
Hamilton DAG Workflow for Toy Text Processing Script
Special Guest Post by a happy Hamilton user



This is a guest post by CARL BARTHOLOMEW TRACHTE, who was happy to let us copy it over from his original blog, pyright. He doesn’t write often, but when it does it’s insightful and relevant!
Hello. It's been a minute.
I was fortunate to attend PYCON US in Pittsburgh earlier this year. DAGWorks had a booth on the expo floor where I discovered Hamilton. The project grabbed my attention as something that could help organize and present my code workflow better. My reaction could be compared to browsing Walmart while picking up a hardware item and seeing the perfect storage medium for your clothes or crafts at a bargain price, but even better, having someone there to explain the whole thing to you. The folks at the booth were really helpful.
Below I take on a contrived web scraping (it's crude) script in my domain (metals mining) and create a Hamilton workflow from it.
Pictured below is the Hamilton flow in the graphviz output format the project uses for flowcharts (graphviz has been around for decades - an oldie but goodie as it were).
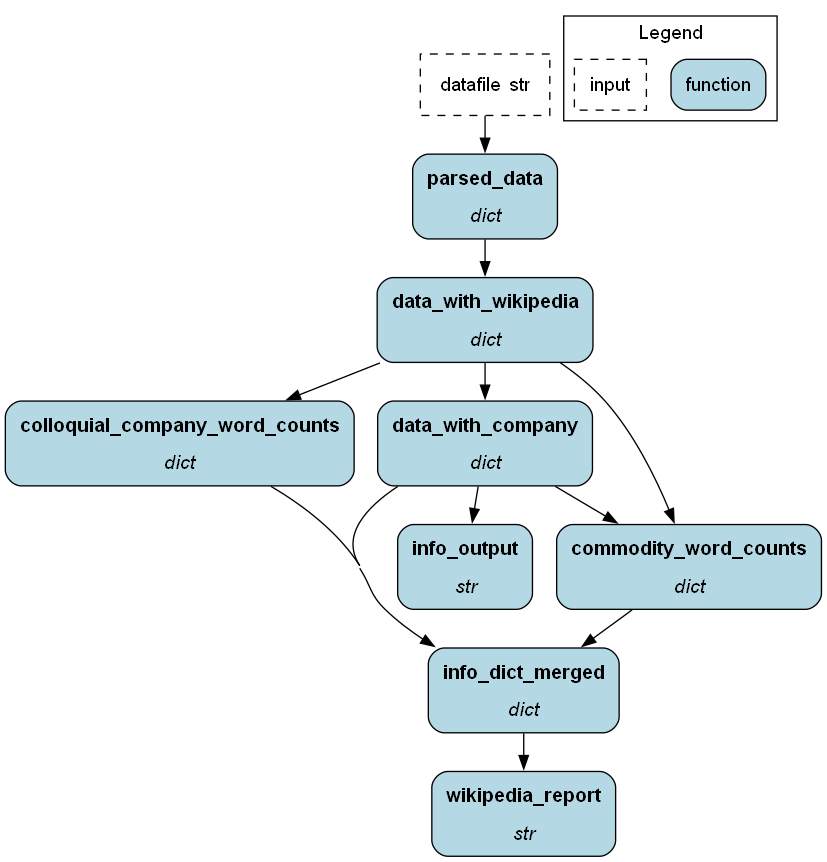
I start with a csv file that has some really basic data on three big American metal mines (I did have to research the Wikipedia addresses - for instance, I originally looked for the Goldstrike Mine under the name "Post-Betze." It goes by several different names and encompasses several mines - more on that anon):

Basically, I am going to attempt to scrape Wikipedia for information on who owns the three mines. Then I will try to use heuristics to gather information on what I think I know about them and gauge how up to date the Wikipedia information is.
Hamilton uses a system whereby you name your functions in a noun-like fashion ("def stuff()" instead of "def getstuff()") and feed those names as variables to the other functions in the workflow as parameters. This is what allows the tool to check your workflow for inconsistencies (types, for instance) and build the graphviz chart shown above.
