
Feature release: Caching
How to develop faster and more reliably with Hamilton caching



With release 1.79.0 Hamilton now offers caching of execution results! With caching enabled, executing a node will store results on disk along with some metadata. On subsequent executions, it will automatically skip execution of any previously executed steps by loading results. To enable it, simply add .with_cache() to your Builder
from hamilton import driver
import my_pipeline
dr = (
driver.Builder()
.with_modules(my_pipeline)
.with_cache()
.build()
)Here are some scenarios where caching is a clear win:
Faster development iterations (in scripts or notebooks)
Avoid cost of repeated LLM calls and embeddings during agent development
Incrementally load data by skipping previously processed files
Recover from errors during debugging a data pipeline, starting where you left off
This blog will detail why we built caching and how it works. Then, we’ll illustrate some of these use cases that caching can help you with! First, let’s go over the basics of Hamilton (skip the next section if you’re already familiar).
Hamilton 101
Hamilton is a standardized way of building data pipelines in Python. The core concepts are simple – you write each data transformation step as a single Python function with the following rules:
The name of the function corresponds to the output variable it computes.
The parameter names (and types) correspond to inputs. These can be either passed-in parameters or names of other upstream functions.
This approach allows you to represent assets in ways that correspond closely to code, naturally self-documenting, and portable across infrastructure.

Then, you create a Driver from this dataflow definition and you can use it to execute code. In the next snippet, we request the node C for external_input=12.

The pain of expensive operations
If you're working in data (e.g., data science, machine learning, ETL, BI, LLM applications) you know the feeling of launching a script or a notebook cell, and having a minute+ to get results.
Unless there's a bug midway that makes the job fail... Hopefully, it happened before that expensive operation (SQL join, model training, downloading large data, sending a batch of paid LLM requests) 💸💸 Or maybe the job did complete, but there are obvious mistakes in the produced data... Unsure, you prefer running the job twice to check if results match 🤞
load dataset >> chunk >> embed >> evaluate RAG
To alleviate this pain, you can start to create custom checkpoints by saving intermediary results and adding some logic to load checkpoints if available.
load dataset >> chunk >> embed > checkpoint > evaluate RAG
However, as your project grows in complexity, so does your checkpointing code. It’s more to manage. Also, checkpointing logic can be difficult to generalize between dev/prod and across projects in general.
Did this properly overwrite the previous checkpoint?
Which checkpoint was loaded exactly?
What is caching?
Caching broadly means "reusing stored results instead of repeating operations”, in other words, it is automated checkpointing. To make this possible, Hamilton versions the code that defines the node and the values passed to it.
For example, let’s take this 3 node dataflow and focus on processed_data()
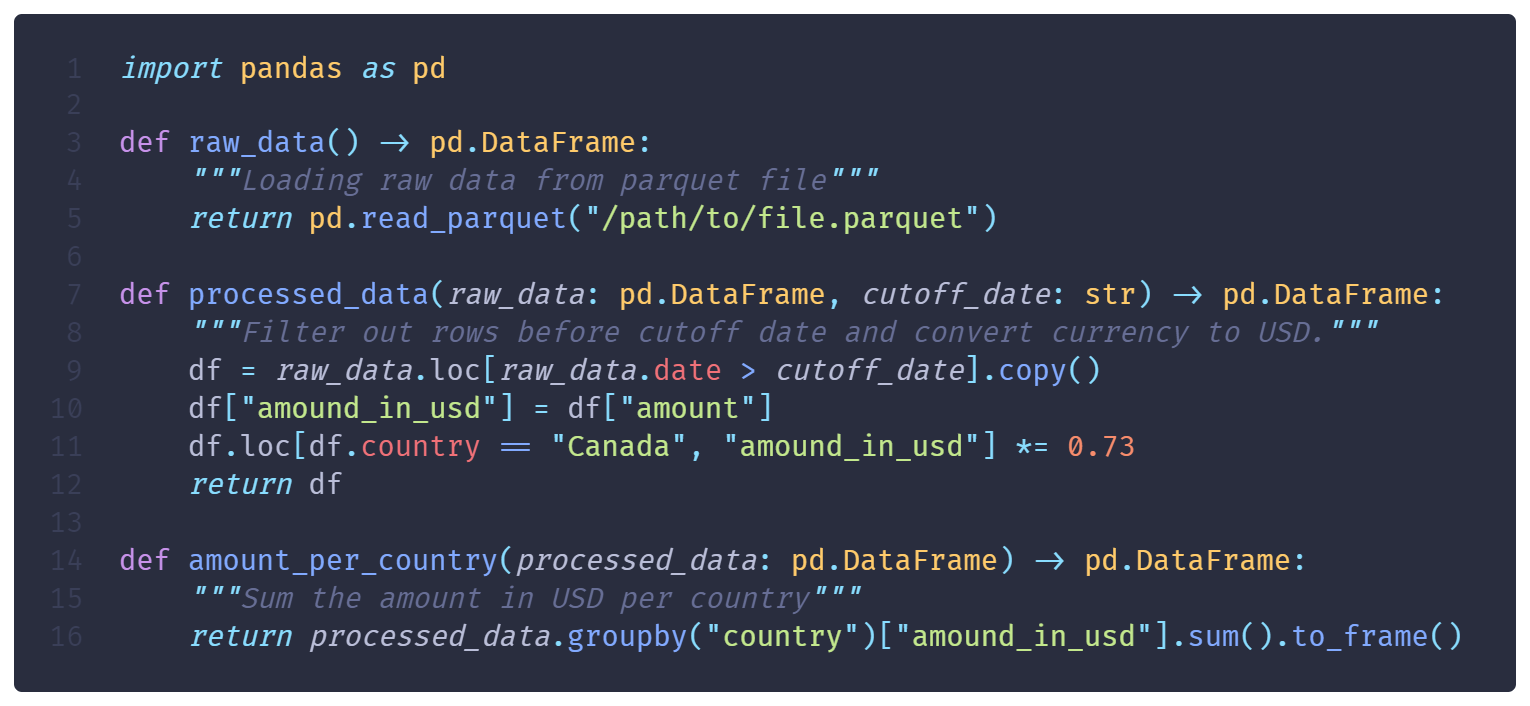

