
Tracking Pipelines with MLFLow & Hamilton
Introducing a new Hamilton ↔ MLFlow integration!



In this post we discuss the new MLFlow integration we built for Hamilton. We begin with a quick overview of the two libraries. Then, we present the new features and share how you can use it to manage your experiments. This is meant to complement
this showcase video (embedded later as well).
The Tools

Hamilton
Hamilton is a standardized way of building data pipelines in Python. The core concepts are simple – you write each data transformation step as a single Python function with the following rules:
The name of the function corresponds to the output variable it computes.
The parameter names (and types) correspond to inputs. These can be either passed-in parameters or names of other upstream functions.
This approach allows you to represent assets in ways that correspond closely to code, naturally self-documenting, and portable across infrastructure.

After writing your functions, you call a driver to execute them – in most cases this is a simple import/run (specifying the assets you want computed and letting the framework do the rest), but it provides options to customize execution:

Hamilton powers a wide range of use cases including feature engineering, ML training/inference pipelines (relevant to this post), RAG pipelines, and more.
It also comes with a data loading capability called “materializers”. Materializers allow you to load data into the DAG and save data from the DAG. They’re a simple alteration. In this case, we’re saving a dictionary with a, b, and c to the output.json file — we do this by adding a materializer to the DAG (it will become a node) then requesting execution of it. Hamilton will then execute after all its upstream dependencies:
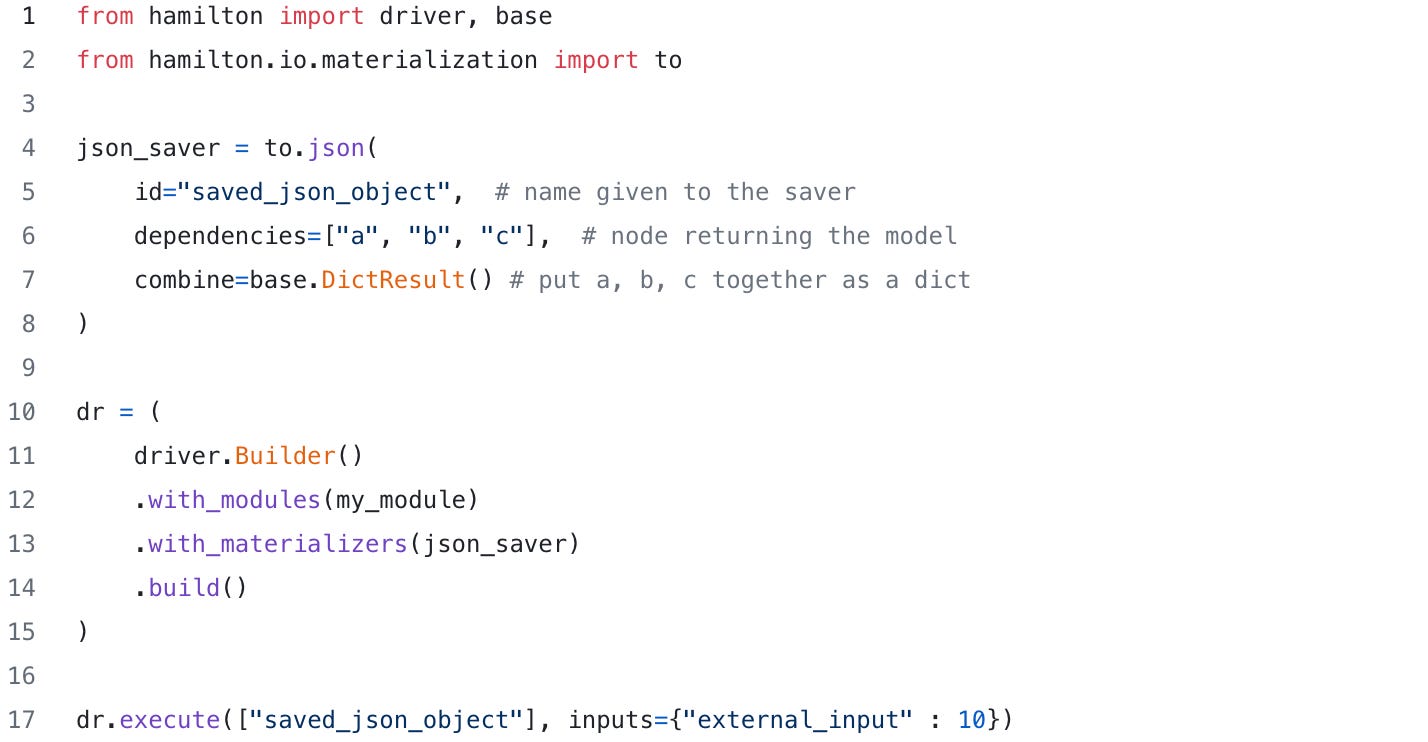
We mention materializers because we’ll make use of them later in the post.
MLFlow
From their github — MLFlow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (e.g. in notebooks, standalone applications or the cloud). MLflow's current components are:
MLflow Tracking: An API to log parameters, code, and results in machine learning experiments and compare them using an interactive UI.
MLflow Projects: A code packaging format for reproducible runs using Conda and Docker, so you can share your ML code with others.
MLflow Models: A model packaging format and tools that let you easily deploy the same model (from any ML library) to batch and real-time scoring on platforms such as Docker, Apache Spark, Azure ML and AWS SageMaker.
MLflow Model Registry: A centralized model store, set of APIs, and UI, to collaboratively manage the full lifecycle of MLflow Models.
The Python API follows a standard approach to logging and can capture many artifacts — here’s an example of logging parameters, metrics, & model for a machine learning training run (adapted from the tutorial):