You can use separate modules with functions and import them. I've done some of this on the bigger workflows I work with. Your Hamilton functions then end up being little one liners that call the bigger functions in the modules. This is necessary if you have functions you use repeatedly in your workflow that take different values at different stages. For this toy project, I've kept the whole thing self contained in one module toyscriptiii.py (yes, the iii in the filename represents my multiple failed attempts at web scraping and text processing - it's harder than it looks).
Below is the Hamilton main file run.py (I believe the "run.py" name is convention.) I have done my best to preserve the dictionary return values as "faux immutable" through use of the copy module in each function. This helps me in debugging and examining output, much of which can be done from the run.py file (all the return values are stored in a dictionary). I've worked with a dataset with about 600,000 rows that had about 10 nodes. My computer has 32GB of RAM (Windows 11); it handled memory fine (less than half). For really big data, keeping all these dictionaries in memory might be a problem.
| # python 3.12 | |
| """ | |
| Hamilton demo. Runs the Hamilton code. | |
| """ | |
| import sys | |
| import pprint | |
| from hamilton import driver | |
| import toyscriptiii as ts # defined below | |
| dr = driver.Builder().with_modules(ts).build() | |
| dr.display_all_functions("ts.png", deduplicate_inputs=True, keep_dot=True, orient='BR') | |
| results = dr.execute(['parsed_data', | |
| 'data_with_wikipedia', | |
| 'data_with_company', | |
| 'info_output', | |
| 'commodity_word_counts', | |
| 'colloquial_company_word_counts', | |
| 'info_dict_merged', | |
| 'wikipedia_report'], | |
| inputs={'datafile':'data.csv'}) | |
| pprint.pprint(results['info_dict_merged']) | |
| print(results['info_output']) | |
| print(results['wikipedia_report']) |
| # python 3.12 | |
| """ | |
| Toy script. | |
| Takes some input from a csv file on big American | |
| mines and looks at Wikipedia text for some extra | |
| context. | |
| """ | |
| import copy | |
| import pprint | |
| import sys | |
| from urllib import request | |
| import re | |
| from bs4 import BeautifulSoup | |
| def parsed_data(datafile:str) -> dict: | |
| """ | |
| Get csv data into a dictionary keyed on mine name. | |
| """ | |
| retval = {} | |
| with open(datafile, 'r') as f: | |
| headers = [x.strip() for x in next(f).split(',')] | |
| for linex in f: | |
| vals = [x.strip() for x in linex.split(',')] | |
| retval[vals[0]] = {key:val for key, val in zip(headers, vals)} | |
| pprint.pprint(retval) | |
| return retval | |
| def data_with_wikipedia(parsed_data:dict) -> dict: | |
| """ | |
| Connect to wikipedia sites and fill in | |
| raw html data. | |
| Return dictionary. | |
| """ | |
| retval = copy.deepcopy(parsed_data) | |
| for minex in retval: | |
| obj = request.urlopen(retval[minex]['wikipedia page']) | |
| html = obj.read() | |
| soup = BeautifulSoup(html, 'html.parser') | |
| print(soup.title) | |
| # Text from html and strip out newlines. | |
| newstring = soup.get_text().replace('\n', '') | |
| retval[minex]['wikipediatext'] = newstring | |
| return retval | |
| def data_with_company(data_with_wikipedia:dict) -> dict: | |
| """ | |
| Fetches company ownership for mine out of | |
| Wikipedia text dump. | |
| Returns a new dictionary with the company name | |
| without the big wikipedia text dump. | |
| """ | |
| # Wikipedia setup for mine company name. | |
| COMPANYPAT = r'[a-z]Company' | |
| # Lower case followed by upper case heuristic. | |
| ENDCOMPANYPAT = '[a-z][A-Z]' | |
| retval = copy.deepcopy(data_with_wikipedia) | |
| companypat = re.compile(COMPANYPAT) | |
| endcompanypat = re.compile(ENDCOMPANYPAT) | |
| for minex in retval: | |
| print(minex) | |
| match = re.search(companypat, retval[minex]['wikipediatext']) | |
| if match: | |
