
Burr UI ++
Burr's Open Source UI that comes with: Traces, Attributes, Insights, and More


This week we completed (and started) a major UI upgrade for Burr. We’re really excited about this, so we’re writing a quick post to share out the new features in the hope that you’ll be inspired to play around.
First, let’s quickly go over Burr.
Burr
Burr is a lightweight Python library you use to build applications as stateful graphs. You construct your application out of a series of actions (these can be either decorated functions or objects), which declare inputs from state, as well as inputs from the user. These specify custom logic (delegating to any framework), as well as instructions on how to update state. State is immutable, which allows you to inspect it at any given point. Burr handles orchestration, monitoring, persistence, etc.

You run your Burr actions as part of an application – this allows you to string them together with a series of (optionally) conditional transitions from action to action.
You can visualize this as a flow chart, i.e. graph / state machine:

Burr is often (but not always) used to build interactive LLM applications. State management, visibility, and persistence is all critical with AI, and Burr is meant to ensure that you get those capabilities for free and not have to think about them. To aid in visibility, Burr allows you to log spans in an OpenTelemetry-compatible format as well as any arbitrary attributes during execution.
Burr comes with a user-interface that enables monitoring/telemetry that we will showcase in this post. To illustrate, we’ll be borrowing from one of our favorite examples: a multi-modal chatbot. It emulates something like the ChatGPT UI, using a model to check the safety of the response, a model to decide the mode, and a model for each response type (image, code, question-answer, etc…).
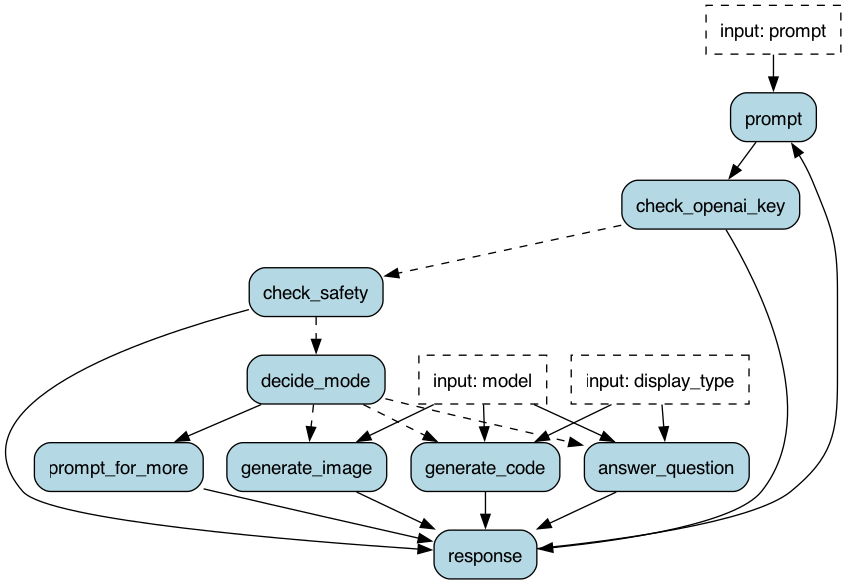
You can run this with the following command (note you must have an OpenAI API Key set as OPENAI_API_KEY):
pip install "burr[start]"
burr # opens on port 7241Then navigate to “demos” on the left hand side, and click on chatbot (or streaming-chatbot, they illustrate the same concepts). Preload the existing chats, or follow the instructions to run your own.

You can watch it run through when you submit (note, it will terminate early on check_openai_key if you don’t have one), and preloading any of the demo runs will have the full set of visibility available.
Traces/Spans
Burr functions as a lightweight OpenTelemetry provider (see this post for more details) — it can both produce and ingest spans/traces (if they occur within the execution of a burr node).
To visualize, Burr presents a full waterfall view with timing

You can expand all (or individual) actions to view spans, by clicking on the (+) sign next to Action:

