slack — need help with Hamilton? Ask here.
⭐ give hamilton a star on github
📝 open an issue if you find any bugs/want new features
We recently launched Burr to create LLM agents and applications as well.
 | A guest post by
|