
🚀 We’re launching the Hamilton Dataflow Hub!
A place to find, pull, and share Hamilton code.



As you may know already, Hamilton is a library to author dataflows in Python. When loading a Python module, Hamilton automatically builds a directed acyclic graph (DAG) from the functions found using their name, arguments, and type annotations. This simple mechanism promotes a standardized approach to writing code (ETL, ML pipeline, LLM chains, etc.) that results in components that are reusable, easy to test, and can run anywhere Python can, e.g. a script, a cloud function, an orchestrated pipeline, in a web service!
The Hamilton Dataflow Hub is our community driven platform to discover and share your Hamilton dataflow code! In exactly 1 line of code, you can pull a dataflow to summarize a PDF with an LLM, benchmark forecast models, or interact with a database. It will get you started faster and you’ll benefit from tested, documented, typed, and reviewed code. Since your project is unique, we also make it easy to start from a dataflow on the Hub, and then edit it to your needs, so you can transition from prototype to production work quickly.
TL;DR:
We’re officially launching the community-driven Hamilton Dataflow Hub
You can use and share Hamilton dataflows in 3 lines of code
What’s unique is that you can pull “ready-to-use” code, but also seamlessly edit it to fit your project
We’re rewarding the next 50 dataflow contributions with gift cards 🎉
The Hub makes it easy to pull off-the-shelf code locally, modify it, and integrate it into your project. This approach is inline with other highly successful projects where they have demonstrated the value of “ready-to-use” components enabling you to go from 0 to 1 quickly, e.g. NLP components in LangChain, data and models on Hugging Face, connectors for Airbyte. However, these components typically rely on object-oriented abstractions that you’ll have to learn, or fight against, when adapting them to your particular situation. In contrast, Hamilton uses a very lightweight abstraction around Python functions making the code from the Hub easy to understand and modify quickly and with confidence; this is what makes our approach unique.
Note: while Hamilton is closest to LangChain in appearance, it can be used in a much broader variety of scenarios (i.e., not specific to LLM) and was expressly designed to be lightweight to make maintenance and customization simpler to reason about.

Show me
Let’s say you are starting a new project to build a retrieval augmented generative (RAG) application.
Visit the Hamilton Dataflow Hub. Use the navigation pane, the search bar (powered by Algolia), or the View By Tag section to browse available dataflows.
You found the text_summarization dataflow by DAGWorks. On its page, you’ll find a visualization, a description, and the source code of the dataflow, along with instructions on how to use it.