| print('Company match span = ', match.span()) | |
| companyidx = match.span()[1] | |
| match2 = re.search(endcompanypat, retval[minex]['wikipediatext'][companyidx:]) | |
| print('End Company match span = ', match2.span()) | |
| retval[minex]['company'] = retval[minex]['wikipediatext'][companyidx:companyidx + match2.span()[0] + 1] | |
| # Get rid of big text dump in return value. | |
| retval[minex].pop('wikipediatext') | |
| return retval | |
| def info_output(data_with_company:dict) -> str: | |
| """ | |
| Prints some output text to a file for each | |
| mine in the data_with_company dictionary. | |
| Returns string filename of output. | |
| """ | |
| INFOLINEFMT = 'The {mine:s} mine is a big {commodity:s} mine in the State of {state:s} in the US.' | |
| COMPANYLINEFMT = '\n {company:s} owns the mine.\n\n' | |
| retval = 'mine_info.txt' | |
| with open(retval, 'w') as f: | |
| for minex in data_with_company: | |
| print(INFOLINEFMT.format(**data_with_company[minex]), file=f) | |
| print(COMPANYLINEFMT.format(**data_with_company[minex]), file=f) | |
| return retval | |
| def commodity_word_counts(data_with_wikipedia:dict, data_with_company:dict) -> dict: | |
| """ | |
| Return dictionary keyed on mine with counts of | |
| commodity (e.g., zinc etc.) mentions on Wikipedia | |
| page (excluding ones in the company name). | |
| """ | |
| retval = {} | |
| # This will probably miss some occurrences at mashed together | |
| # word boundaries. It is a rough estimate. | |
| # '\b[Gg]old\b' | |
| commoditypatfmt = r'\b[{0:s}{1:s}]{2:s}\b' | |
| for minex in data_with_wikipedia: | |
| print(minex) | |
| commodityuc = data_with_wikipedia[minex]['commodity'][0].upper() | |
| commoditypat = commoditypatfmt.format(commodityuc, | |
| data_with_wikipedia[minex]['commodity'][0], | |
| data_with_wikipedia[minex]['commodity'][1:]) | |
| print(commoditypat) | |
| commoditymatches = re.findall(commoditypat, data_with_wikipedia[minex]['wikipediatext']) | |
| # pprint.pprint(commoditymatches) | |
| nummatchesraw = len(commoditymatches) | |
| print('Initial length of commoditymatches is {0:d}.'.format(nummatchesraw)) | |
| companymatches = re.findall(data_with_company[minex]['company'], | |
| data_with_wikipedia[minex]['wikipediatext']) | |
| numcompanymatches = len(companymatches) | |
| print('Length of companymatches is {0:d}.'.format(numcompanymatches)) | |
| # Is the commodity name part of the company name? | |
| print('commoditypat = ', commoditypat) | |
| print(data_with_company[minex]['company']) | |
| commoditymatchcompany = re.search(commoditypat, data_with_company[minex]['company']) | |
| if commoditymatchcompany: | |
| print('commoditymatchcompany.span() = ', commoditymatchcompany.span()) | |
| nummatchesfinal = nummatchesraw - numcompanymatches | |
| retval[minex] = nummatchesfinal | |
| else: | |
| retval[minex] = nummatchesraw | |
| return retval | |
| def colloquial_company_word_counts(data_with_wikipedia:dict) -> dict: | |
| """ | |
| Find the number of times the company you associate with | |
| the property/mine (very subjective) is within the | |
| text of the mine's wikipedia article. | |
| """ | |
| retval = {} | |
| for minex in data_with_wikipedia: | |
| colloquial_pat = data_with_wikipedia[minex]['colloquial association'] | |
| print(minex) | |
| nummatches = len(re.findall(colloquial_pat, data_with_wikipedia[minex]['wikipediatext'])) | |
| print('{0:d} matches for colloquial association {1:s}.'.format(nummatches, colloquial_pat)) | |
| retval[minex] = nummatches | |
| return retval | |
| def info_dict_merged(data_with_company:dict, | |
| commodity_word_counts:dict, | |
| colloquial_company_word_counts:dict) -> dict: | |
| """ | |
| Get a dictionary with all the collected information | |
| in it minus the big Wikipedia text dump. | |
| """ | |
| retval = copy.deepcopy(data_with_company) | |
| for minex in retval: | |
| retval[minex]['colloquial association count'] = colloquial_company_word_counts[minex] | |