You can view the corresponding state at any given point in time as well, as well as a host of other debugging information (code, graph shape, test case fixture creation, etc…):
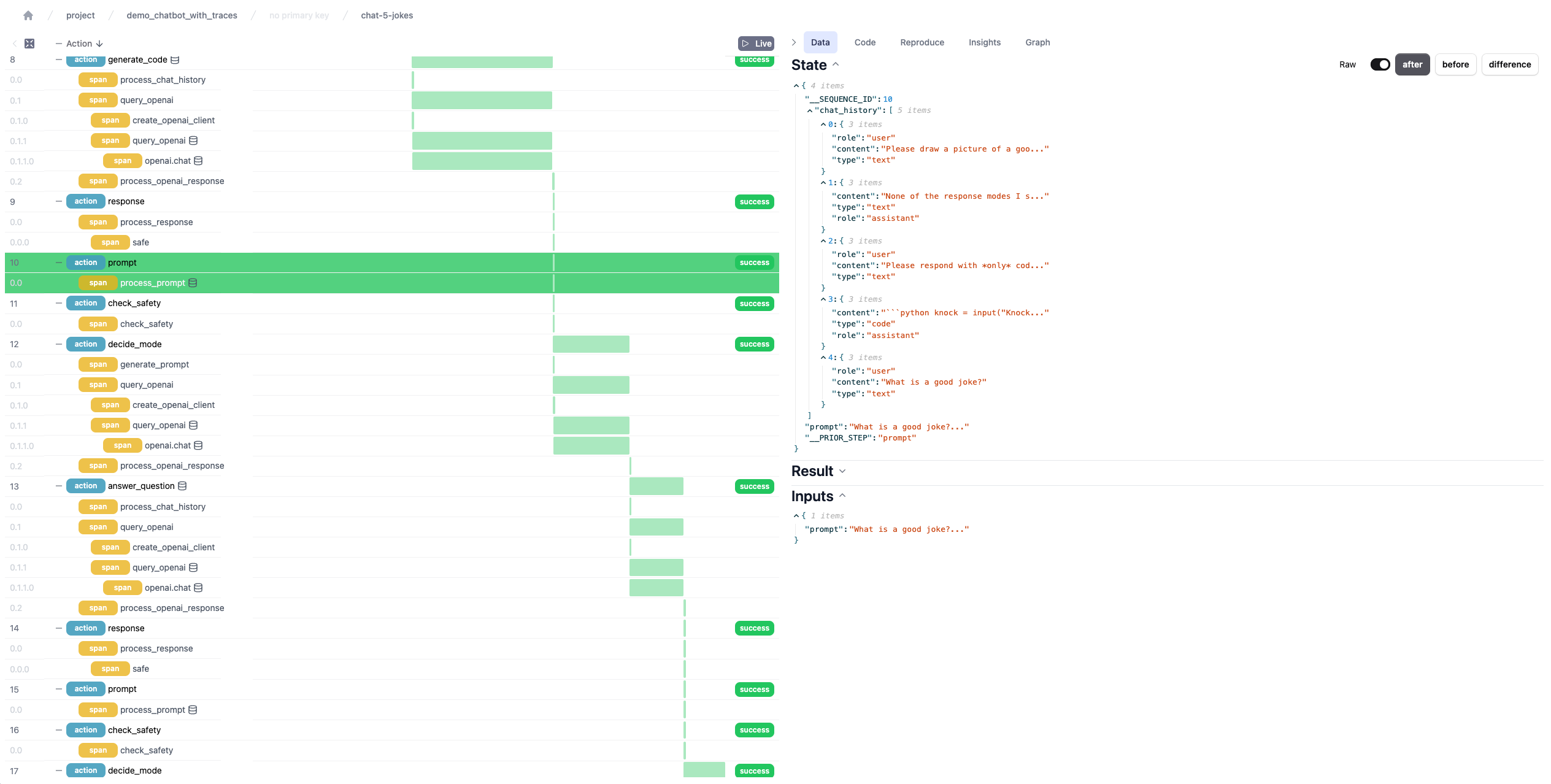
This helps you isolate issues post-hoc — determining the exact point in code at which, say, a hallucination occurred, or, if code breaks, the exact state that caused the issue.
Attributes
Burr allows you to go one step deeper — you can log any number of attributes and attach it to a trace/action. This works especially well with OpenTelemetry auto-instrumentation (see this post for instructions), and you can use Burr’s Trace API to log any serializable data.
Attributes show up inline, allowing you to see the prompt, the chat history, etc…
Note this will show up anywhere an instrumented call is made, so for every LLM call you can view attributes. You can also view the number of tokens (prompt/completion), as well as other metadata about the chat itself.
This helps you dig into the exact context in which any step ran, allowing you insight below the function-level.
Insights
Burr also enables you to look at the application as a whole — answering questions on total token usage, broken up by step. The insights tab gives you application-scoped data aggregated by step/span, enabling you to determine which steps cost the most to answer.

Note we currently have a few LLM-specific insights, but plan to add more shortly — including direct cost metrics, timing, and aggregations of other (more arbitrary metrics). Stay tuned!
Future Plans
We’re just getting started. We’re particularly excited about OpenTelemetry data — by automatically instrumenting LLM calls, we actually have enough data to launch an interactive prompt playground, from any point in the application’s call-stack! Here’s a sneak-peak of a streamlit prototype that allows you to load up an LLM call at any point and reproduce/play with it.

We have a host of other ideas in the works — but we operate largely on feedback. If you have any feedback/suggestions, please let us know!
More Resources
Join our Discord for help or if you have questions!
Github repository for Burr (give us a star if you like what you see!)