In your project, you can copy and paste the instructions below to pull the dataflow instructions and cache them locally (a simple .py file;
pip install sf-hamiltonif you haven’t already).from hamilton import dataflows, driver text_summarization = dataflows.import_module("text_summarization")Then, you create the dataflow by passing
text_summarizationto thedriver.Builder()and request values and pass inputs indr.execute().dr = ( driver.Builder() .with_modules(text_summarization) # pass in the dataflow .build() ) dr.display_all_functions() # pass in a path if not in a notebook result = dr.execute( ["summarized_text"], # DAG nodes to query inputs={"raw_text":...} # DAG inputs )If you want to edit
text_summarizationto add functions or change the implementation, you can create a local copy in your project.dataflows.copy(text_summarization, destination_path=”./my_modules”) # now you can do from my_modules import text_summarization
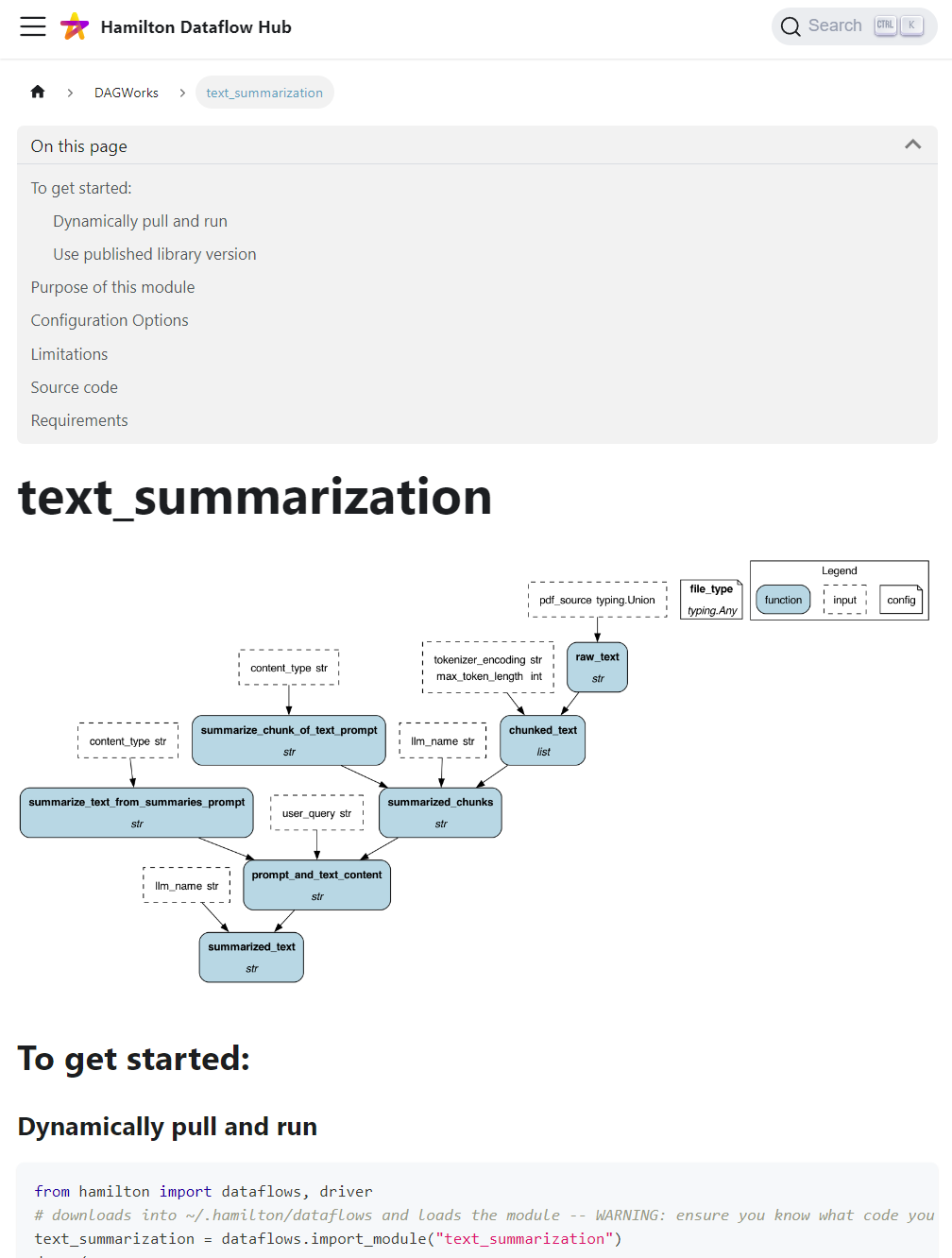
💥 You just added raw text → summary functionalities to your RAG application in 2 minutes! Now, you probably need a more bespoke strategy to get your raw text (web page → raw text) or store the summaries (summary → vector database).
You can browse the Hub for dataflows fulfilling that task, or define them in local files using Hamilton. Then, you can stitch them together in a single dataflow!
from hamilton import driver # you'd create some more modules to import... from my_modules import text_summarization, pdf_to_text, vector_db dr = ( driver.Builder() .with_modules(pdf_to_text, text_summarization, vector_db) .build() )
New to Hamilton?
To reiterate what Hamilton is for those that are new to it. It is a declarative micro-framework to describe dataflows in Python. Its strength is expressing the flow of data and computation in a straightforward and easy to maintain manner (much like dbt does for SQL). Each Python function defines an artifact (feature, loaded data, trained model, result of an external API call, etc.) using the function’s name and type, and its parameters name and type correspond to its dependencies (other artifacts or external inputs). Hamilton automatically builds a DAG from these artifact definitions. Then, you can query artifacts and only the required dependencies will be executed to provide your results. For more details & posts on Hamilton see the links at the bottom.
Hamilton is all about functions. To help ground why we think it’s a clearer and more maintainable way to write code, let’s look at some code. See LangChain code on the left and the Hamilton equivalent on the right:

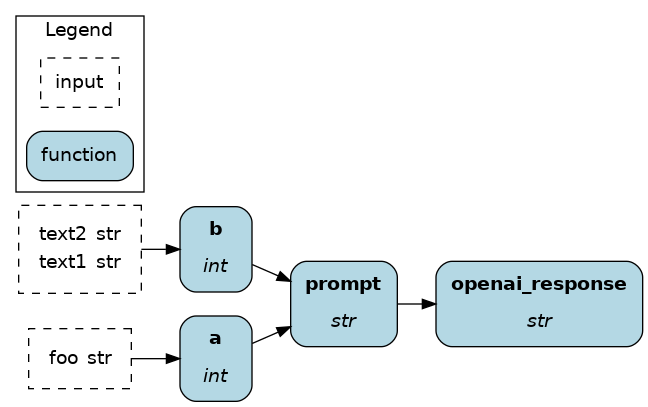
I don’t think we’re biased when we say that the LangChain code on the left requires a bit of time to unpack and understand what is going on. Now, picture yourself having to modify it? How would you approach it? Is it clear what to do? With Hamilton, we think it’s clearer and easier to understand what a and b are – and then how they feed into the prompt, and the prompt to openai_response. Unlike the code on the left where there is a coupling of definition and execution, with Hamilton code on the right, there is no such coupling, meaning that you can reuse the functions defined in other contexts from the beginning without having to refactor your code! Bonus, Hamilton can visualize this for you easily:
Our vision
The data and machine learning ecosystem is built on incredible open source contributions (libraries, tools, platforms, datasets, models, etc.). Yet, knowledge on how to solve specific problems (e.g., ingest PDFs, forecast sales) or use all of these awesome contributions is scattered across notebooks and hard to reuse or modify, examples.
Hamilton tackles the problem of standardizing how to engineer a dataflow (e.g., ETL, ML pipeline, LLM Workflow) and with the Hub we’re making it easy to share and reuse Hamilton code for the open source community. With Hamilton being both lightweight and domain agnostic, we hope to see the Hub provide off-the-shelf solutions and boilerplate getting started code across a variety of use cases from NLP pipelines, to web scraping, to time-series forecasting, and beyond!

Since the Hub is only as valuable as the code that’s on it, to kickstart getting more contributions, we’re offering the first 50 successful contributions to the Hub $50USD gift cards! Here’s some ideas for inspiration if you need it.
📈 We are also opening a leaderboard to provide metrics on views and downloads for dataflows contributed (refreshed weekly for now). Want notoriety and infamy? Contribute some code on the Hub and get people to use it 🤓.
Get started now
pip install sf-hamilton😎 Visit the Hamilton Dataflow Hub to pull your first dataflow
📚 Here’s a notebook demo that you can clone/copy to get started.
📑 Instructions to contribute your own dataflow!
⭐️ Check out the Hamilton repository and current contributions. Give us a star too!
⌨️ New to Hamilton? Try our interactive in browser tutorial to learn the basics.
Need versioning, lineage, catalog, and observability?
Connect your Hamilton code with a one-line code change to the DAGWorks Platform. Sign up today, there’s a free tier to kick the tires.