After executing it once, its result will be stored. On the second execution, the node will be skipped (cache hit) if it receives the same values for raw_data or cutoff_date.
It would be a cache miss if:
the value for
raw_datais differentthe value for
cutoff_dateis differentthe function
processed_data()was edited (e.g., change the currency conversion from 0.73 to 0.75)
Caching in Hamilton
To get started with caching in Hamilton, just add .with_cache() to your Driver.

To get more information about execution, you can retrieve the logger and set the level to INFO or DEBUG

There's also a new visualization included via the Driver.cache attribute
dr.cache.view_run()
Hamilton’s caching comes with effective defaults, its behavior can also be tuned node-by-node:
the “caching behavior”: default, always recompute, default, ignore (and more)
how to version data for specific Python types
how to create cache key
where to store metadata and results (could be different places, by project, globally)
Providing this amount of control to the user allows for optimal execution.
To learn more about caching in Hamilton, feel free to complete the tutorial (GitHub, Colab) or review the documentation.
Caching in notebooks
Caching pairs nicely with the Hamilton notebook extension, which allows you to define your dataflow in a notebook cell (see tutorial).

Say you're developing the above retrieval-augmented generation (RAG) application. It involves multiple steps (loading, parsing, chunking, etc.) with many potential approach for each step. If you try a new embedding step, you'll be able to automatically skip the upstream loading, parsing, and chunking!
Another benefit of caching is that you can safely restart the notebook kernel and shutdown your computer after a long day of work. When you'll come back, you can resume from where you left!
Caching with dynamic dataflows
Hamilton provides the constructs Parallelizable and Collect to create multiple branches of the same processing steps (learn more). For example, you can retrieve HTML pages for multiple URLs and extract articles from it.
The image below shows a dataflow where url “expands” in many branches that will be collected at collect_chunked_url_text. Each branch will execute: article_text, chunked_text, and url_result

When using Parallelizable/Collect with caching, branches are cached individually. Consequently if there's an error with the 7th URL, the first 6 sucessful branches will skipped on retry. Similarly, if you successfully executed 10 URLs and add 2 more, only the new ones will be executed. This can be a useful pattern for incremental loading.
Caching for debugging
Caching can also be a helpful tool for debugging your Hamilton dataflow. Let’s say you’re running your dataflow via a script and it fails midway through. If you have caching enabled, you can open an interactive session or a notebook, create a new Driver and start debugging.
from hamilton import driver
import my_module
dr = (
driver.Builder()
.with_modules(my_module)
.with_cache(path=...) # point to the cache used by the script
.build()
)You can call dr.execute() to see if the error is reproduced. From there, you can modify the dataflow in my_module and try re-executing, and steps unchanged will be automatically skipped! Hamilton also provides structured logs and entry points to manually inspect metadata and results produced by the cache (learn more).
We’ll soon be supporting caching on AWS, GCP, Azure, and more. This will allow the same debugging pattern of dataflows deployed via Airflow et al. Reach out to us if you’re interested in this feature - find us in Hamilton’s slack.
We want to hear from you!
Caching is a new core feature of Hamilton that we want to improve and expand. It already benefits many use cases, but we want to know your experience and ideas!
If you’re excited or have strong opinions, join our Hamilton community on Slack . It’s also a great place to get help with Hamilton!
📝 leave us an issue if you find something
⭐ give us a star on the Hamilton repository if you like what we’re working on!
We recently launched Burr to create LLM agents and applications.


