
Build LLM agents faster with Haystack + Burr!
Learn about Burr's new HaystackAction


With new innovations each week: chatbots, retrieval-augmented generation (RAG), LLM agents, tool usage, multi-agents, multi-modal LLMs, choosing a framework to start building can be a difficult decision.
A few key considerations are:
How efficiently can I test a new idea or build a demo?
Can I reliably move my project to production?
How easy is it to make changes as project requirements evolve?
Haystack and Burr can help you build LLM pipelines and agentic workflows, respectively. In this post, we explore how well they do on these criteria and how you can use them together to build fast and reliably.
Haystack 101: build a pipeline
Haystack is a framework for building data pipelines, especially RAG. You start by creating Components then you assemble them into a Pipeline and run it.
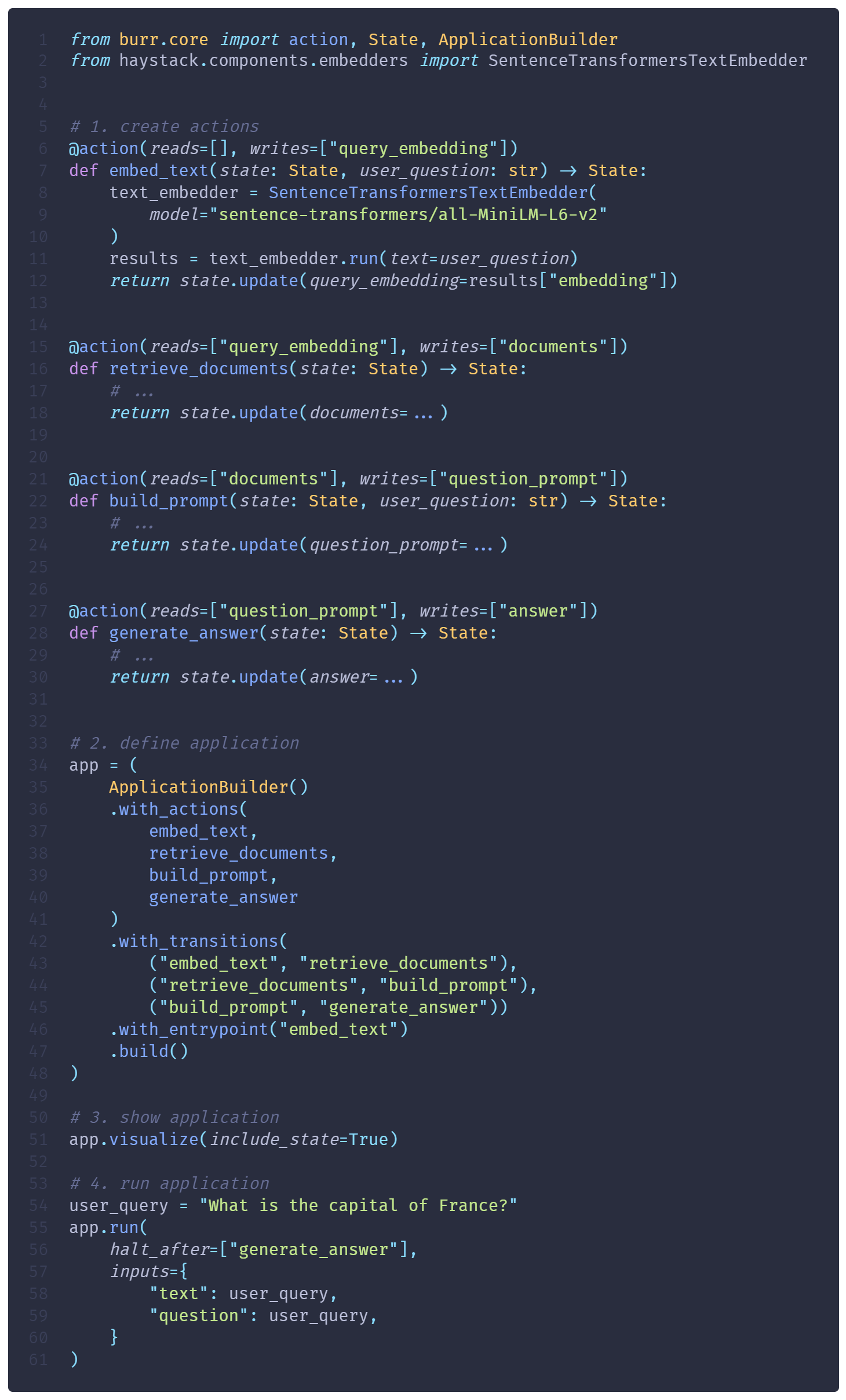
This snippet defines a simple RAG application (adapted from this Haystack tutorial)