| retval[minex]['commodity word count'] = commodity_word_counts[minex] | |
| return retval | |
| def wikipedia_report(info_dict_merged:dict) -> str: | |
| """ | |
| Writes out Wikipedia information (word counts) | |
| to file in prose; returns string filename. | |
| """ | |
| retval = 'wikipedia_info.txt' | |
| colloqfmt = 'The {0:s} mine has {1:d} occurrences of colloquial association {2:s} in its Wikipedia article text.\n' | |
| commodfmt = 'The {0:s} mine has {1:d} occurrences of commodity name {2:s} in its Wikipedia article text.\n\n' | |
| with open(retval, 'w') as f: | |
| for minex in info_dict_merged: | |
| print(colloqfmt.format(info_dict_merged[minex]['mine'], | |
| info_dict_merged[minex]['colloquial association count'], | |
| info_dict_merged[minex]['colloquial association']), file=f) | |
| print(commodfmt.format(info_dict_merged[minex]['mine'], | |
| info_dict_merged[minex]['commodity word count'], | |
| info_dict_merged[minex]['commodity']), file=f) | |
| return retval |
My REGEX abilities are somewhere between "I've heard the term REGEX and know regular expressions exist" and bracketed characters in each slot brute force. It worked for this toy example. Each Wikipedia page features the word "Company" followed by the name of the owning corporate entity.
Here is are the two text outputs the script produces from the information provided (Wikipedia articles from July, 2024):
The Red Dog mine is a big zinc mine in the State of Alaska in the US.
NANA Regional Corporation owns the mine.
The Goldstrike mine is a big gold mine in the State of Nevada in the US.
Barrick Gold owns the mine.
The Bingham Canyon mine is a big copper mine in the State of Utah in the US.
Rio Tinto Group owns the mine.
The Red Dog mine has 21 occurrences of colloquial association Teck in its Wikipedia article text.
The Red Dog mine has 29 occurrences of commodity name zinc in its Wikipedia article text.
The Goldstrike mine has 0 occurrences of colloquial association Nevada Gold Mines in its Wikipedia article text.
The Goldstrike mine has 16 occurrences of commodity name gold in its Wikipedia article text.
The Bingham Canyon mine has 49 occurrences of colloquial association Kennecott in its Wikipedia article text.
The Bingham Canyon mine has 84 occurrences of commodity name copper in its Wikipedia article text.Company names are relatively straightforward, although mining company and properties acquisitions and mergers being what they are, it can get complicated. I unwittingly chose three properties that Wikipedia reports as having one owner. Other big mines like Morenci, Arizona (copper) and Cortez, Nevada (gold) show more than one owner; that case is for another programming day. The Goldstrike information might be out of date - no mention of Nevada Gold Mines or Newmont (one mention, but in a different context). The Cortez Wikipedia page is more current, although it still doesn't mention Nevada Gold Mines.
The inclusion of colloquial association in the input csv file was an afterthought based on a lot of the Wikipedia information not being completely in line with what I thought I knew. Teck is the operator of the Red Dog Mine in Alaska. That name does get mentioned frequently in the Wikipedia article.
Enough mining stuff - it is a programming blog after all. Next time (not written yet) I hope to cover dressing up and highlighting the graphviz output a bit.
Thank you for stopping by.
We want to hear from you!
If you’re excited by any of this, or have strong opinions, drop by our Slack channel / leave some comments here! Some resources to help you get started:
📣 join our Hamilton community on Slack — need help with Hamilton? Ask here.
⭐ give Hamilton a star on github
📝 open an issue if you find any bugs/want new features
🌐 read Carl’s follow-up post on enhancing the graphviz view!
We recently launched Burr to create LLM agents and applications
 | A guest post by
|