MLFlow Pains
MLFlow is great for storing the output of a pipeline. However, there a couple challenges:
Everyone integrates it with their pipelines differently. As MLFlow depends on users instrumenting their code, this leads to inconsistencies at a team level that can make the data stored less useful/less trustworthy. It can also make your code harder to maintain.
Your code requires MLFlow to be installed to run.
This is where Hamilton is a great complement to MLFlow. Hamilton standardizes how pipelines are written, providing a means to visualize, track, and document code that integrates with MLFlow. More specifically, we can use the structure of the graph to remove the need for people to directly to log to MLFlow. As the integration occurs at the Hamilton Driver level it can automatically log the right artifacts!
While the quality of life improvements here may not be apparent to everyone, we have found that they ring truest to those who frequently have to maintain others pipelines. If that does not describe you, don’t worry, it probably will soon :)
The Integration
There are two touch-points between Hamilton and MLFlow:
Materializers to save and load machine learning models (as described above).
Hamilton lifecycle adapters to automatically track runs of pipelines as an experiment.
The following example uses a simple training pipeline. You can download and run this code from this repository.
MLFlow Materialization
Hamilton offers materializers to save and load data using MLFlow. Saving a model looks like this:

When we visualize in Hamilton, you can actually see the graph is modified! We now have a node (trained_model_mlflow) that has been appended to the graph. This allows one to quickly and easily add saving to MLFlow, without going back to rewrite the logic of the pipeline.

There is also a way to load models from the registry. See example notebook for the rest of the example.
Hamilton Runs → MLFlow Experiments
Hamilton can automatically set up/log to an MLFlow experiment automatically. We do this by a lifecycle adapter, allowing us to customize the Hamilton driver’s execution by managing experiments/logging to MLFlow.
You can use it by appending a line to the driver (note a theme? Hint — it’s all a one-line change…). Note, for simplicity, the following removes the materializer, but typically you’d keep that in.

Then, if you ask for outputs that are for any of the supported types (scalar, plot, model using materializer above, etc…) it’ll automatically get logged to your MLFlow experiment! E.g. the following assumes you’ve added a few more nodes that compute metrics/plots.

This enables a clear separation of logic from instrumentation. It also means that new pipelines authored by folks will be structured similarly, and it’ll be clear from the pipeline run, what is generated and thus stored in MLFlow.
See the video below for how both these approaches look in the MLFlow UI.
The Workflow
The integrations we showed above give you a powerful capability — to leverage the value of MLFlow, you don’t have to add any MLFlow code to your pipeline! Hamilton will give it to you for free. Thus you can track Hamilton runs using MLFlow. Note you can also link from the Hamilton UI to MLFlow to use both.
For more information, see this video, where Thierry Jean goes over the various MLFlow integrations and workflow implications in more detail.
Looking Ahead
We’re really excited about Hamilton + MLFlow together. In the future we’ll be adding:
Integration with MLFlow tracing
Integration with datasets
Bidirectional linking between MLFlow and the Hamilton UI
We want to hear from you!
If you’re excited by any of this, or have strong opinions, drop by our Slack channel / leave some comments here! Some resources to help you get started:
📣 join our Hamilton community on Slack — need help with Hamilton? Ask here.
📝 leave us an issue if you find something
⭐ give us a star on the Hamilton repository if you like what we’re working on!
We recently launched Burr to create LLM agents and applications.