Haystack provides a catalog of ready-to-use Component (LLM APIs, vector databases, document processors, data readers, etc.) helps get started quickly. It encourages a “LEGO brick” approach to building pipelines (the example only 40 lines of code) and makes it easy to swap components and try different configurations. Haystack also enables you to define custom components (documentation).
We also maintain Hamilton, a lightweight framework to define pipelines. It is broader than RAG / LLMs, but we have several examples on the topic.
The product WrenAI actually uses both Haystack and Hamilton under the hood!
Burr 101: build an application
Burr is a framework for building applications and agents. It has a similar feel to Haystack, you define Actions (equiv. Component) and transitions between them to form an Application (equiv. Pipeline). We’ll explore their differences next.
The previous RAG pipeline could be recreated entirely in Burr. Burr is flexible as to how you define Actions, you could even use an Haystack Component inside one as shown in embed_text().
Differences between Haystack and Burr
Centralized state
With Haystack, you build a Pipeline by having data flow from a component directly to another. With Burr, your Application has a centralized State, which facilitates writing logic referencing earlier events.
Practically, it means you can always save the State of an application and load it later to resume. If you encounter a bug, can move through previous states to find what went wrong. Then, you can edit State values or modify the Action’s code to fix the issue and resume. Burr also provides utilities to create test cases from failed State to avoid this issue in the future.
Decisions and transitions
To develop an agent capable of complex behaviors, we need to express conditions under which an action should be taken.
Haystack creates pipelines with set entry and exit points. By using, Routers you can implement conditional logic and dispatch data to different components. The ConditionalRouter uses Jinja2 for safety, but limits the expressiveness of routing conditions.
Burr was built specifically for agents, state machines and “decision-making” applications. You can add a Condition on any transition in your Application. The transition can read the State and execute a decision function to determine the next action (documentation).
The next snippet illustrate an agent that searches the web to generate an answer. By adding a when() condition on the transition between verify_citation and search_the_web, we can loop if the generated answer has factual errors (as detected by the verify_citation) action.


Path to production
As a pipeline framework, Haystack can be deployed and orchestrated in various ways. The Hayhooks library allows to serve your Haystack pipeline as an API endpoint. For monitoring, Haystack can generate OpenTelemetry events (note: an Openlemetry destination is required) and offers structured logging.
For Burr, the ApplicationBuilder object allows to instrument your application to meet production needs. Here are some examples:
.with_tracker()log execution and optionally enable OpenTelemetry events, which can be viewed in the open source and local-first Burr UI..with_hooks()allows to add custom logic on action execution (e.g., send a Slack notification).with_typing()use Pydantic to validate theStateand action outputs..with_state_persister()store the State to disk and resume later (e.g., allow a user to resume its session)and more
The following snippet creates an application that will log execution with OpenTelemetry under the burr-rag > demo in the Burr UI and send alerts on Slack when exceptions occur.

The Burr UI allows you to monitor your application in real time and view past application logs created by the tracker and OpenTelemetry. It helps with debugging and provide other insights such as the number of tokens used and the estimated cost. Burr UI also ships with a data annotation tool. This tool is free, open source, and comes with Burr, when you install the appropriate target:
pip install "burr[tracking]"
Haystack + Burr integration
With the new integration, you can merge the catalog of modular components from Haystack and the application-building features of Burr.
While this was possible before, it was verbose. Haystack code needed to be wrapped in a Burr action and the Component inputs/outputs mapped to State. To illustrate, this retrieve_documents() action reads values from State, passes them to Component.run(), and outputs are written back to State:

The new HaystackAction allows you to the same Burr action succinctly. Simply pass the action name, the Haystack Component, and State fields it reads and writes from/to. Your Burr application can mix HaystackAction and regular actions.
Here's the same action as above using the HaystackAction:

Now, you’re able to benefit from Haystack's catalog of components to build Burr applications quickly and reliably. All Burr features become available at almost no additional cost compared to a regular Haystack Pipeline definition. For existing Haystack users, you can fully reuse your custom components for building agents.
What if you already have Haystack pipelines?
You can convert your Haystack Pipeline into a Burr Application in a few lines of code. The function haystack_pipeline_to_burr_graph() converts the pipeline into a Burr Graph that you can use to build the application.
The next snippet converts the pipeline defined at the beginning of this blog:

What if I want to integrate other frameworks?
You can always use your favorite framework (Haystack, Hamilton, LangChain, LlamaIndex, etc.) within a Burr Action. We’re looking forward to add similar integrations to streamline Burr development. Let us know which one to implement next!
As your project evolve, you can swap the Haystack Component used in your HaystackAction, use a custom Haystack Component, or replace the HaystackAction by a regular Burr action with arbitrary Python code. This is a common step as you adjust and upgrade production Burr applications. With Burr you’re not backed into a corner, you’re free to leverage any framework you like as requirements evolve.
Conclusion
On your next project, determine if you’re building a pipeline or an agent and think about your future requirements for production. Haystack and Burr are two complimentary frameworks that can help and their clean integration can provide a lot of value at a low cost. Should you need to customize and extend beyond your initial application, Burr has the constructs and the flexibility so you can iterate with confidence.
We want to hear from you!
If you’re excited by any of this, or have strong opinions:
📣 Join our Discord
⭐️ us on GitHub

